 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSandboxed Coding Agents are Competitive Omni-modal Task Solvers
May 30, 2026As multimodal LLMs increasingly target video and audio, it is often assumed that such tasks require native omnimodal models. We show that this is not always the case: coding agents with only text+image access and a sandboxed tool-use interface can match, and in several settings outperform, SOTA native omnimodal models and predefined multimodal agent scaffolds across multiple audio-video benchmarks. Our trajectory analysis suggests that their strength comes from writing code and orchestrating tools to extract relevant evidence from transcripts, frames, and other modality signals, thereby converting omnimodal tasks into retrieval and information-processing problems rather than ingesting entire media streams. We further characterize their limitations through a failure taxonomy and process-level trace analysis, and show that simple skill injection, including human-written and self-distilled skills, substantially improves performance. To explore open-source elicitation, we introduce Code-X, a training recipe with the OmniCoding trajectory dataset and verifiable reward, and provide baselines on Qwen-3.5-9B and Qwen-3.6-27B. Finally, we argue that the next frontier is many-modality processing, and introduce TerminalBench-O, a process-level benchmark for real-world omnimodal processing tasks. Code will be available at https://github.com/Dongping-Chen/OmniCoding.
Useful Memories Become Faulty When Continuously Updated by LLMs
May 13, 2026Learning from past experience benefits from two complementary forms of memory: episodic traces -- raw trajectories of what happened -- and consolidated abstractions distilled across many episodes into reusable, schema-like lessons. Recent agentic-memory systems pursue the consolidated form: an LLM rewrites past trajectories into a textual memory bank that it continuously updates with new interactions, promising self-improving agents without parameter updates. Yet we find that such consolidated memories produced by today's LLMs are often faulty even when derived from useful experiences. As consolidation proceeds, memory utility first rises, then degrades, and can fall below the no-memory baseline. More surprisingly, even when consolidating from ground-truth solutions, GPT-5.4 fails on 54% of a set of ARC-AGI problems it had previously solved without memory. We trace the regression to the consolidation step rather than the underlying experience: the same trajectories yield qualitatively different memories under different update schedules, and an episodic-only control that simply retains those trajectories remains competitive with the consolidators we test. In a controlled ARC-AGI Stream environment that exposes Retain, Delete, and Consolidate actions, agents preserve raw episodes by default and double the accuracy of their forced-consolidation counterparts; disabling consolidation entirely (episodic management only) matches this auto regime. Practically, robust agent memory should treat raw episodes as first-class evidence and gate consolidation explicitly rather than firing it after every interaction. Looking forward, reliable agentic memory will require LLMs that can consolidate without overwriting the evidence they depend on.
Superminds Test: Actively Evaluating Collective Intelligence of Agent Society via Probing Agents
Apr 24, 2026Collective intelligence refers to the ability of a group to achieve outcomes beyond what any individual member can accomplish alone. As large language model agents scale to populations of millions, a key question arises: Does collective intelligence emerge spontaneously from scale? We present the first empirical evaluation of this question in a large-scale autonomous agent society. Studying MoltBook, a platform hosting over two million agents, we introduce Superminds Test, a hierarchical framework that probes society-level intelligence using controlled Probing Agents across three tiers: joint reasoning, information synthesis, and basic interaction. Our experiments reveal a stark absence of collective intelligence. The society fails to outperform individual frontier models on complex reasoning tasks, rarely synthesizes distributed information, and often fails even trivial coordination tasks. Platform-wide analysis further shows that interactions remain shallow, with threads rarely extending beyond a single reply and most responses being generic or off-topic. These results suggest that collective intelligence does not emerge from scale alone. Instead, the dominant limitation of current agent societies is extremely sparse and shallow interaction, which prevents agents from exchanging information and building on each other's outputs.
DRIFT: Dynamic Rule-Based Defense with Injection Isolation for Securing LLM Agents
Jun 13, 2025Large Language Models (LLMs) are increasingly central to agentic systems due to their strong reasoning and planning capabilities. By interacting with external environments through predefined tools, these agents can carry out complex user tasks. Nonetheless, this interaction also introduces the risk of prompt injection attacks, where malicious inputs from external sources can mislead the agent's behavior, potentially resulting in economic loss, privacy leakage, or system compromise. System-level defenses have recently shown promise by enforcing static or predefined policies, but they still face two key challenges: the ability to dynamically update security rules and the need for memory stream isolation. To address these challenges, we propose DRIFT, a Dynamic Rule-based Isolation Framework for Trustworthy agentic systems, which enforces both control- and data-level constraints. A Secure Planner first constructs a minimal function trajectory and a JSON-schema-style parameter checklist for each function node based on the user query. A Dynamic Validator then monitors deviations from the original plan, assessing whether changes comply with privilege limitations and the user's intent. Finally, an Injection Isolator detects and masks any instructions that may conflict with the user query from the memory stream to mitigate long-term risks. We empirically validate the effectiveness of DRIFT on the AgentDojo benchmark, demonstrating its strong security performance while maintaining high utility across diverse models -- showcasing both its robustness and adaptability.
What makes Reasoning Models Different? Follow the Reasoning Leader for Efficient Decoding
Jun 08, 2025Large reasoning models (LRMs) achieve strong reasoning performance by emitting long chains of thought. Yet, these verbose traces slow down inference and often drift into unnecessary detail, known as the overthinking phenomenon. To better understand LRMs' behavior, we systematically analyze the token-level misalignment between reasoning and non-reasoning models. While it is expected that their primary difference lies in the stylistic "thinking cues", LRMs uniquely exhibit two pivotal, previously under-explored phenomena: a Global Misalignment Rebound, where their divergence from non-reasoning models persists or even grows as response length increases, and more critically, a Local Misalignment Diminish, where the misalignment concentrates at the "thinking cues" each sentence starts with but rapidly declines in the remaining of the sentence. Motivated by the Local Misalignment Diminish, we propose FoReaL-Decoding, a collaborative fast-slow thinking decoding method for cost-quality trade-off. In FoReaL-Decoding, a Leading model leads the first few tokens for each sentence, and then a weaker draft model completes the following tokens to the end of each sentence. FoReaL-Decoding adopts a stochastic gate to smoothly interpolate between the small and the large model. On four popular math-reasoning benchmarks (AIME24, GPQA-Diamond, MATH500, AMC23), FoReaL-Decoding reduces theoretical FLOPs by 30 to 50% and trims CoT length by up to 40%, while preserving 86 to 100% of model performance. These results establish FoReaL-Decoding as a simple, plug-and-play route to controllable cost-quality trade-offs in reasoning-centric tasks.
LangBridge: Interpreting Image as a Combination of Language Embeddings
Mar 26, 2025



Recent years have witnessed remarkable advances in Large Vision-Language Models (LVLMs), which have achieved human-level performance across various complex vision-language tasks. Following LLaVA's paradigm, mainstream LVLMs typically employ a shallow MLP for visual-language alignment through a two-stage training process: pretraining for cross-modal alignment followed by instruction tuning. While this approach has proven effective, the underlying mechanisms of how MLPs bridge the modality gap remain poorly understood. Although some research has explored how LLMs process transformed visual tokens, few studies have investigated the fundamental alignment mechanism. Furthermore, the MLP adapter requires retraining whenever switching LLM backbones. To address these limitations, we first investigate the working principles of MLP adapters and discover that they learn to project visual embeddings into subspaces spanned by corresponding text embeddings progressively. Based on this insight, we propose LangBridge, a novel adapter that explicitly maps visual tokens to linear combinations of LLM vocabulary embeddings. This innovative design enables pretraining-free adapter transfer across different LLMs while maintaining performance. Our experimental results demonstrate that a LangBridge adapter pre-trained on Qwen2-0.5B can be directly applied to larger models such as LLaMA3-8B or Qwen2.5-14B while maintaining competitive performance. Overall, LangBridge enables interpretable vision-language alignment by grounding visual representations in LLM vocab embedding, while its plug-and-play design ensures efficient reuse across multiple LLMs with nearly no performance degradation. See our project page at https://jiaqiliao77.github.io/LangBridge.github.io/
ImageGen-CoT: Enhancing Text-to-Image In-context Learning with Chain-of-Thought Reasoning
Mar 25, 2025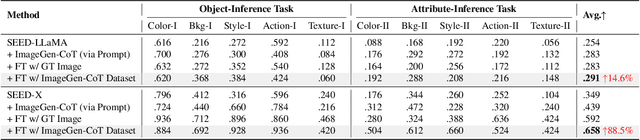



In this work, we study the problem of Text-to-Image In-Context Learning (T2I-ICL). While Unified Multimodal LLMs (MLLMs) have advanced rapidly in recent years, they struggle with contextual reasoning in T2I-ICL scenarios. To address this limitation, we propose a novel framework that incorporates a thought process called ImageGen-CoT prior to image generation. To avoid generating unstructured ineffective reasoning steps, we develop an automatic pipeline to curate a high-quality ImageGen-CoT dataset. We then fine-tune MLLMs using this dataset to enhance their contextual reasoning capabilities. To further enhance performance, we explore test-time scale-up strategies and propose a novel hybrid scaling approach. This approach first generates multiple ImageGen-CoT chains and then produces multiple images for each chain via sampling. Extensive experiments demonstrate the effectiveness of our proposed method. Notably, fine-tuning with the ImageGen-CoT dataset leads to a substantial 80\% performance gain for SEED-X on T2I-ICL tasks. See our project page at https://ImageGen-CoT.github.io/. Code and model weights will be open-sourced.
Florence-VL: Enhancing Vision-Language Models with Generative Vision Encoder and Depth-Breadth Fusion
Dec 05, 2024



We present Florence-VL, a new family of multimodal large language models (MLLMs) with enriched visual representations produced by Florence-2, a generative vision foundation model. Unlike the widely used CLIP-style vision transformer trained by contrastive learning, Florence-2 can capture different levels and aspects of visual features, which are more versatile to be adapted to diverse downstream tasks. We propose a novel feature-fusion architecture and an innovative training recipe that effectively integrates Florence-2's visual features into pretrained LLMs, such as Phi 3.5 and LLama 3. In particular, we propose "depth-breath fusion (DBFusion)" to fuse the visual features extracted from different depths and under multiple prompts. Our model training is composed of end-to-end pretraining of the whole model followed by finetuning of the projection layer and the LLM, on a carefully designed recipe of diverse open-source datasets that include high-quality image captions and instruction-tuning pairs. Our quantitative analysis and visualization of Florence-VL's visual features show its advantages over popular vision encoders on vision-language alignment, where the enriched depth and breath play important roles. Florence-VL achieves significant improvements over existing state-of-the-art MLLMs across various multi-modal and vision-centric benchmarks covering general VQA, perception, hallucination, OCR, Chart, knowledge-intensive understanding, etc. To facilitate future research, our models and the complete training recipe are open-sourced. https://github.com/JiuhaiChen/Florence-VL
Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
Oct 07, 2024Text-to-video (T2V) models like Sora have made significant strides in visualizing complex prompts, which is increasingly viewed as a promising path towards constructing the universal world simulator. Cognitive psychologists believe that the foundation for achieving this goal is the ability to understand intuitive physics. However, the capacity of these models to accurately represent intuitive physics remains largely unexplored. To bridge this gap, we introduce PhyGenBench, a comprehensive \textbf{Phy}sics \textbf{Gen}eration \textbf{Ben}chmark designed to evaluate physical commonsense correctness in T2V generation. PhyGenBench comprises 160 carefully crafted prompts across 27 distinct physical laws, spanning four fundamental domains, which could comprehensively assesses models' understanding of physical commonsense. Alongside PhyGenBench, we propose a novel evaluation framework called PhyGenEval. This framework employs a hierarchical evaluation structure utilizing appropriate advanced vision-language models and large language models to assess physical commonsense. Through PhyGenBench and PhyGenEval, we can conduct large-scale automated assessments of T2V models' understanding of physical commonsense, which align closely with human feedback. Our evaluation results and in-depth analysis demonstrate that current models struggle to generate videos that comply with physical commonsense. Moreover, simply scaling up models or employing prompt engineering techniques is insufficient to fully address the challenges presented by PhyGenBench (e.g., dynamic scenarios). We hope this study will inspire the community to prioritize the learning of physical commonsense in these models beyond entertainment applications. We will release the data and codes at https://github.com/OpenGVLab/PhyGenBench
Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts
Sep 24, 2024



Deep learning for time series forecasting has seen significant advancements over the past decades. However, despite the success of large-scale pre-training in language and vision domains, pre-trained time series models remain limited in scale and operate at a high cost, hindering the development of larger capable forecasting models in real-world applications. In response, we introduce Time-MoE, a scalable and unified architecture designed to pre-train larger, more capable forecasting foundation models while reducing inference costs. By leveraging a sparse mixture-of-experts (MoE) design, Time-MoE enhances computational efficiency by activating only a subset of networks for each prediction, reducing computational load while maintaining high model capacity. This allows Time-MoE to scale effectively without a corresponding increase in inference costs. Time-MoE comprises a family of decoder-only transformer models that operate in an auto-regressive manner and support flexible forecasting horizons with varying input context lengths. We pre-trained these models on our newly introduced large-scale data Time-300B, which spans over 9 domains and encompassing over 300 billion time points. For the first time, we scaled a time series foundation model up to 2.4 billion parameters, achieving significantly improved forecasting precision. Our results validate the applicability of scaling laws for training tokens and model size in the context of time series forecasting. Compared to dense models with the same number of activated parameters or equivalent computation budgets, our models consistently outperform them by large margin. These advancements position Time-MoE as a state-of-the-art solution for tackling real-world time series forecasting challenges with superior capability, efficiency, and flexibility.