 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyBench: A Physical Commonsense Benchmark for Evaluating Text-to-Image Models
Paper and Code

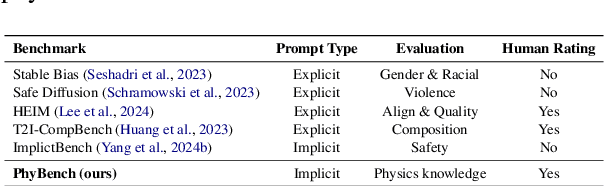

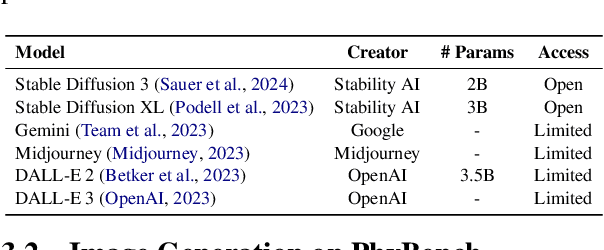
Text-to-image (T2I) models have made substantial progress in generating images from textual prompts. However, they frequently fail to produce images consistent with physical commonsense, a vital capability for applications in world simulation and everyday tasks. Current T2I evaluation benchmarks focus on metrics such as accuracy, bias, and safety, neglecting the evaluation of models' internal knowledge, particularly physical commonsense. To address this issue, we introduce PhyBench, a comprehensive T2I evaluation dataset comprising 700 prompts across 4 primary categories: mechanics, optics, thermodynamics, and material properties, encompassing 31 distinct physical scenarios. We assess 6 prominent T2I models, including proprietary models DALLE3 and Gemini, and demonstrate that incorporating physical principles into prompts enhances the models' ability to generate physically accurate images. Our findings reveal that: (1) even advanced models frequently err in various physical scenarios, except for optics; (2) GPT-4o, with item-specific scoring instructions, effectively evaluates the models' understanding of physical commonsense, closely aligning with human assessments; and (3) current T2I models are primarily focused on text-to-image translation, lacking profound reasoning regarding physical commonsense. We advocate for increased attention to the inherent knowledge within T2I models, beyond their utility as mere image generation tools. The code and data are available at https://github.com/OpenGVLab/PhyBench.