 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeEdit: A Dataset, Benchmark and Glyph-Guided Framework for Text-centric Image Editing
Mar 12, 2026Instruction-based image editing aims to modify specific content within existing images according to user-provided instructions while preserving non-target regions. Beyond traditional object- and style-centric manipulation, text-centric image editing focuses on modifying, translating, or rearranging textual elements embedded within images. However, existing leading models often struggle to execute complex text editing precisely, frequently producing blurry or hallucinated characters. We attribute these failures primarily to the lack of specialized training paradigms tailored for text-centric editing, as well as the absence of large-scale datasets and standardized benchmarks necessary for a closed-loop training and evaluation system. To address these limitations, we present WeEdit, a systematic solution encompassing a scalable data construction pipeline, two benchmarks, and a tailored two-stage training strategy. Specifically, we propose a novel HTML-based automatic editing pipeline, which generates 330K training pairs covering diverse editing operations and 15 languages, accompanied by standardized bilingual and multilingual benchmarks for comprehensive evaluation. On the algorithmic side, we employ glyph-guided supervised fine-tuning to inject explicit spatial and content priors, followed by a multi-objective reinforcement learning stage to align generation with instruction adherence, text clarity, and background preservation. Extensive experiments demonstrate that WeEdit outperforms previous open-source models by a clear margin across diverse editing operations.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
MM-PRM: Enhancing Multimodal Mathematical Reasoning with Scalable Step-Level Supervision
May 19, 2025While Multimodal Large Language Models (MLLMs) have achieved impressive progress in vision-language understanding, they still struggle with complex multi-step reasoning, often producing logically inconsistent or partially correct solutions. A key limitation lies in the lack of fine-grained supervision over intermediate reasoning steps. To address this, we propose MM-PRM, a process reward model trained within a fully automated, scalable framework. We first build MM-Policy, a strong multimodal model trained on diverse mathematical reasoning data. Then, we construct MM-K12, a curated dataset of 10,000 multimodal math problems with verifiable answers, which serves as seed data. Leveraging a Monte Carlo Tree Search (MCTS)-based pipeline, we generate over 700k step-level annotations without human labeling. The resulting PRM is used to score candidate reasoning paths in the Best-of-N inference setup and achieves significant improvements across both in-domain (MM-K12 test set) and out-of-domain (OlympiadBench, MathVista, etc.) benchmarks. Further analysis confirms the effectiveness of soft labels, smaller learning rates, and path diversity in optimizing PRM performance. MM-PRM demonstrates that process supervision is a powerful tool for enhancing the logical robustness of multimodal reasoning systems. We release all our codes and data at https://github.com/ModalMinds/MM-PRM.
CPGD: Toward Stable Rule-based Reinforcement Learning for Language Models
May 18, 2025Recent advances in rule-based reinforcement learning (RL) have significantly improved the reasoning capability of language models (LMs) with rule-based rewards. However, existing RL methods -- such as GRPO, REINFORCE++, and RLOO -- often suffer from training instability, where large policy updates and improper clipping can lead to training collapse. To address this issue, we propose Clipped Policy Gradient Optimization with Policy Drift (CPGD), a novel algorithm designed to stabilize policy learning in LMs. CPGD introduces a policy drift constraint based on KL divergence to dynamically regularize policy updates, and leverages a clip mechanism on the logarithm of the ratio to prevent excessive policy updates. We provide theoretical justification for CPGD and demonstrate through empirical analysis that it mitigates the instability observed in prior approaches. Furthermore, we show that CPGD significantly improves performance while maintaining training stability. Our implementation balances theoretical rigor with practical usability, offering a robust alternative for RL in the post-training of LMs. We release our code at https://github.com/ModalMinds/MM-EUREKA.
MM-Eureka: Exploring Visual Aha Moment with Rule-based Large-scale Reinforcement Learning
Mar 10, 2025We present MM-Eureka, a multimodal reasoning model that successfully extends large-scale rule-based reinforcement learning (RL) to multimodal reasoning. While rule-based RL has shown remarkable success in improving LLMs' reasoning abilities in text domains, its application to multimodal settings has remained challenging. Our work reproduces key characteristics of text-based RL systems like DeepSeek-R1 in the multimodal space, including steady increases in accuracy reward and response length, and the emergence of reflection behaviors. We demonstrate that both instruction-tuned and pre-trained models can develop strong multimodal reasoning capabilities through rule-based RL without supervised fine-tuning, showing superior data efficiency compared to alternative approaches. We open-source our complete pipeline to foster further research in this area. We release all our codes, models, data, etc. at https://github.com/ModalMinds/MM-EUREKA
Rapid Learning in Constrained Minimax Games with Negative Momentum
Dec 31, 2024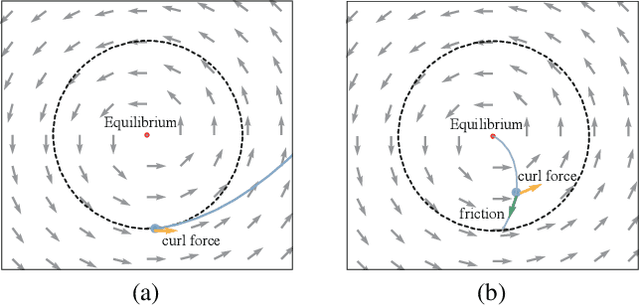


In this paper, we delve into the utilization of the negative momentum technique in constrained minimax games. From an intuitive mechanical standpoint, we introduce a novel framework for momentum buffer updating, which extends the findings of negative momentum from the unconstrained setting to the constrained setting and provides a universal enhancement to the classic game-solver algorithms. Additionally, we provide theoretical guarantee of convergence for our momentum-augmented algorithms with entropy regularizer. We then extend these algorithms to their extensive-form counterparts. Experimental results on both Normal Form Games (NFGs) and Extensive Form Games (EFGs) demonstrate that our momentum techniques can significantly improve algorithm performance, surpassing both their original versions and the SOTA baselines by a large margin.
An Offline Adaptation Framework for Constrained Multi-Objective Reinforcement Learning
Sep 16, 2024In recent years, significant progress has been made in multi-objective reinforcement learning (RL) research, which aims to balance multiple objectives by incorporating preferences for each objective. In most existing studies, specific preferences must be provided during deployment to indicate the desired policies explicitly. However, designing these preferences depends heavily on human prior knowledge, which is typically obtained through extensive observation of high-performing demonstrations with expected behaviors. In this work, we propose a simple yet effective offline adaptation framework for multi-objective RL problems without assuming handcrafted target preferences, but only given several demonstrations to implicitly indicate the preferences of expected policies. Additionally, we demonstrate that our framework can naturally be extended to meet constraints on safety-critical objectives by utilizing safe demonstrations, even when the safety thresholds are unknown. Empirical results on offline multi-objective and safe tasks demonstrate the capability of our framework to infer policies that align with real preferences while meeting the constraints implied by the provided demonstrations.
Policy-regularized Offline Multi-objective Reinforcement Learning
Jan 04, 2024



In this paper, we aim to utilize only offline trajectory data to train a policy for multi-objective RL. We extend the offline policy-regularized method, a widely-adopted approach for single-objective offline RL problems, into the multi-objective setting in order to achieve the above goal. However, such methods face a new challenge in offline MORL settings, namely the preference-inconsistent demonstration problem. We propose two solutions to this problem: 1) filtering out preference-inconsistent demonstrations via approximating behavior preferences, and 2) adopting regularization techniques with high policy expressiveness. Moreover, we integrate the preference-conditioned scalarized update method into policy-regularized offline RL, in order to simultaneously learn a set of policies using a single policy network, thus reducing the computational cost induced by the training of a large number of individual policies for various preferences. Finally, we introduce Regularization Weight Adaptation to dynamically determine appropriate regularization weights for arbitrary target preferences during deployment. Empirical results on various multi-objective datasets demonstrate the capability of our approach in solving offline MORL problems.