 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D View Prediction Models of the Dorsal Visual Stream
Paper and Code
Sep 04, 2023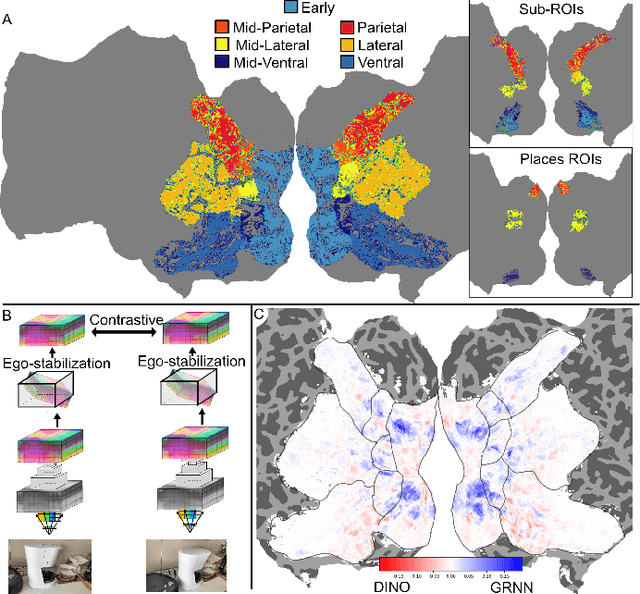
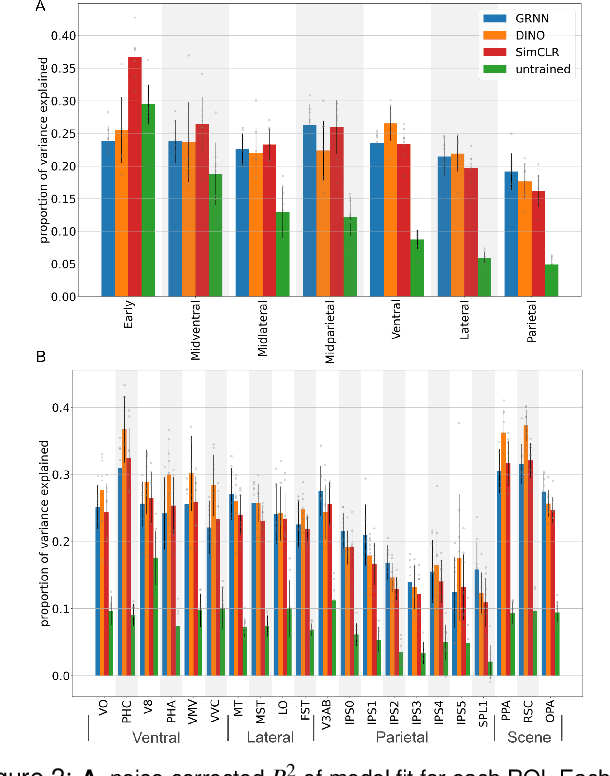
Deep neural network representations align well with brain activity in the ventral visual stream. However, the primate visual system has a distinct dorsal processing stream with different functional properties. To test if a model trained to perceive 3D scene geometry aligns better with neural responses in dorsal visual areas, we trained a self-supervised geometry-aware recurrent neural network (GRNN) to predict novel camera views using a 3D feature memory. We compared GRNN to self-supervised baseline models that have been shown to align well with ventral regions using the large-scale fMRI Natural Scenes Dataset (NSD). We found that while the baseline models accounted better for ventral brain regions, GRNN accounted for a greater proportion of variance in dorsal brain regions. Our findings demonstrate the potential for using task-relevant models to probe representational differences across visual streams.