 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniT: Unified Multimodal Chain-of-Thought Test-time Scaling
Feb 12, 2026Unified models can handle both multimodal understanding and generation within a single architecture, yet they typically operate in a single pass without iteratively refining their outputs. Many multimodal tasks, especially those involving complex spatial compositions, multiple interacting objects, or evolving instructions, require decomposing instructions, verifying intermediate results, and making iterative corrections. While test-time scaling (TTS) has demonstrated that allocating additional inference compute for iterative reasoning substantially improves language model performance, extending this paradigm to unified multimodal models remains an open challenge. We introduce UniT, a framework for multimodal chain-of-thought test-time scaling that enables a single unified model to reason, verify, and refine across multiple rounds. UniT combines agentic data synthesis, unified model training, and flexible test-time inference to elicit cognitive behaviors including verification, subgoal decomposition, and content memory. Our key findings are: (1) unified models trained on short reasoning trajectories generalize to longer inference chains at test time; (2) sequential chain-of-thought reasoning provides a more scalable and compute-efficient TTS strategy than parallel sampling; (3) training on generation and editing trajectories improves out-of-distribution visual reasoning. These results establish multimodal test-time scaling as an effective paradigm for advancing both generation and understanding in unified models.
Provable Defense Framework for LLM Jailbreaks via Noise-Augumented Alignment
Feb 02, 2026Large Language Models (LLMs) remain vulnerable to adaptive jailbreaks that easily bypass empirical defenses like GCG. We propose a framework for certifiable robustness that shifts safety guarantees from single-pass inference to the statistical stability of an ensemble. We introduce Certified Semantic Smoothing (CSS) via Stratified Randomized Ablation, a technique that partitions inputs into immutable structural prompts and mutable payloads to derive rigorous lo norm guarantees using the Hypergeometric distribution. To resolve performance degradation on sparse contexts, we employ Noise-Augmented Alignment Tuning (NAAT), which transforms the base model into a semantic denoiser. Extensive experiments on Llama-3 show that our method reduces the Attack Success Rate of gradient-based attacks from 84.2% to 1.2% while maintaining 94.1% benign utility, significantly outperforming character-level baselines which degrade utility to 74.3%. This framework provides a deterministic certificate of safety, ensuring that a model remains robust against all adversarial variants within a provable radius.
Learning Sparse Visual Representations via Spatial-Semantic Factorization
Feb 02, 2026Self-supervised learning (SSL) faces a fundamental conflict between semantic understanding and image reconstruction. High-level semantic SSL (e.g., DINO) relies on global tokens that are forced to be location-invariant for augmentation alignment, a process that inherently discards the spatial coordinates required for reconstruction. Conversely, generative SSL (e.g., MAE) preserves dense feature grids for reconstruction but fails to produce high-level abstractions. We introduce STELLAR, a framework that resolves this tension by factorizing visual features into a low-rank product of semantic concepts and their spatial distributions. This disentanglement allows us to perform DINO-style augmentation alignment on the semantic tokens while maintaining the precise spatial mapping in the localization matrix necessary for pixel-level reconstruction. We demonstrate that as few as 16 sparse tokens under this factorized form are sufficient to simultaneously support high-quality reconstruction (2.60 FID) and match the semantic performance of dense backbones (79.10% ImageNet accuracy). Our results highlight STELLAR as a versatile sparse representation that bridges the gap between discriminative and generative vision by strategically separating semantic identity from spatial geometry. Code available at https://aka.ms/stellar.
Lemon: A Unified and Scalable 3D Multimodal Model for Universal Spatial Understanding
Dec 14, 2025Scaling large multimodal models (LMMs) to 3D understanding poses unique challenges: point cloud data is sparse and irregular, existing models rely on fragmented architectures with modality-specific encoders, and training pipelines often suffer from instability and poor scalability. We introduce Lemon, a unified transformer architecture that addresses these challenges by jointly processing 3D point cloud patches and language tokens as a single sequence. Unlike prior work that relies on modality-specific encoders and cross-modal alignment modules, this design enables early spatial-linguistic fusion, eliminates redundant encoders, improves parameter efficiency, and supports more effective model scaling. To handle the complexity of 3D data, we develop a structured patchification and tokenization scheme that preserves spatial context, and a three-stage training curriculum that progressively builds capabilities from object-level recognition to scene-level spatial reasoning. Lemon establishes new state-of-the-art performance across comprehensive 3D understanding and reasoning tasks, from object recognition and captioning to spatial reasoning in 3D scenes, while demonstrating robust scaling properties as model size and training data increase. Our work provides a unified foundation for advancing 3D spatial intelligence in real-world applications.
Struct2D: A Perception-Guided Framework for Spatial Reasoning in Large Multimodal Models
Jun 04, 2025Unlocking spatial reasoning in Large Multimodal Models (LMMs) is crucial for enabling intelligent interaction with 3D environments. While prior efforts often rely on explicit 3D inputs or specialized model architectures, we ask: can LMMs reason about 3D space using only structured 2D representations derived from perception? We introduce Struct2D, a perception-guided prompting framework that combines bird's-eye-view (BEV) images with object marks and object-centric metadata, optionally incorporating egocentric keyframes when needed. Using Struct2D, we conduct an in-depth zero-shot analysis of closed-source LMMs (e.g., GPT-o3) and find that they exhibit surprisingly strong spatial reasoning abilities when provided with structured 2D inputs, effectively handling tasks such as relative direction estimation and route planning. Building on these insights, we construct Struct2D-Set, a large-scale instruction tuning dataset with 200K fine-grained QA pairs across eight spatial reasoning categories, generated automatically from 3D indoor scenes. We fine-tune an open-source LMM (Qwen2.5VL) on Struct2D-Set, achieving competitive performance on multiple benchmarks, including 3D question answering, dense captioning, and object grounding. Our approach demonstrates that structured 2D inputs can effectively bridge perception and language reasoning in LMMs-without requiring explicit 3D representations as input. We will release both our code and dataset to support future research.
SITE: towards Spatial Intelligence Thorough Evaluation
May 08, 2025Spatial intelligence (SI) represents a cognitive ability encompassing the visualization, manipulation, and reasoning about spatial relationships, underpinning disciplines from neuroscience to robotics. We introduce SITE, a benchmark dataset towards SI Thorough Evaluation in a standardized format of multi-choice visual question-answering, designed to assess large vision-language models' spatial intelligence across diverse visual modalities (single-image, multi-image, and video) and SI factors (figural to environmental scales, spatial visualization and orientation, intrinsic and extrinsic, static and dynamic). Our approach to curating the benchmark combines a bottom-up survey about 31 existing datasets and a top-down strategy drawing upon three classification systems in cognitive science, which prompt us to design two novel types of tasks about view-taking and dynamic scenes. Extensive experiments reveal that leading models fall behind human experts especially in spatial orientation, a fundamental SI factor. Moreover, we demonstrate a positive correlation between a model's spatial reasoning proficiency and its performance on an embodied AI task.
Towards Understanding Graphical Perception in Large Multimodal Models
Mar 13, 2025Despite the promising results of large multimodal models (LMMs) in complex vision-language tasks that require knowledge, reasoning, and perception abilities together, we surprisingly found that these models struggle with simple tasks on infographics that require perception only. As existing benchmarks primarily focus on end tasks that require various abilities, they provide limited, fine-grained insights into the limitations of the models' perception abilities. To address this gap, we leverage the theory of graphical perception, an approach used to study how humans decode visual information encoded on charts and graphs, to develop an evaluation framework for analyzing gaps in LMMs' perception abilities in charts. With automated task generation and response evaluation designs, our framework enables comprehensive and controlled testing of LMMs' graphical perception across diverse chart types, visual elements, and task types. We apply our framework to evaluate and diagnose the perception capabilities of state-of-the-art LMMs at three granularity levels (chart, visual element, and pixel). Our findings underscore several critical limitations of current state-of-the-art LMMs, including GPT-4o: their inability to (1) generalize across chart types, (2) understand fundamental visual elements, and (3) cross reference values within a chart. These insights provide guidance for future improvements in perception abilities of LMMs. The evaluation framework and labeled data are publicly available at https://github.com/microsoft/lmm-graphical-perception.
Magma: A Foundation Model for Multimodal AI Agents
Feb 18, 2025We present Magma, a foundation model that serves multimodal AI agentic tasks in both the digital and physical worlds. Magma is a significant extension of vision-language (VL) models in that it not only retains the VL understanding ability (verbal intelligence) of the latter, but is also equipped with the ability to plan and act in the visual-spatial world (spatial-temporal intelligence) and complete agentic tasks ranging from UI navigation to robot manipulation. To endow the agentic capabilities, Magma is pretrained on large amounts of heterogeneous datasets spanning from images, videos to robotics data, where the actionable visual objects (e.g., clickable buttons in GUI) in images are labeled by Set-of-Mark (SoM) for action grounding, and the object movements (e.g., the trace of human hands or robotic arms) in videos are labeled by Trace-of-Mark (ToM) for action planning. Extensive experiments show that SoM and ToM reach great synergy and facilitate the acquisition of spatial-temporal intelligence for our Magma model, which is fundamental to a wide range of tasks as shown in Fig.1. In particular, Magma creates new state-of-the-art results on UI navigation and robotic manipulation tasks, outperforming previous models that are specifically tailored to these tasks. On image and video-related multimodal tasks, Magma also compares favorably to popular large multimodal models that are trained on much larger datasets. We make our model and code public for reproducibility at https://microsoft.github.io/Magma.
ReFocus: Visual Editing as a Chain of Thought for Structured Image Understanding
Jan 09, 2025



Structured image understanding, such as interpreting tables and charts, requires strategically refocusing across various structures and texts within an image, forming a reasoning sequence to arrive at the final answer. However, current multimodal large language models (LLMs) lack this multihop selective attention capability. In this work, we introduce ReFocus, a simple yet effective framework that equips multimodal LLMs with the ability to generate "visual thoughts" by performing visual editing on the input image through code, shifting and refining their visual focuses. Specifically, ReFocus enables multimodal LLMs to generate Python codes to call tools and modify the input image, sequentially drawing boxes, highlighting sections, and masking out areas, thereby enhancing the visual reasoning process. We experiment upon a wide range of structured image understanding tasks involving tables and charts. ReFocus largely improves performance on all tasks over GPT-4o without visual editing, yielding an average gain of 11.0% on table tasks and 6.8% on chart tasks. We present an in-depth analysis of the effects of different visual edits, and reasons why ReFocus can improve the performance without introducing additional information. Further, we collect a 14k training set using ReFocus, and prove that such visual chain-of-thought with intermediate information offers a better supervision than standard VQA data, reaching a 8.0% average gain over the same model trained with QA pairs and 2.6% over CoT.
Is Your World Simulator a Good Story Presenter? A Consecutive Events-Based Benchmark for Future Long Video Generation
Dec 17, 2024
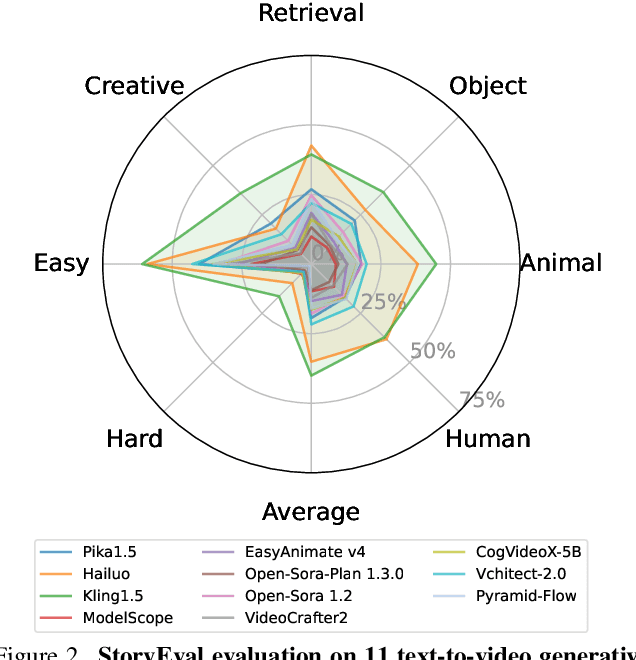


The current state-of-the-art video generative models can produce commercial-grade videos with highly realistic details. However, they still struggle to coherently present multiple sequential events in the stories specified by the prompts, which is foreseeable an essential capability for future long video generation scenarios. For example, top T2V generative models still fail to generate a video of the short simple story 'how to put an elephant into a refrigerator.' While existing detail-oriented benchmarks primarily focus on fine-grained metrics like aesthetic quality and spatial-temporal consistency, they fall short of evaluating models' abilities to handle event-level story presentation. To address this gap, we introduce StoryEval, a story-oriented benchmark specifically designed to assess text-to-video (T2V) models' story-completion capabilities. StoryEval features 423 prompts spanning 7 classes, each representing short stories composed of 2-4 consecutive events. We employ advanced vision-language models, such as GPT-4V and LLaVA-OV-Chat-72B, to verify the completion of each event in the generated videos, applying a unanimous voting method to enhance reliability. Our methods ensure high alignment with human evaluations, and the evaluation of 11 models reveals its challenge, with none exceeding an average story-completion rate of 50%. StoryEval provides a new benchmark for advancing T2V models and highlights the challenges and opportunities in developing next-generation solutions for coherent story-driven video generation.