 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-friendly and Linearly Convergent First-order Methods for Certifying Optimal $k$-sparse GLMs
Mar 01, 2026We investigate the problem of certifying optimality for sparse generalized linear models (GLMs), where sparsity is enforced through a cardinality constraint. While Branch-and-Bound (BnB) frameworks can certify optimality using perspective relaxations, existing methods for solving these relaxations are computationally intensive, limiting their scalability. To address this challenge, we reformulate the relaxations as composite optimization problems and develop a unified proximal framework that is both linearly convergent and computationally efficient. Under specific geometric regularity conditions, our analysis links primal quadratic growth to dual quadratic decay, yielding error bounds that make the Fenchel duality gap a sharp proxy for progress towards the solution set. This leads to a duality gap-based restart scheme that upgrades a broad class of sublinear proximal methods to provably linearly convergent methods, and applies beyond the sparse GLM setting. For the implicit perspective regularizer, we further derive specialized routines to evaluate the regularizer and its proximal operator exactly in log-linear time, avoiding costly generic conic solvers. The resulting iterations are dominated by matrix--vector multiplications, which enables GPU acceleration. Experiments on synthetic and real-world datasets show orders-of-magnitude faster dual-bound computations and substantially improved BnB scalability on large instances.
Scalable First-order Method for Certifying Optimal k-Sparse GLMs
Feb 13, 2025This paper investigates the problem of certifying optimality for sparse generalized linear models (GLMs), where sparsity is enforced through an $\ell_0$ cardinality constraint. While branch-and-bound (BnB) frameworks can certify optimality by pruning nodes using dual bounds, existing methods for computing these bounds are either computationally intensive or exhibit slow convergence, limiting their scalability to large-scale problems. To address this challenge, we propose a first-order proximal gradient algorithm designed to solve the perspective relaxation of the problem within a BnB framework. Specifically, we formulate the relaxed problem as a composite optimization problem and demonstrate that the proximal operator of the non-smooth component can be computed exactly in log-linear time complexity, eliminating the need to solve a computationally expensive second-order cone program. Furthermore, we introduce a simple restart strategy that enhances convergence speed while maintaining low per-iteration complexity. Extensive experiments on synthetic and real-world datasets show that our approach significantly accelerates dual bound computations and is highly effective in providing optimality certificates for large-scale problems.
FastSurvival: Hidden Computational Blessings in Training Cox Proportional Hazards Models
Oct 24, 2024
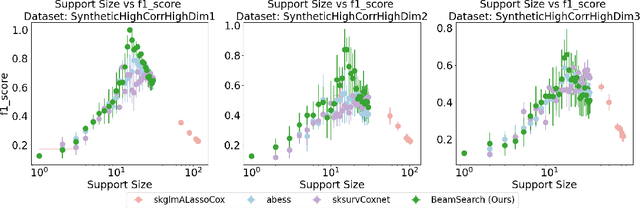
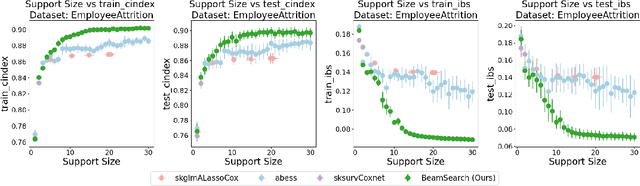
Survival analysis is an important research topic with applications in healthcare, business, and manufacturing. One essential tool in this area is the Cox proportional hazards (CPH) model, which is widely used for its interpretability, flexibility, and predictive performance. However, for modern data science challenges such as high dimensionality (both $n$ and $p$) and high feature correlations, current algorithms to train the CPH model have drawbacks, preventing us from using the CPH model at its full potential. The root cause is that the current algorithms, based on the Newton method, have trouble converging due to vanishing second order derivatives when outside the local region of the minimizer. To circumvent this problem, we propose new optimization methods by constructing and minimizing surrogate functions that exploit hidden mathematical structures of the CPH model. Our new methods are easy to implement and ensure monotonic loss decrease and global convergence. Empirically, we verify the computational efficiency of our methods. As a direct application, we show how our optimization methods can be used to solve the cardinality-constrained CPH problem, producing very sparse high-quality models that were not previously practical to construct. We list several extensions that our breakthrough enables, including optimization opportunities, theoretical questions on CPH's mathematical structure, as well as other CPH-related applications.
Amazing Things Come From Having Many Good Models
Jul 10, 2024



The Rashomon Effect, coined by Leo Breiman, describes the phenomenon that there exist many equally good predictive models for the same dataset. This phenomenon happens for many real datasets and when it does, it sparks both magic and consternation, but mostly magic. In light of the Rashomon Effect, this perspective piece proposes reshaping the way we think about machine learning, particularly for tabular data problems in the nondeterministic (noisy) setting. We address how the Rashomon Effect impacts (1) the existence of simple-yet-accurate models, (2) flexibility to address user preferences, such as fairness and monotonicity, without losing performance, (3) uncertainty in predictions, fairness, and explanations, (4) reliable variable importance, (5) algorithm choice, specifically, providing advanced knowledge of which algorithms might be suitable for a given problem, and (6) public policy. We also discuss a theory of when the Rashomon Effect occurs and why. Our goal is to illustrate how the Rashomon Effect can have a massive impact on the use of machine learning for complex problems in society.
Fast and Interpretable Mortality Risk Scores for Critical Care Patients
Nov 21, 2023



Prediction of mortality in intensive care unit (ICU) patients is an important task in critical care medicine. Prior work in creating mortality risk models falls into two major categories: domain-expert-created scoring systems, and black box machine learning (ML) models. Both of these have disadvantages: black box models are unacceptable for use in hospitals, whereas manual creation of models (including hand-tuning of logistic regression parameters) relies on humans to perform high-dimensional constrained optimization, which leads to a loss in performance. In this work, we bridge the gap between accurate black box models and hand-tuned interpretable models. We build on modern interpretable ML techniques to design accurate and interpretable mortality risk scores. We leverage the largest existing public ICU monitoring datasets, namely the MIMIC III and eICU datasets. By evaluating risk across medical centers, we are able to study generalization across domains. In order to customize our risk score models, we develop a new algorithm, GroupFasterRisk, which has several important benefits: (1) it uses hard sparsity constraint, allowing users to directly control the number of features; (2) it incorporates group sparsity to allow more cohesive models; (3) it allows for monotonicity correction on models for including domain knowledge; (4) it produces many equally-good models at once, which allows domain experts to choose among them. GroupFasterRisk creates its risk scores within hours, even on the large datasets we study here. GroupFasterRisk's risk scores perform better than risk scores currently used in hospitals, and have similar prediction performance to black box ML models (despite being much sparser). Because GroupFasterRisk produces a variety of risk scores and handles constraints, it allows design flexibility, which is the key enabler of practical and trustworthy model creation.
Syntax Tree Constrained Graph Network for Visual Question Answering
Sep 17, 2023



Visual Question Answering (VQA) aims to automatically answer natural language questions related to given image content. Existing VQA methods integrate vision modeling and language understanding to explore the deep semantics of the question. However, these methods ignore the significant syntax information of the question, which plays a vital role in understanding the essential semantics of the question and guiding the visual feature refinement. To fill the gap, we suggested a novel Syntax Tree Constrained Graph Network (STCGN) for VQA based on entity message passing and syntax tree. This model is able to extract a syntax tree from questions and obtain more precise syntax information. Specifically, we parse questions and obtain the question syntax tree using the Stanford syntax parsing tool. From the word level and phrase level, syntactic phrase features and question features are extracted using a hierarchical tree convolutional network. We then design a message-passing mechanism for phrase-aware visual entities and capture entity features according to a given visual context. Extensive experiments on VQA2.0 datasets demonstrate the superiority of our proposed model.
Causal Intervention for Abstractive Related Work Generation
May 23, 2023



Abstractive related work generation has attracted increasing attention in generating coherent related work that better helps readers grasp the background in the current research. However, most existing abstractive models ignore the inherent causality of related work generation, leading to low quality of generated related work and spurious correlations that affect the models' generalizability. In this study, we argue that causal intervention can address these limitations and improve the quality and coherence of the generated related works. To this end, we propose a novel Causal Intervention Module for Related Work Generation (CaM) to effectively capture causalities in the generation process and improve the quality and coherence of the generated related works. Specifically, we first model the relations among sentence order, document relation, and transitional content in related work generation using a causal graph. Then, to implement the causal intervention and mitigate the negative impact of spurious correlations, we use do-calculus to derive ordinary conditional probabilities and identify causal effects through CaM. Finally, we subtly fuse CaM with Transformer to obtain an end-to-end generation model. Extensive experiments on two real-world datasets show that causal interventions in CaM can effectively promote the model to learn causal relations and produce related work of higher quality and coherence.
OKRidge: Scalable Optimal k-Sparse Ridge Regression for Learning Dynamical Systems
Apr 13, 2023



We consider an important problem in scientific discovery, identifying sparse governing equations for nonlinear dynamical systems. This involves solving sparse ridge regression problems to provable optimality in order to determine which terms drive the underlying dynamics. We propose a fast algorithm, OKRidge, for sparse ridge regression, using a novel lower bound calculation involving, first, a saddle point formulation, and from there, either solving (i) a linear system or (ii) using an ADMM-based approach, where the proximal operators can be efficiently evaluated by solving another linear system and an isotonic regression problem. We also propose a method to warm-start our solver, which leverages a beam search. Experimentally, our methods attain provable optimality with run times that are orders of magnitude faster than those of the existing MIP formulations solved by the commercial solver Gurobi.
FasterRisk: Fast and Accurate Interpretable Risk Scores
Oct 12, 2022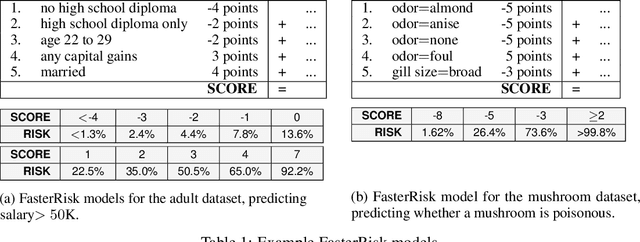
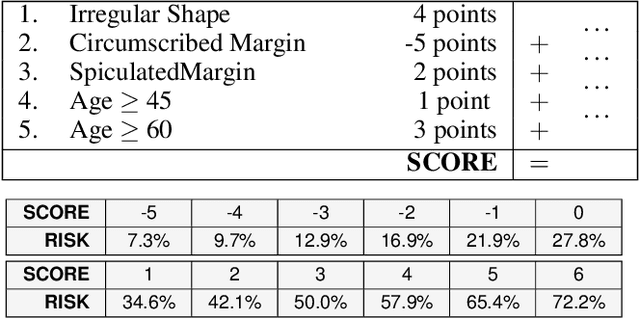
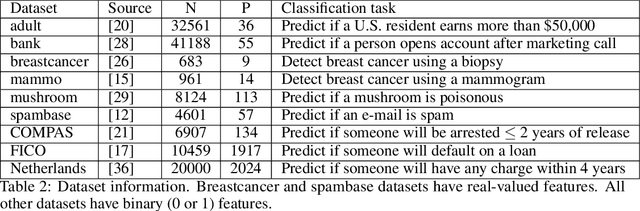
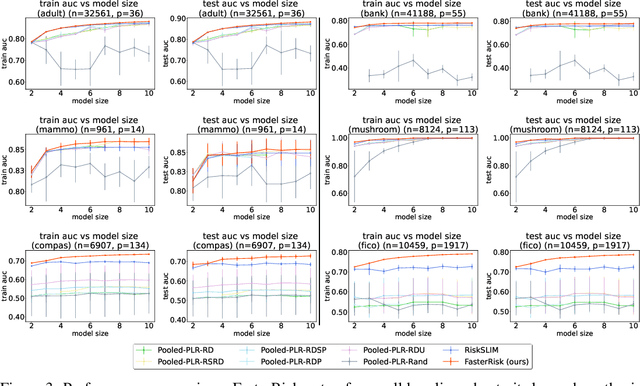
Over the last century, risk scores have been the most popular form of predictive model used in healthcare and criminal justice. Risk scores are sparse linear models with integer coefficients; often these models can be memorized or placed on an index card. Typically, risk scores have been created either without data or by rounding logistic regression coefficients, but these methods do not reliably produce high-quality risk scores. Recent work used mathematical programming, which is computationally slow. We introduce an approach for efficiently producing a collection of high-quality risk scores learned from data. Specifically, our approach produces a pool of almost-optimal sparse continuous solutions, each with a different support set, using a beam-search algorithm. Each of these continuous solutions is transformed into a separate risk score through a "star ray" search, where a range of multipliers are considered before rounding the coefficients sequentially to maintain low logistic loss. Our algorithm returns all of these high-quality risk scores for the user to consider. This method completes within minutes and can be valuable in a broad variety of applications.
Fast Sparse Classification for Generalized Linear and Additive Models
Feb 23, 2022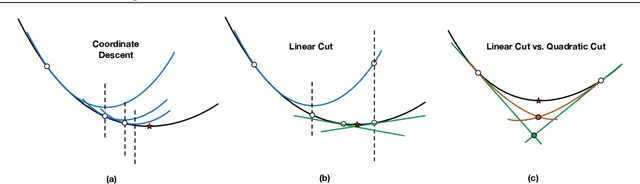


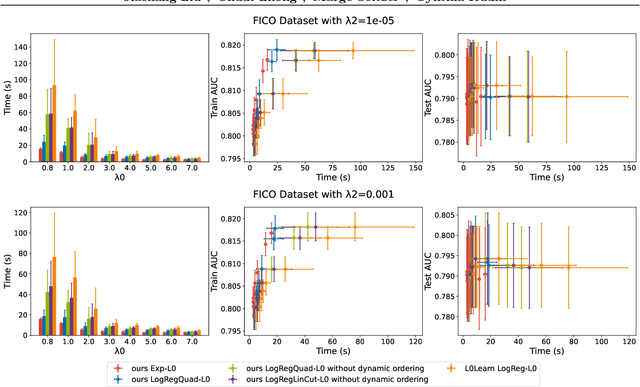
We present fast classification techniques for sparse generalized linear and additive models. These techniques can handle thousands of features and thousands of observations in minutes, even in the presence of many highly correlated features. For fast sparse logistic regression, our computational speed-up over other best-subset search techniques owes to linear and quadratic surrogate cuts for the logistic loss that allow us to efficiently screen features for elimination, as well as use of a priority queue that favors a more uniform exploration of features. As an alternative to the logistic loss, we propose the exponential loss, which permits an analytical solution to the line search at each iteration. Our algorithms are generally 2 to 5 times faster than previous approaches. They produce interpretable models that have accuracy comparable to black box models on challenging datasets.