 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoctor Rashomon and the UNIVERSE of Madness: Variable Importance with Unobserved Confounding and the Rashomon Effect
Oct 14, 2025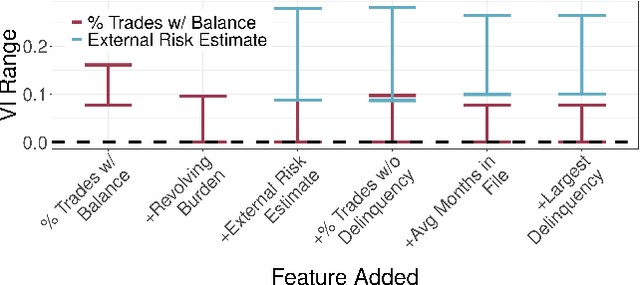
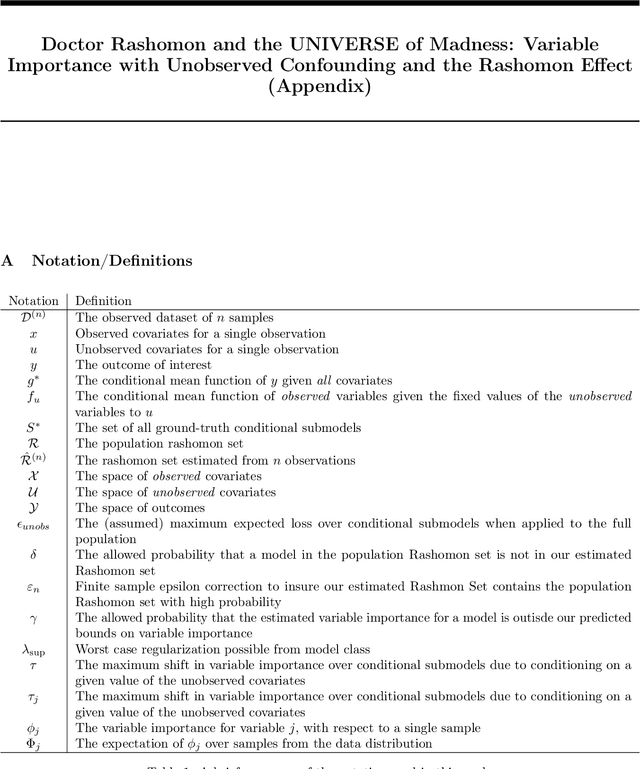
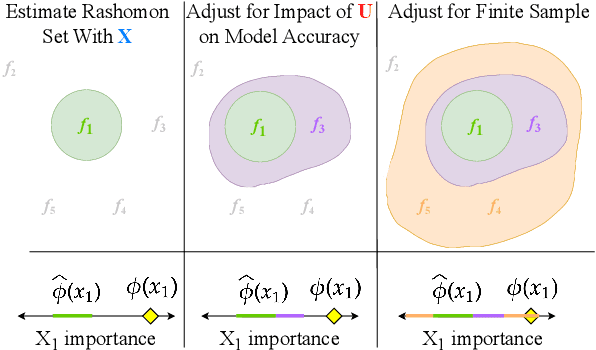
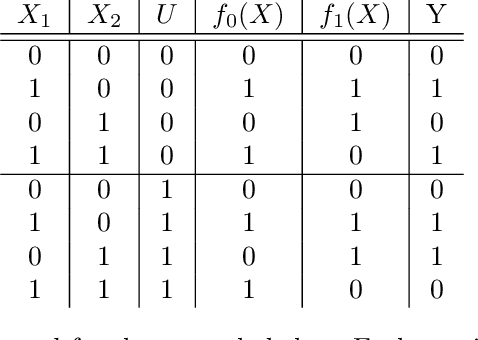
Variable importance (VI) methods are often used for hypothesis generation, feature selection, and scientific validation. In the standard VI pipeline, an analyst estimates VI for a single predictive model with only the observed features. However, the importance of a feature depends heavily on which other variables are included in the model, and essential variables are often omitted from observational datasets. Moreover, the VI estimated for one model is often not the same as the VI estimated for another equally-good model - a phenomenon known as the Rashomon Effect. We address these gaps by introducing UNobservables and Inference for Variable importancE using Rashomon SEts (UNIVERSE). Our approach adapts Rashomon sets - the sets of near-optimal models in a dataset - to produce bounds on the true VI even with missing features. We theoretically guarantee the robustness of our approach, show strong performance on semi-synthetic simulations, and demonstrate its utility in a credit risk task.
Amazing Things Come From Having Many Good Models
Jul 10, 2024



The Rashomon Effect, coined by Leo Breiman, describes the phenomenon that there exist many equally good predictive models for the same dataset. This phenomenon happens for many real datasets and when it does, it sparks both magic and consternation, but mostly magic. In light of the Rashomon Effect, this perspective piece proposes reshaping the way we think about machine learning, particularly for tabular data problems in the nondeterministic (noisy) setting. We address how the Rashomon Effect impacts (1) the existence of simple-yet-accurate models, (2) flexibility to address user preferences, such as fairness and monotonicity, without losing performance, (3) uncertainty in predictions, fairness, and explanations, (4) reliable variable importance, (5) algorithm choice, specifically, providing advanced knowledge of which algorithms might be suitable for a given problem, and (6) public policy. We also discuss a theory of when the Rashomon Effect occurs and why. Our goal is to illustrate how the Rashomon Effect can have a massive impact on the use of machine learning for complex problems in society.
Interpretable Causal Inference for Analyzing Wearable, Sensor, and Distributional Data
Dec 17, 2023Many modern causal questions ask how treatments affect complex outcomes that are measured using wearable devices and sensors. Current analysis approaches require summarizing these data into scalar statistics (e.g., the mean), but these summaries can be misleading. For example, disparate distributions can have the same means, variances, and other statistics. Researchers can overcome the loss of information by instead representing the data as distributions. We develop an interpretable method for distributional data analysis that ensures trustworthy and robust decision-making: Analyzing Distributional Data via Matching After Learning to Stretch (ADD MALTS). We (i) provide analytical guarantees of the correctness of our estimation strategy, (ii) demonstrate via simulation that ADD MALTS outperforms other distributional data analysis methods at estimating treatment effects, and (iii) illustrate ADD MALTS' ability to verify whether there is enough cohesion between treatment and control units within subpopulations to trustworthily estimate treatment effects. We demonstrate ADD MALTS' utility by studying the effectiveness of continuous glucose monitors in mitigating diabetes risks.
The Rashomon Importance Distribution: Getting RID of Unstable, Single Model-based Variable Importance
Sep 26, 2023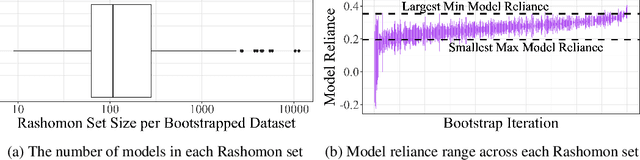

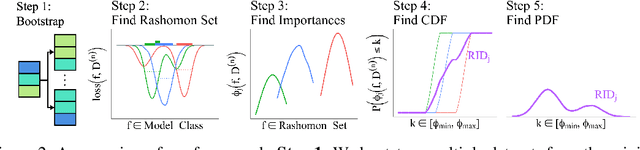
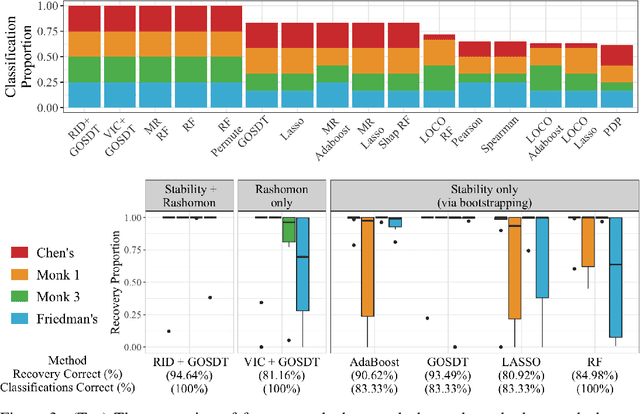
Quantifying variable importance is essential for answering high-stakes questions in fields like genetics, public policy, and medicine. Current methods generally calculate variable importance for a given model trained on a given dataset. However, for a given dataset, there may be many models that explain the target outcome equally well; without accounting for all possible explanations, different researchers may arrive at many conflicting yet equally valid conclusions given the same data. Additionally, even when accounting for all possible explanations for a given dataset, these insights may not generalize because not all good explanations are stable across reasonable data perturbations. We propose a new variable importance framework that quantifies the importance of a variable across the set of all good models and is stable across the data distribution. Our framework is extremely flexible and can be integrated with most existing model classes and global variable importance metrics. We demonstrate through experiments that our framework recovers variable importance rankings for complex simulation setups where other methods fail. Further, we show that our framework accurately estimates the true importance of a variable for the underlying data distribution. We provide theoretical guarantees on the consistency and finite sample error rates for our estimator. Finally, we demonstrate its utility with a real-world case study exploring which genes are important for predicting HIV load in persons with HIV, highlighting an important gene that has not previously been studied in connection with HIV. Code is available here.