 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVWorld: Foundations for Remote-Control TV Agents
Jan 19, 2026Recent large vision-language models (LVLMs) have demonstrated strong potential for device control. However, existing research has primarily focused on point-and-click (PnC) interaction, while remote-control (RC) interaction commonly encountered in everyday TV usage remains largely underexplored. To fill this gap, we introduce \textbf{TVWorld}, an offline graph-based abstraction of real-world TV navigation that enables reproducible and deployment-free evaluation. On this basis, we derive two complementary benchmarks that comprehensively assess TV-use capabilities: \textbf{TVWorld-N} for topology-aware navigation and \textbf{TVWorld-G} for focus-aware grounding. These benchmarks expose a key limitation of existing agents: insufficient topology awareness for focus-based, long-horizon TV navigation. Motivated by this finding, we propose a \emph{Topology-Aware Training} framework that injects topology awareness into LVLMs. Using this framework, we develop \textbf{TVTheseus}, a foundation model specialized for TV navigation. TVTheseus achieves a success rate of $68.3\%$ on TVWorld-N, surpassing strong closed-source baselines such as Gemini 3 Flash and establishing state-of-the-art (SOTA) performance. Additional analyses further provide valuable insights into the development of effective TV-use agents.
SWIRL: A Staged Workflow for Interleaved Reinforcement Learning in Mobile GUI Control
Aug 27, 2025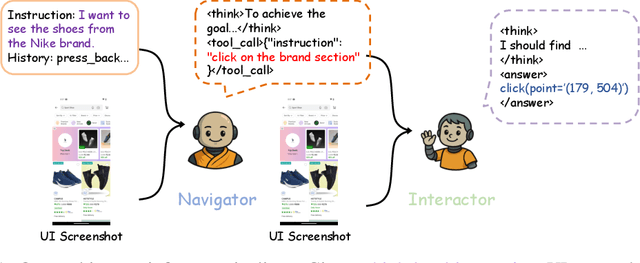
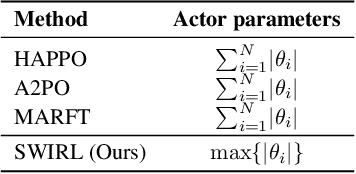
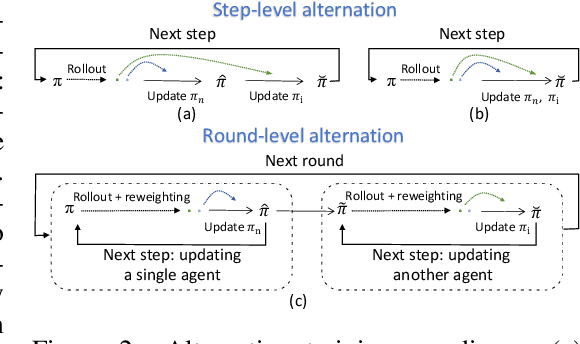

The rapid advancement of large vision language models (LVLMs) and agent systems has heightened interest in mobile GUI agents that can reliably translate natural language into interface operations. Existing single-agent approaches, however, remain limited by structural constraints. Although multi-agent systems naturally decouple different competencies, recent progress in multi-agent reinforcement learning (MARL) has often been hindered by inefficiency and remains incompatible with current LVLM architectures. To address these challenges, we introduce SWIRL, a staged workflow for interleaved reinforcement learning designed for multi-agent systems. SWIRL reformulates MARL into a sequence of single-agent reinforcement learning tasks, updating one agent at a time while keeping the others fixed. This formulation enables stable training and promotes efficient coordination across agents. Theoretically, we provide a stepwise safety bound, a cross-round monotonic improvement theorem, and convergence guarantees on return, ensuring robust and principled optimization. In application to mobile GUI control, SWIRL instantiates a Navigator that converts language and screen context into structured plans, and an Interactor that grounds these plans into executable atomic actions. Extensive experiments demonstrate superior performance on both high-level and low-level GUI benchmarks. Beyond GUI tasks, SWIRL also demonstrates strong capability in multi-agent mathematical reasoning, underscoring its potential as a general framework for developing efficient and robust multi-agent systems.
LLM4Ranking: An Easy-to-use Framework of Utilizing Large Language Models for Document Reranking
Apr 10, 2025



Utilizing large language models (LLMs) for document reranking has been a popular and promising research direction in recent years, many studies are dedicated to improving the performance and efficiency of using LLMs for reranking. Besides, it can also be applied in many real-world applications, such as search engines or retrieval-augmented generation. In response to the growing demand for research and application in practice, we introduce a unified framework, \textbf{LLM4Ranking}, which enables users to adopt different ranking methods using open-source or closed-source API-based LLMs. Our framework provides a simple and extensible interface for document reranking with LLMs, as well as easy-to-use evaluation and fine-tuning scripts for this task. We conducted experiments based on this framework and evaluated various models and methods on several widely used datasets, providing reproducibility results on utilizing LLMs for document reranking. Our code is publicly available at https://github.com/liuqi6777/llm4ranking.
MM-Eureka: Exploring Visual Aha Moment with Rule-based Large-scale Reinforcement Learning
Mar 10, 2025We present MM-Eureka, a multimodal reasoning model that successfully extends large-scale rule-based reinforcement learning (RL) to multimodal reasoning. While rule-based RL has shown remarkable success in improving LLMs' reasoning abilities in text domains, its application to multimodal settings has remained challenging. Our work reproduces key characteristics of text-based RL systems like DeepSeek-R1 in the multimodal space, including steady increases in accuracy reward and response length, and the emergence of reflection behaviors. We demonstrate that both instruction-tuned and pre-trained models can develop strong multimodal reasoning capabilities through rule-based RL without supervised fine-tuning, showing superior data efficiency compared to alternative approaches. We open-source our complete pipeline to foster further research in this area. We release all our codes, models, data, etc. at https://github.com/ModalMinds/MM-EUREKA
Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
Oct 07, 2024Text-to-video (T2V) models like Sora have made significant strides in visualizing complex prompts, which is increasingly viewed as a promising path towards constructing the universal world simulator. Cognitive psychologists believe that the foundation for achieving this goal is the ability to understand intuitive physics. However, the capacity of these models to accurately represent intuitive physics remains largely unexplored. To bridge this gap, we introduce PhyGenBench, a comprehensive \textbf{Phy}sics \textbf{Gen}eration \textbf{Ben}chmark designed to evaluate physical commonsense correctness in T2V generation. PhyGenBench comprises 160 carefully crafted prompts across 27 distinct physical laws, spanning four fundamental domains, which could comprehensively assesses models' understanding of physical commonsense. Alongside PhyGenBench, we propose a novel evaluation framework called PhyGenEval. This framework employs a hierarchical evaluation structure utilizing appropriate advanced vision-language models and large language models to assess physical commonsense. Through PhyGenBench and PhyGenEval, we can conduct large-scale automated assessments of T2V models' understanding of physical commonsense, which align closely with human feedback. Our evaluation results and in-depth analysis demonstrate that current models struggle to generate videos that comply with physical commonsense. Moreover, simply scaling up models or employing prompt engineering techniques is insufficient to fully address the challenges presented by PhyGenBench (e.g., dynamic scenarios). We hope this study will inspire the community to prioritize the learning of physical commonsense in these models beyond entertainment applications. We will release the data and codes at https://github.com/OpenGVLab/PhyGenBench
MMIU: Multimodal Multi-image Understanding for Evaluating Large Vision-Language Models
Aug 05, 2024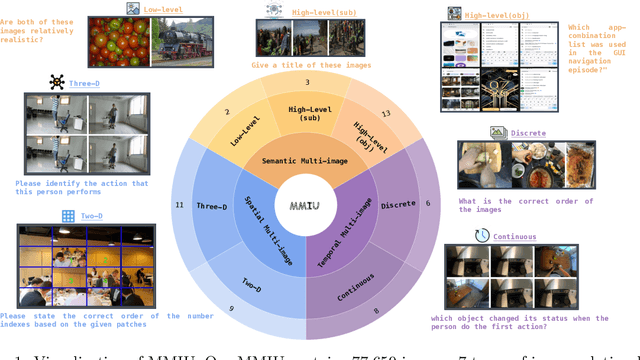

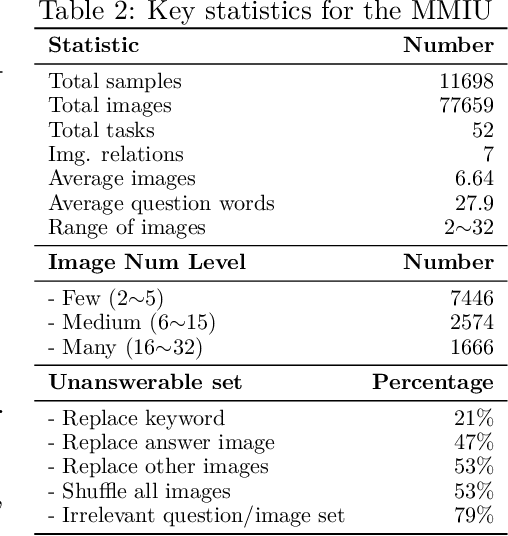
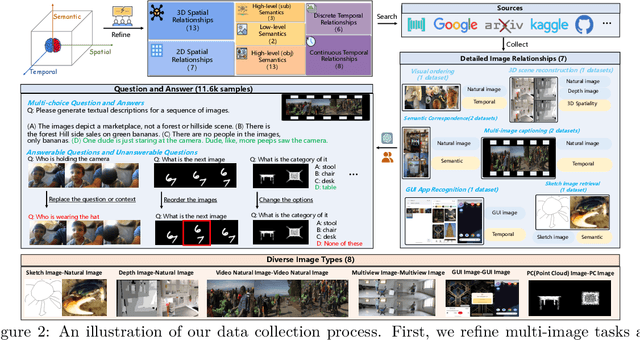
The capability to process multiple images is crucial for Large Vision-Language Models (LVLMs) to develop a more thorough and nuanced understanding of a scene. Recent multi-image LVLMs have begun to address this need. However, their evaluation has not kept pace with their development. To fill this gap, we introduce the Multimodal Multi-image Understanding (MMIU) benchmark, a comprehensive evaluation suite designed to assess LVLMs across a wide range of multi-image tasks. MMIU encompasses 7 types of multi-image relationships, 52 tasks, 77K images, and 11K meticulously curated multiple-choice questions, making it the most extensive benchmark of its kind. Our evaluation of 24 popular LVLMs, including both open-source and proprietary models, reveals significant challenges in multi-image comprehension, particularly in tasks involving spatial understanding. Even the most advanced models, such as GPT-4o, achieve only 55.7% accuracy on MMIU. Through multi-faceted analytical experiments, we identify key performance gaps and limitations, providing valuable insights for future model and data improvements. We aim for MMIU to advance the frontier of LVLM research and development, moving us toward achieving sophisticated multimodal multi-image user interactions.
PhyBench: A Physical Commonsense Benchmark for Evaluating Text-to-Image Models
Jun 17, 2024

Text-to-image (T2I) models have made substantial progress in generating images from textual prompts. However, they frequently fail to produce images consistent with physical commonsense, a vital capability for applications in world simulation and everyday tasks. Current T2I evaluation benchmarks focus on metrics such as accuracy, bias, and safety, neglecting the evaluation of models' internal knowledge, particularly physical commonsense. To address this issue, we introduce PhyBench, a comprehensive T2I evaluation dataset comprising 700 prompts across 4 primary categories: mechanics, optics, thermodynamics, and material properties, encompassing 31 distinct physical scenarios. We assess 6 prominent T2I models, including proprietary models DALLE3 and Gemini, and demonstrate that incorporating physical principles into prompts enhances the models' ability to generate physically accurate images. Our findings reveal that: (1) even advanced models frequently err in various physical scenarios, except for optics; (2) GPT-4o, with item-specific scoring instructions, effectively evaluates the models' understanding of physical commonsense, closely aligning with human assessments; and (3) current T2I models are primarily focused on text-to-image translation, lacking profound reasoning regarding physical commonsense. We advocate for increased attention to the inherent knowledge within T2I models, beyond their utility as mere image generation tools. The code and data are available at https://github.com/OpenGVLab/PhyBench.
GUI Odyssey: A Comprehensive Dataset for Cross-App GUI Navigation on Mobile Devices
Jun 12, 2024


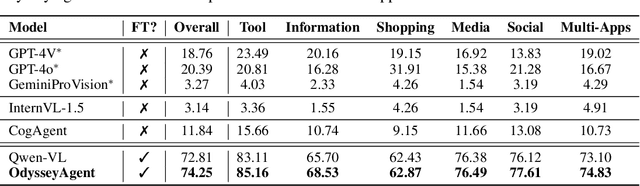
Smartphone users often navigate across multiple applications (apps) to complete tasks such as sharing content between social media platforms. Autonomous Graphical User Interface (GUI) navigation agents can enhance user experience in communication, entertainment, and productivity by streamlining workflows and reducing manual intervention. However, prior GUI agents often trained with datasets comprising simple tasks that can be completed within a single app, leading to poor performance in cross-app navigation. To address this problem, we introduce GUI Odyssey, a comprehensive dataset for training and evaluating cross-app navigation agents. GUI Odyssey consists of 7,735 episodes from 6 mobile devices, spanning 6 types of cross-app tasks, 201 apps, and 1.4K app combos. Leveraging GUI Odyssey, we developed OdysseyAgent, a multimodal cross-app navigation agent by fine-tuning the Qwen-VL model with a history resampling module. Extensive experiments demonstrate OdysseyAgent's superior accuracy compared to existing models. For instance, OdysseyAgent surpasses fine-tuned Qwen-VL and zero-shot GPT-4V by 1.44\% and 55.49\% in-domain accuracy, and 2.29\% and 48.14\% out-of-domain accuracy on average. The dataset and code will be released in \url{https://github.com/OpenGVLab/GUI-Odyssey}.
MMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI
Apr 24, 2024



Large Vision-Language Models (LVLMs) show significant strides in general-purpose multimodal applications such as visual dialogue and embodied navigation. However, existing multimodal evaluation benchmarks cover a limited number of multimodal tasks testing rudimentary capabilities, falling short in tracking LVLM development. In this study, we present MMT-Bench, a comprehensive benchmark designed to assess LVLMs across massive multimodal tasks requiring expert knowledge and deliberate visual recognition, localization, reasoning, and planning. MMT-Bench comprises $31,325$ meticulously curated multi-choice visual questions from various multimodal scenarios such as vehicle driving and embodied navigation, covering $32$ core meta-tasks and $162$ subtasks in multimodal understanding. Due to its extensive task coverage, MMT-Bench enables the evaluation of LVLMs using a task map, facilitating the discovery of in- and out-of-domain tasks. Evaluation results involving $30$ LVLMs such as the proprietary GPT-4V, GeminiProVision, and open-sourced InternVL-Chat, underscore the significant challenges posed by MMT-Bench. We anticipate that MMT-Bench will inspire the community to develop next-generation multimodal foundation models aimed at achieving general-purpose multimodal intelligence.
OmniMedVQA: A New Large-Scale Comprehensive Evaluation Benchmark for Medical LVLM
Feb 14, 2024



Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in various multimodal tasks. However, their potential in the medical domain remains largely unexplored. A significant challenge arises from the scarcity of diverse medical images spanning various modalities and anatomical regions, which is essential in real-world medical applications. To solve this problem, in this paper, we introduce OmniMedVQA, a novel comprehensive medical Visual Question Answering (VQA) benchmark. This benchmark is collected from 75 different medical datasets, including 12 different modalities and covering more than 20 distinct anatomical regions. Importantly, all images in this benchmark are sourced from authentic medical scenarios, ensuring alignment with the requirements of the medical field and suitability for evaluating LVLMs. Through our extensive experiments, we have found that existing LVLMs struggle to address these medical VQA problems effectively. Moreover, what surprises us is that medical-specialized LVLMs even exhibit inferior performance to those general-domain models, calling for a more versatile and robust LVLM in the biomedical field. The evaluation results not only reveal the current limitations of LVLM in understanding real medical images but also highlight our dataset's significance. Our dataset will be made publicly available.