 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVero: An Open RL Recipe for General Visual Reasoning
Apr 07, 2026What does it take to build a visual reasoner that works across charts, science, spatial understanding, and open-ended tasks? The strongest vision-language models (VLMs) show such broad visual reasoning is within reach, but the recipe behind them remains unclear, locked behind proprietary reinforcement learning (RL) pipelines with non-public data. We introduce Vero, a family of fully open VLMs that matches or exceeds existing open-weight models across diverse visual reasoning tasks. We scale RL data and rewards across six broad task categories, constructing Vero-600K, a 600K-sample dataset from 59 datasets, and designing task-routed rewards that handle heterogeneous answer formats. Vero achieves state-of-the-art performance, improving over four base models by 3.6-5.3 points on average across VeroEval, our suite of 30 challenging benchmarks. Starting from Qwen3-VL-8B-Instruct, Vero outperforms Qwen3-VL-8B-Thinking on 23 of 30 benchmarks without additional proprietary thinking data. When trained from the same base model, Vero-600K exceeds existing RL datasets across task categories. Systematic ablations reveal that different task categories elicit qualitatively distinct reasoning patterns that transfer poorly in isolation, suggesting that broad data coverage is the primary driver of strong RL scaling. All data, code, and models are released.
Out of Sight, Not Out of Context? Egocentric Spatial Reasoning in VLMs Across Disjoint Frames
May 30, 2025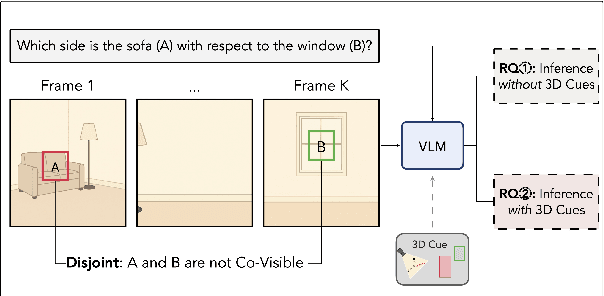

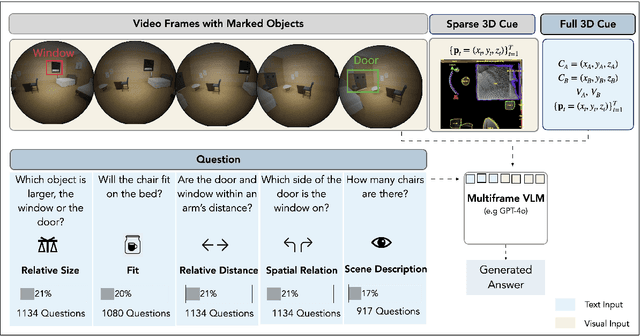

An embodied AI assistant operating on egocentric video must integrate spatial cues across time - for instance, determining where an object A, glimpsed a few moments ago lies relative to an object B encountered later. We introduce Disjoint-3DQA , a generative QA benchmark that evaluates this ability of VLMs by posing questions about object pairs that are not co-visible in the same frame. We evaluated seven state-of-the-art VLMs and found that models lag behind human performance by 28%, with steeper declines in accuracy (60% to 30 %) as the temporal gap widens. Our analysis further reveals that providing trajectories or bird's-eye-view projections to VLMs results in only marginal improvements, whereas providing oracle 3D coordinates leads to a substantial 20% performance increase. This highlights a core bottleneck of multi-frame VLMs in constructing and maintaining 3D scene representations over time from visual signals. Disjoint-3DQA therefore sets a clear, measurable challenge for long-horizon spatial reasoning and aims to catalyze future research at the intersection of vision, language, and embodied AI.
Grounded Reinforcement Learning for Visual Reasoning
May 29, 2025
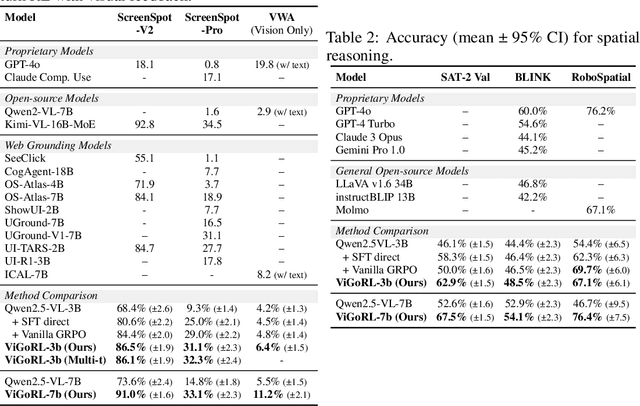
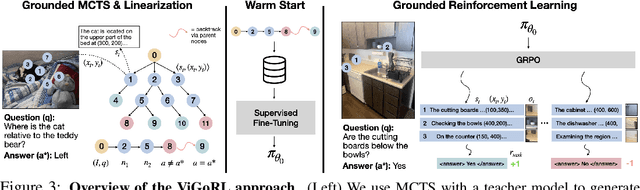

While reinforcement learning (RL) over chains of thought has significantly advanced language models in tasks such as mathematics and coding, visual reasoning introduces added complexity by requiring models to direct visual attention, interpret perceptual inputs, and ground abstract reasoning in spatial evidence. We introduce ViGoRL (Visually Grounded Reinforcement Learning), a vision-language model trained with RL to explicitly anchor each reasoning step to specific visual coordinates. Inspired by human visual decision-making, ViGoRL learns to produce spatially grounded reasoning traces, guiding visual attention to task-relevant regions at each step. When fine-grained exploration is required, our novel multi-turn RL framework enables the model to dynamically zoom into predicted coordinates as reasoning unfolds. Across a diverse set of visual reasoning benchmarks--including SAT-2 and BLINK for spatial reasoning, V*bench for visual search, and ScreenSpot and VisualWebArena for web-based grounding--ViGoRL consistently outperforms both supervised fine-tuning and conventional RL baselines that lack explicit grounding mechanisms. Incorporating multi-turn RL with zoomed-in visual feedback significantly improves ViGoRL's performance on localizing small GUI elements and visual search, achieving 86.4% on V*Bench. Additionally, we find that grounding amplifies other visual behaviors such as region exploration, grounded subgoal setting, and visual verification. Finally, human evaluations show that the model's visual references are not only spatially accurate but also helpful for understanding model reasoning steps. Our results show that visually grounded RL is a strong paradigm for imbuing models with general-purpose visual reasoning.
Grounding Task Assistance with Multimodal Cues from a Single Demonstration
May 02, 2025

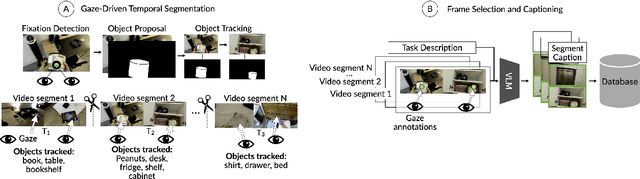
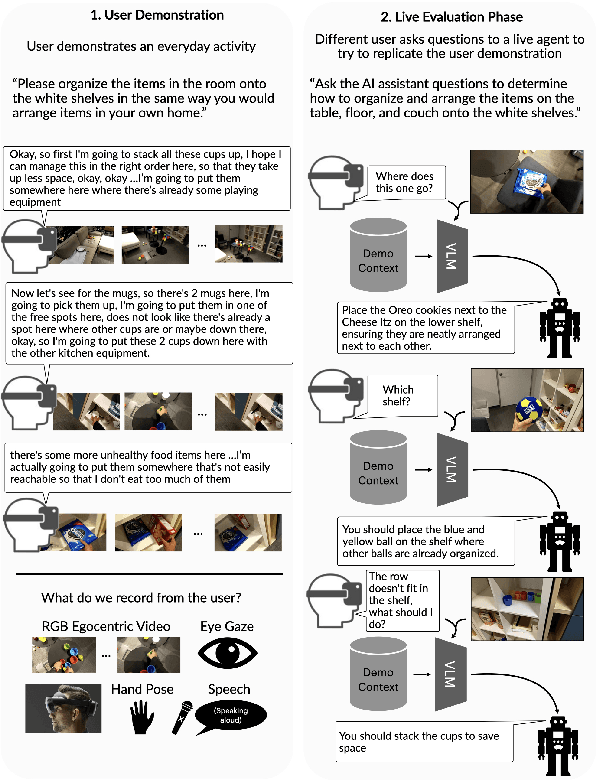
A person's demonstration often serves as a key reference for others learning the same task. However, RGB video, the dominant medium for representing these demonstrations, often fails to capture fine-grained contextual cues such as intent, safety-critical environmental factors, and subtle preferences embedded in human behavior. This sensory gap fundamentally limits the ability of Vision Language Models (VLMs) to reason about why actions occur and how they should adapt to individual users. To address this, we introduce MICA (Multimodal Interactive Contextualized Assistance), a framework that improves conversational agents for task assistance by integrating eye gaze and speech cues. MICA segments demonstrations into meaningful sub-tasks and extracts keyframes and captions that capture fine-grained intent and user-specific cues, enabling richer contextual grounding for visual question answering. Evaluations on questions derived from real-time chat-assisted task replication show that multimodal cues significantly improve response quality over frame-based retrieval. Notably, gaze cues alone achieves 93% of speech performance, and their combination yields the highest accuracy. Task type determines the effectiveness of implicit (gaze) vs. explicit (speech) cues, underscoring the need for adaptable multimodal models. These results highlight the limitations of frame-based context and demonstrate the value of multimodal signals for real-world AI task assistance.
ICAL: Continual Learning of Multimodal Agents by Transforming Trajectories into Actionable Insights
Jun 20, 2024Large-scale generative language and vision-language models (LLMs and VLMs) excel in few-shot in-context learning for decision making and instruction following. However, they require high-quality exemplar demonstrations to be included in their context window. In this work, we ask: Can LLMs and VLMs generate their own prompt examples from generic, sub-optimal demonstrations? We propose In-Context Abstraction Learning (ICAL), a method that builds a memory of multimodal experience insights from sub-optimal demonstrations and human feedback. Given a noisy demonstration in a new domain, VLMs abstract the trajectory into a general program by fixing inefficient actions and annotating cognitive abstractions: task relationships, object state changes, temporal subgoals, and task construals. These abstractions are refined and adapted interactively through human feedback while the agent attempts to execute the trajectory in a similar environment. The resulting abstractions, when used as exemplars in the prompt, significantly improve decision-making in retrieval-augmented LLM and VLM agents. Our ICAL agent surpasses the state-of-the-art in dialogue-based instruction following in TEACh, multimodal web agents in VisualWebArena, and action anticipation in Ego4D. In TEACh, we achieve a 12.6% improvement in goal-condition success. In VisualWebArena, our task success rate improves over the SOTA from 14.3% to 22.7%. In Ego4D action forecasting, we improve over few-shot GPT-4V and remain competitive with supervised models. We show finetuning our retrieval-augmented in-context agent yields additional improvements. Our approach significantly reduces reliance on expert-crafted examples and consistently outperforms in-context learning from action plans that lack such insights.
Neural Representations of Dynamic Visual Stimuli
Jun 04, 2024



Humans experience the world through constantly changing visual stimuli, where scenes can shift and move, change in appearance, and vary in distance. The dynamic nature of visual perception is a fundamental aspect of our daily lives, yet the large majority of research on object and scene processing, particularly using fMRI, has focused on static stimuli. While studies of static image perception are attractive due to their computational simplicity, they impose a strong non-naturalistic constraint on our investigation of human vision. In contrast, dynamic visual stimuli offer a more ecologically-valid approach but present new challenges due to the interplay between spatial and temporal information, making it difficult to disentangle the representations of stable image features and motion. To overcome this limitation -- given dynamic inputs, we explicitly decouple the modeling of static image representations and motion representations in the human brain. Three results demonstrate the feasibility of this approach. First, we show that visual motion information as optical flow can be predicted (or decoded) from brain activity as measured by fMRI. Second, we show that this predicted motion can be used to realistically animate static images using a motion-conditioned video diffusion model (where the motion is driven by fMRI brain activity). Third, we show prediction in the reverse direction: existing video encoders can be fine-tuned to predict fMRI brain activity from video imagery, and can do so more effectively than image encoders. This foundational work offers a novel, extensible framework for interpreting how the human brain processes dynamic visual information.
HELPER-X: A Unified Instructable Embodied Agent to Tackle Four Interactive Vision-Language Domains with Memory-Augmented Language Models
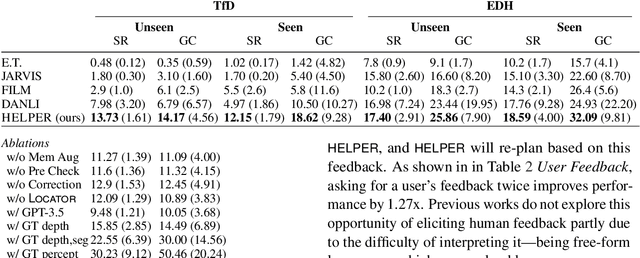
Apr 29, 2024Recent research on instructable agents has used memory-augmented Large Language Models (LLMs) as task planners, a technique that retrieves language-program examples relevant to the input instruction and uses them as in-context examples in the LLM prompt to improve the performance of the LLM in inferring the correct action and task plans. In this technical report, we extend the capabilities of HELPER, by expanding its memory with a wider array of examples and prompts, and by integrating additional APIs for asking questions. This simple expansion of HELPER into a shared memory enables the agent to work across the domains of executing plans from dialogue, natural language instruction following, active question asking, and commonsense room reorganization. We evaluate the agent on four diverse interactive visual-language embodied agent benchmarks: ALFRED, TEACh, DialFRED, and the Tidy Task. HELPER-X achieves few-shot, state-of-the-art performance across these benchmarks using a single agent, without requiring in-domain training, and remains competitive with agents that have undergone in-domain training.
ODIN: A Single Model for 2D and 3D Perception
Jan 04, 2024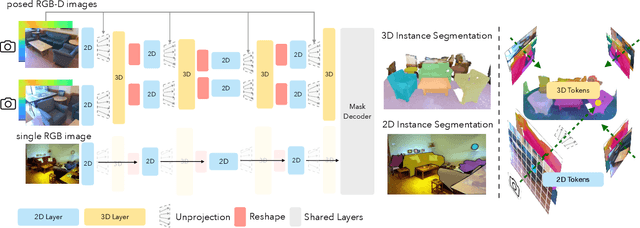
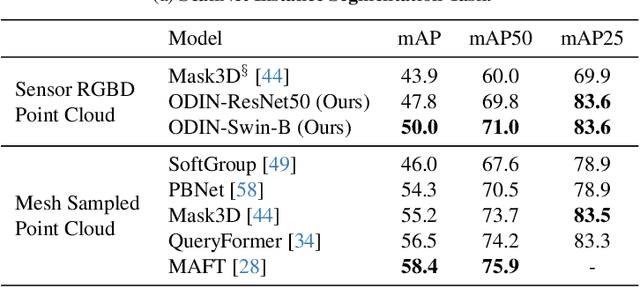
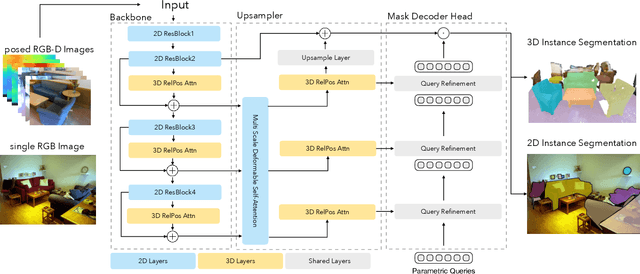
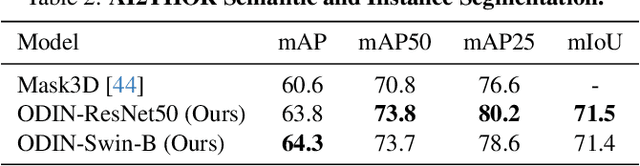
State-of-the-art models on contemporary 3D perception benchmarks like ScanNet consume and label dataset-provided 3D point clouds, obtained through post processing of sensed multiview RGB-D images. They are typically trained in-domain, forego large-scale 2D pre-training and outperform alternatives that featurize the posed RGB-D multiview images instead. The gap in performance between methods that consume posed images versus post-processed 3D point clouds has fueled the belief that 2D and 3D perception require distinct model architectures. In this paper, we challenge this view and propose ODIN (Omni-Dimensional INstance segmentation), a model that can segment and label both 2D RGB images and 3D point clouds, using a transformer architecture that alternates between 2D within-view and 3D cross-view information fusion. Our model differentiates 2D and 3D feature operations through the positional encodings of the tokens involved, which capture pixel coordinates for 2D patch tokens and 3D coordinates for 3D feature tokens. ODIN achieves state-of-the-art performance on ScanNet200, Matterport3D and AI2THOR 3D instance segmentation benchmarks, and competitive performance on ScanNet, S3DIS and COCO. It outperforms all previous works by a wide margin when the sensed 3D point cloud is used in place of the point cloud sampled from 3D mesh. When used as the 3D perception engine in an instructable embodied agent architecture, it sets a new state-of-the-art on the TEACh action-from-dialogue benchmark. Our code and checkpoints can be found at the project website: https://odin-seg.github.io.
Open-Ended Instructable Embodied Agents with Memory-Augmented Large Language Models
Oct 23, 2023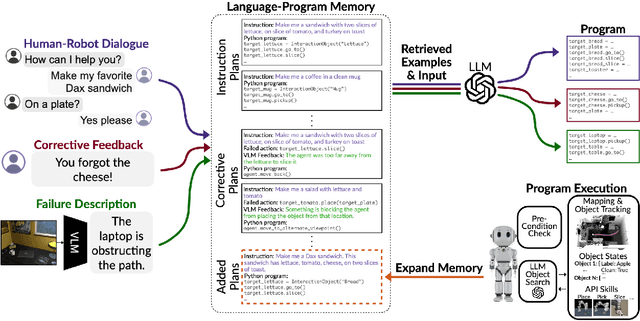
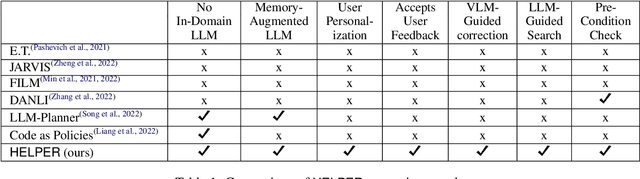
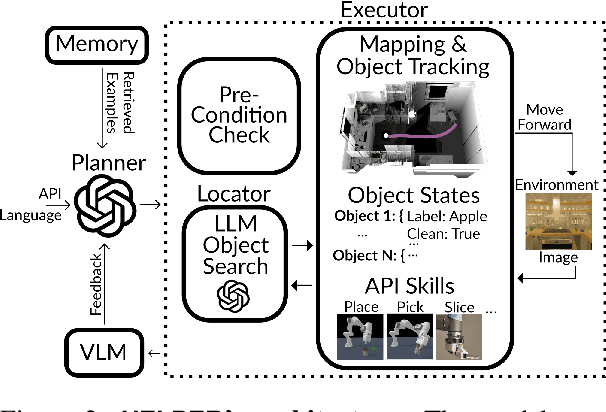
Pre-trained and frozen LLMs can effectively map simple scene re-arrangement instructions to programs over a robot's visuomotor functions through appropriate few-shot example prompting. To parse open-domain natural language and adapt to a user's idiosyncratic procedures, not known during prompt engineering time, fixed prompts fall short. In this paper, we introduce HELPER, an embodied agent equipped with an external memory of language-program pairs that parses free-form human-robot dialogue into action programs through retrieval-augmented LLM prompting: relevant memories are retrieved based on the current dialogue, instruction, correction or VLM description, and used as in-context prompt examples for LLM querying. The memory is expanded during deployment to include pairs of user's language and action plans, to assist future inferences and personalize them to the user's language and routines. HELPER sets a new state-of-the-art in the TEACh benchmark in both Execution from Dialog History (EDH) and Trajectory from Dialogue (TfD), with 1.7x improvement over the previous SOTA for TfD. Our models, code and video results can be found in our project's website: https://helper-agent-llm.github.io.
3D View Prediction Models of the Dorsal Visual Stream
Sep 04, 2023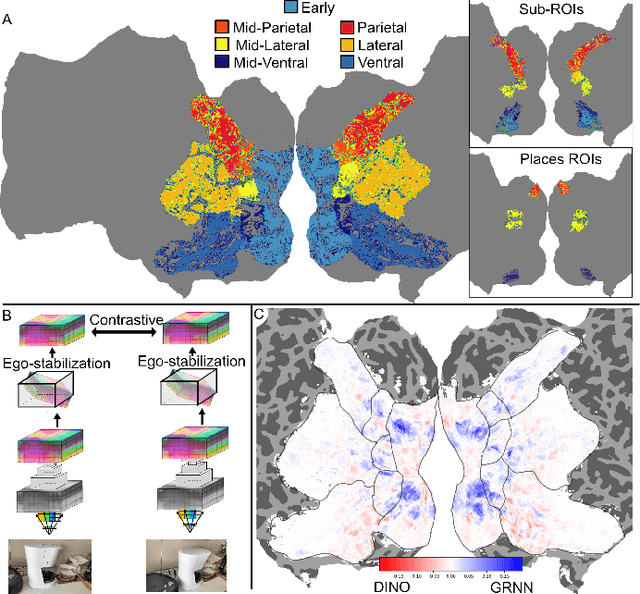
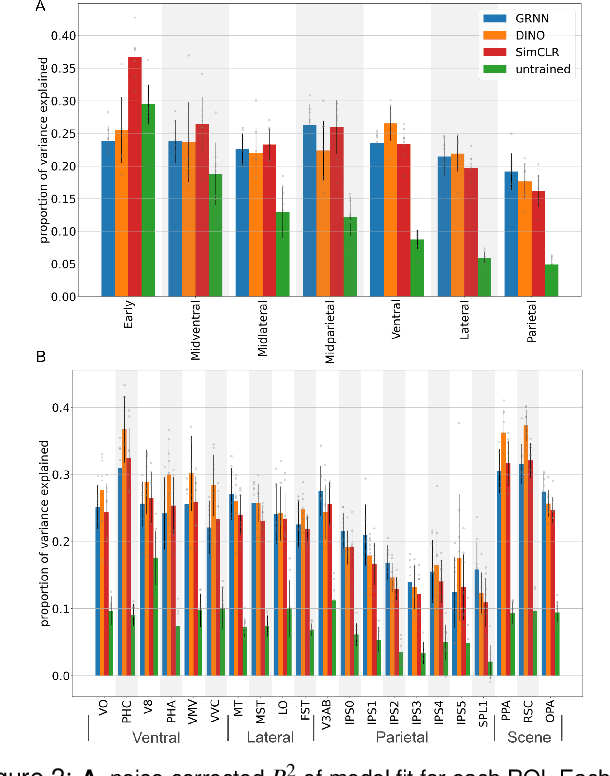
Deep neural network representations align well with brain activity in the ventral visual stream. However, the primate visual system has a distinct dorsal processing stream with different functional properties. To test if a model trained to perceive 3D scene geometry aligns better with neural responses in dorsal visual areas, we trained a self-supervised geometry-aware recurrent neural network (GRNN) to predict novel camera views using a 3D feature memory. We compared GRNN to self-supervised baseline models that have been shown to align well with ventral regions using the large-scale fMRI Natural Scenes Dataset (NSD). We found that while the baseline models accounted better for ventral brain regions, GRNN accounted for a greater proportion of variance in dorsal brain regions. Our findings demonstrate the potential for using task-relevant models to probe representational differences across visual streams.