 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHystar: Hypernetwork-driven Style-adaptive Retrieval via Dynamic SVD Modulation
May 11, 2026Query-based image retrieval (QBIR) requires retrieving relevant images given diverse and often stylistically heterogeneous queries, such as sketches, artworks, or low-resolution previews. While large-scale vision--language representation models (VLRMs) like CLIP offer strong zero-shot retrieval performance, they struggle with distribution shifts caused by unseen query styles. In this paper, we propose the Hypernetwork-driven Style-adaptive Retrieval (Hystar), a lightweight framework that dynamically adapts model weights to each query's style. Hystar employs a hypernetwork to generate singular-value perturbations ($ΔS$) for attention layers, enabling flexible per-input adaptation, while static singular-value offsets on MLP layers ensure cross-style stability. To better handle semantic confusions across styles, we design StyleNCE as part of Hystar, an optimal-transport-weighted contrastive loss that emphasizes hard cross-style negatives. Extensive experiments on multi-style retrieval and cross-style classification benchmarks demonstrate that Hystar consistently outperforms strong baselines, achieving state-of-the-art performance while being parameter-efficient and stable across styles.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Enhancing Contrastive Learning for Retinal Imaging via Adjusted Augmentation Scales
Jan 05, 2025



Contrastive learning, a prominent approach within self-supervised learning, has demonstrated significant effectiveness in developing generalizable models for various applications involving natural images. However, recent research indicates that these successes do not necessarily extend to the medical imaging domain. In this paper, we investigate the reasons for this suboptimal performance and hypothesize that the dense distribution of medical images poses challenges to the pretext tasks in contrastive learning, particularly in constructing positive and negative pairs. We explore model performance under different augmentation strategies and compare the results to those achieved with strong augmentations. Our study includes six publicly available datasets covering multiple clinically relevant tasks. We further assess the model's generalizability through external evaluations. The model pre-trained with weak augmentation outperforms those with strong augmentation, improving AUROC from 0.838 to 0.848 and AUPR from 0.523 to 0.597 on MESSIDOR2, and showing similar enhancements across other datasets. Our findings suggest that optimizing the scale of augmentation is critical for enhancing the efficacy of contrastive learning in medical imaging.
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Dec 18, 2024We interact with computers on an everyday basis, be it in everyday life or work, and many aspects of work can be done entirely with access to a computer and the Internet. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. But how performant are AI agents at helping to accelerate or even autonomously perform work-related tasks? The answer to this question has important implications for both industry looking to adopt AI into their workflows, and for economic policy to understand the effects that adoption of AI may have on the labor market. To measure the progress of these LLM agents' performance on performing real-world professional tasks, in this paper, we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that interact with the world in similar ways to those of a digital worker: by browsing the Web, writing code, running programs, and communicating with other coworkers. We build a self-contained environment with internal web sites and data that mimics a small software company environment, and create a variety of tasks that may be performed by workers in such a company. We test baseline agents powered by both closed API-based and open-weights language models (LMs), and find that with the most competitive agent, 24% of the tasks can be completed autonomously. This paints a nuanced picture on task automation with LM agents -- in a setting simulating a real workplace, a good portion of simpler tasks could be solved autonomously, but more difficult long-horizon tasks are still beyond the reach of current systems.
OpenDevin: An Open Platform for AI Software Developers as Generalist Agents
Jul 23, 2024



Software is one of the most powerful tools that we humans have at our disposal; it allows a skilled programmer to interact with the world in complex and profound ways. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. In this paper, we introduce OpenDevin, a platform for the development of powerful and flexible AI agents that interact with the world in similar ways to those of a human developer: by writing code, interacting with a command line, and browsing the web. We describe how the platform allows for the implementation of new agents, safe interaction with sandboxed environments for code execution, coordination between multiple agents, and incorporation of evaluation benchmarks. Based on our currently incorporated benchmarks, we perform an evaluation of agents over 15 challenging tasks, including software engineering (e.g., SWE-Bench) and web browsing (e.g., WebArena), among others. Released under the permissive MIT license, OpenDevin is a community project spanning academia and industry with more than 1.3K contributions from over 160 contributors and will improve going forward.
GUI Odyssey: A Comprehensive Dataset for Cross-App GUI Navigation on Mobile Devices
Jun 12, 2024


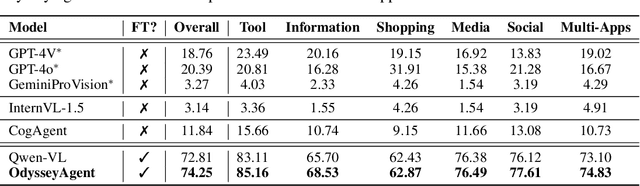
Smartphone users often navigate across multiple applications (apps) to complete tasks such as sharing content between social media platforms. Autonomous Graphical User Interface (GUI) navigation agents can enhance user experience in communication, entertainment, and productivity by streamlining workflows and reducing manual intervention. However, prior GUI agents often trained with datasets comprising simple tasks that can be completed within a single app, leading to poor performance in cross-app navigation. To address this problem, we introduce GUI Odyssey, a comprehensive dataset for training and evaluating cross-app navigation agents. GUI Odyssey consists of 7,735 episodes from 6 mobile devices, spanning 6 types of cross-app tasks, 201 apps, and 1.4K app combos. Leveraging GUI Odyssey, we developed OdysseyAgent, a multimodal cross-app navigation agent by fine-tuning the Qwen-VL model with a history resampling module. Extensive experiments demonstrate OdysseyAgent's superior accuracy compared to existing models. For instance, OdysseyAgent surpasses fine-tuned Qwen-VL and zero-shot GPT-4V by 1.44\% and 55.49\% in-domain accuracy, and 2.29\% and 48.14\% out-of-domain accuracy on average. The dataset and code will be released in \url{https://github.com/OpenGVLab/GUI-Odyssey}.
FasterRisk: Fast and Accurate Interpretable Risk Scores
Oct 12, 2022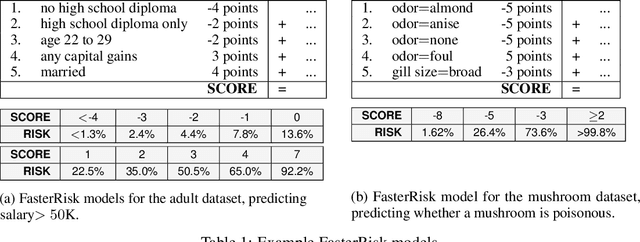
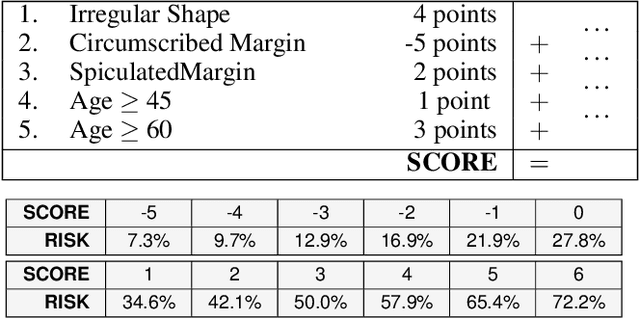
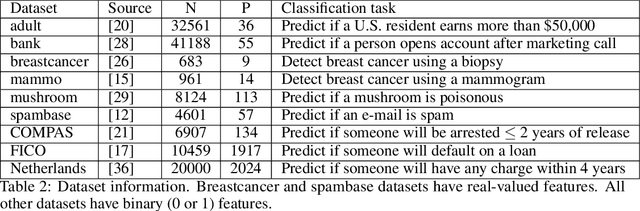
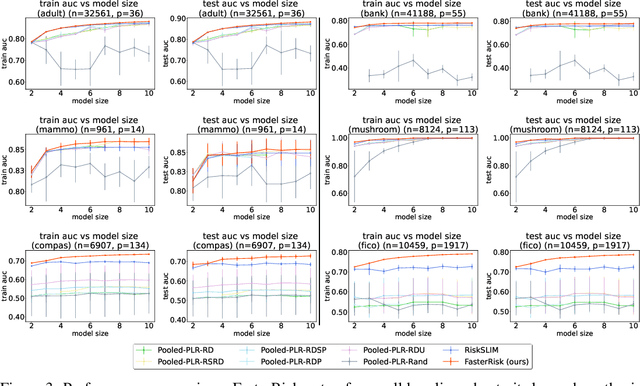
Over the last century, risk scores have been the most popular form of predictive model used in healthcare and criminal justice. Risk scores are sparse linear models with integer coefficients; often these models can be memorized or placed on an index card. Typically, risk scores have been created either without data or by rounding logistic regression coefficients, but these methods do not reliably produce high-quality risk scores. Recent work used mathematical programming, which is computationally slow. We introduce an approach for efficiently producing a collection of high-quality risk scores learned from data. Specifically, our approach produces a pool of almost-optimal sparse continuous solutions, each with a different support set, using a beam-search algorithm. Each of these continuous solutions is transformed into a separate risk score through a "star ray" search, where a range of multipliers are considered before rounding the coefficients sequentially to maintain low logistic loss. Our algorithm returns all of these high-quality risk scores for the user to consider. This method completes within minutes and can be valuable in a broad variety of applications.