 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Dec 18, 2024We interact with computers on an everyday basis, be it in everyday life or work, and many aspects of work can be done entirely with access to a computer and the Internet. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. But how performant are AI agents at helping to accelerate or even autonomously perform work-related tasks? The answer to this question has important implications for both industry looking to adopt AI into their workflows, and for economic policy to understand the effects that adoption of AI may have on the labor market. To measure the progress of these LLM agents' performance on performing real-world professional tasks, in this paper, we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that interact with the world in similar ways to those of a digital worker: by browsing the Web, writing code, running programs, and communicating with other coworkers. We build a self-contained environment with internal web sites and data that mimics a small software company environment, and create a variety of tasks that may be performed by workers in such a company. We test baseline agents powered by both closed API-based and open-weights language models (LMs), and find that with the most competitive agent, 24% of the tasks can be completed autonomously. This paints a nuanced picture on task automation with LM agents -- in a setting simulating a real workplace, a good portion of simpler tasks could be solved autonomously, but more difficult long-horizon tasks are still beyond the reach of current systems.
VideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks
Oct 24, 2024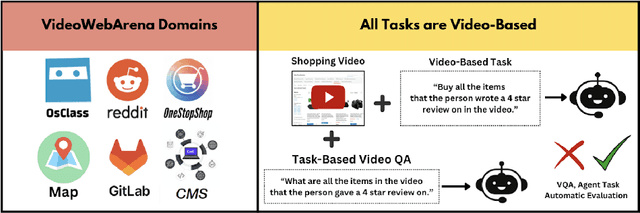
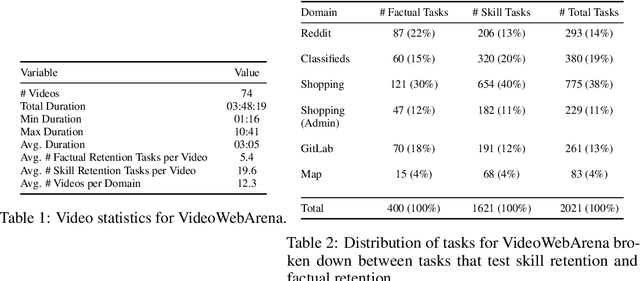
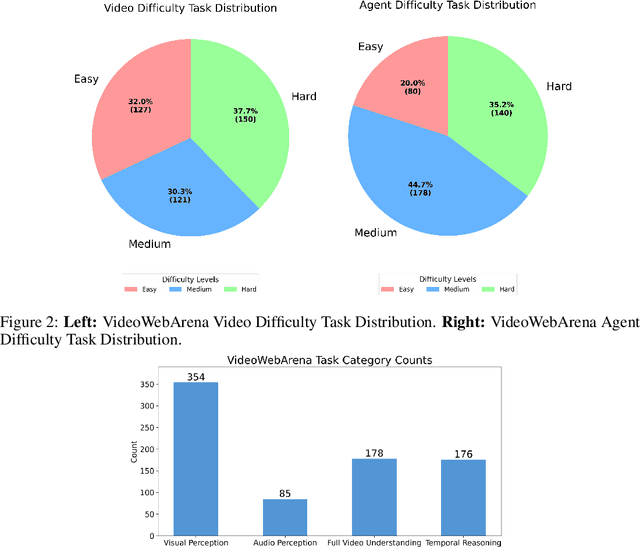
Videos are often used to learn or extract the necessary information to complete tasks in ways different than what text and static imagery alone can provide. However, many existing agent benchmarks neglect long-context video understanding, instead focusing on text or static image inputs. To bridge this gap, we introduce VideoWebArena (VideoWA), a benchmark for evaluating the capabilities of long-context multimodal agents for video understanding. VideoWA consists of 2,021 web agent tasks based on manually crafted video tutorials, which total almost four hours of content. For our benchmark, we define a taxonomy of long-context video-based agent tasks with two main areas of focus: skill retention and factual retention. While skill retention tasks evaluate whether an agent can use a given human demonstration to complete a task efficiently, the factual retention task evaluates whether an agent can retrieve instruction-relevant information from a video to complete a task. We find that the best model achieves 13.3% success on factual retention tasks and 45.8% on factual retention QA pairs, far below human performance at 73.9% and 79.3%, respectively. On skill retention tasks, long-context models perform worse with tutorials than without, exhibiting a 5% performance decrease in WebArena tasks and a 10.3% decrease in VisualWebArena tasks. Our work highlights the need to improve the agentic abilities of long-context multimodal models and provides a testbed for future development with long-context video agents.
Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale
Sep 12, 2024
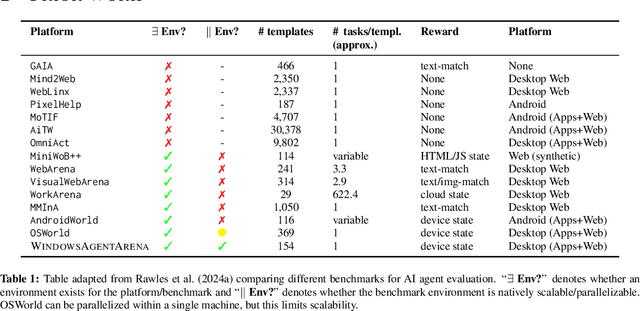

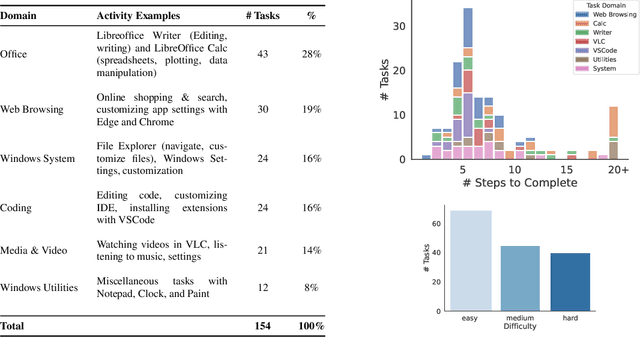
Large language models (LLMs) show remarkable potential to act as computer agents, enhancing human productivity and software accessibility in multi-modal tasks that require planning and reasoning. However, measuring agent performance in realistic environments remains a challenge since: (i) most benchmarks are limited to specific modalities or domains (e.g. text-only, web navigation, Q&A, coding) and (ii) full benchmark evaluations are slow (on order of magnitude of days) given the multi-step sequential nature of tasks. To address these challenges, we introduce the Windows Agent Arena: a reproducible, general environment focusing exclusively on the Windows operating system (OS) where agents can operate freely within a real Windows OS and use the same wide range of applications, tools, and web browsers available to human users when solving tasks. We adapt the OSWorld framework (Xie et al., 2024) to create 150+ diverse Windows tasks across representative domains that require agent abilities in planning, screen understanding, and tool usage. Our benchmark is scalable and can be seamlessly parallelized in Azure for a full benchmark evaluation in as little as 20 minutes. To demonstrate Windows Agent Arena's capabilities, we also introduce a new multi-modal agent, Navi. Our agent achieves a success rate of 19.5% in the Windows domain, compared to 74.5% performance of an unassisted human. Navi also demonstrates strong performance on another popular web-based benchmark, Mind2Web. We offer extensive quantitative and qualitative analysis of Navi's performance, and provide insights into the opportunities for future research in agent development and data generation using Windows Agent Arena. Webpage: https://microsoft.github.io/WindowsAgentArena Code: https://github.com/microsoft/WindowsAgentArena
ICAL: Continual Learning of Multimodal Agents by Transforming Trajectories into Actionable Insights
Jun 20, 2024Large-scale generative language and vision-language models (LLMs and VLMs) excel in few-shot in-context learning for decision making and instruction following. However, they require high-quality exemplar demonstrations to be included in their context window. In this work, we ask: Can LLMs and VLMs generate their own prompt examples from generic, sub-optimal demonstrations? We propose In-Context Abstraction Learning (ICAL), a method that builds a memory of multimodal experience insights from sub-optimal demonstrations and human feedback. Given a noisy demonstration in a new domain, VLMs abstract the trajectory into a general program by fixing inefficient actions and annotating cognitive abstractions: task relationships, object state changes, temporal subgoals, and task construals. These abstractions are refined and adapted interactively through human feedback while the agent attempts to execute the trajectory in a similar environment. The resulting abstractions, when used as exemplars in the prompt, significantly improve decision-making in retrieval-augmented LLM and VLM agents. Our ICAL agent surpasses the state-of-the-art in dialogue-based instruction following in TEACh, multimodal web agents in VisualWebArena, and action anticipation in Ego4D. In TEACh, we achieve a 12.6% improvement in goal-condition success. In VisualWebArena, our task success rate improves over the SOTA from 14.3% to 22.7%. In Ego4D action forecasting, we improve over few-shot GPT-4V and remain competitive with supervised models. We show finetuning our retrieval-augmented in-context agent yields additional improvements. Our approach significantly reduces reliance on expert-crafted examples and consistently outperforms in-context learning from action plans that lack such insights.
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Jan 24, 2024



Autonomous agents capable of planning, reasoning, and executing actions on the web offer a promising avenue for automating computer tasks. However, the majority of existing benchmarks primarily focus on text-based agents, neglecting many natural tasks that require visual information to effectively solve. Given that most computer interfaces cater to human perception, visual information often augments textual data in ways that text-only models struggle to harness effectively. To bridge this gap, we introduce VisualWebArena, a benchmark designed to assess the performance of multimodal web agents on realistic \textit{visually grounded tasks}. VisualWebArena comprises of a set of diverse and complex web-based tasks that evaluate various capabilities of autonomous multimodal agents. To perform on this benchmark, agents need to accurately process image-text inputs, interpret natural language instructions, and execute actions on websites to accomplish user-defined objectives. We conduct an extensive evaluation of state-of-the-art LLM-based autonomous agents, including several multimodal models. Through extensive quantitative and qualitative analysis, we identify several limitations of text-only LLM agents, and reveal gaps in the capabilities of state-of-the-art multimodal language agents. VisualWebArena provides a framework for evaluating multimodal autonomous language agents, and offers insights towards building stronger autonomous agents for the web. Our code, baseline models, and data is publicly available at https://jykoh.com/vwa.