 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement World Model Learning for LLM-based Agents
Feb 05, 2026Large language models (LLMs) have achieved strong performance in language-centric tasks. However, in agentic settings, LLMs often struggle to anticipate action consequences and adapt to environment dynamics, highlighting the need for world-modeling capabilities in LLM-based agents. We propose Reinforcement World Model Learning (RWML), a self-supervised method that learns action-conditioned world models for LLM-based agents on textual states using sim-to-real gap rewards. Our method aligns simulated next states produced by the model with realized next states observed from the environment, encouraging consistency between internal world simulations and actual environment dynamics in a pre-trained embedding space. Unlike next-state token prediction, which prioritizes token-level fidelity (i.e., reproducing exact wording) over semantic equivalence and can lead to model collapse, our method provides a more robust training signal and is empirically less susceptible to reward hacking than LLM-as-a-judge. We evaluate our method on ALFWorld and $τ^2$ Bench and observe significant gains over the base model, despite being entirely self-supervised. When combined with task-success rewards, our method outperforms direct task-success reward RL by 6.9 and 5.7 points on ALFWorld and $τ^2$ Bench respectively, while matching the performance of expert-data training.
Test-time Recursive Thinking: Self-Improvement without External Feedback
Feb 03, 2026Modern Large Language Models (LLMs) have shown rapid improvements in reasoning capabilities, driven largely by reinforcement learning (RL) with verifiable rewards. Here, we ask whether these LLMs can self-improve without the need for additional training. We identify two core challenges for such systems: (i) efficiently generating diverse, high-quality candidate solutions, and (ii) reliably selecting correct answers in the absence of ground-truth supervision. To address these challenges, we propose Test-time Recursive Thinking (TRT), an iterative self-improvement framework that conditions generation on rollout-specific strategies, accumulated knowledge, and self-generated verification signals. Using TRT, open-source models reach 100% accuracy on AIME-25/24, and on LiveCodeBench's most difficult problems, closed-source models improve by 10.4-14.8 percentage points without external feedback.
Training LLMs for Divide-and-Conquer Reasoning Elevates Test-Time Scalability
Feb 02, 2026Large language models (LLMs) have demonstrated strong reasoning capabilities through step-by-step chain-of-thought (CoT) reasoning. Nevertheless, at the limits of model capability, CoT often proves insufficient, and its strictly sequential nature constrains test-time scalability. A potential alternative is divide-and-conquer (DAC) reasoning, which decomposes a complex problem into subproblems to facilitate more effective exploration of the solution. Although promising, our analysis reveals a fundamental misalignment between general-purpose post-training and DAC-style inference, which limits the model's capacity to fully leverage this potential. To bridge this gap and fully unlock LLMs' reasoning capabilities on the most challenging tasks, we propose an end-to-end reinforcement learning (RL) framework to enhance their DAC-style reasoning capacity. At each step, the policy decomposes a problem into a group of subproblems, solves them sequentially, and addresses the original one conditioned on the subproblem solutions, with both decomposition and solution integrated into RL training. Under comparable training, our DAC-style framework endows the model with a higher performance ceiling and stronger test-time scalability, surpassing CoT by 8.6% in Pass@1 and 6.3% in Pass@32 on competition-level benchmarks.
RLBR: Reinforcement Learning with Biasing Rewards for Contextual Speech Large Language Models
Jan 19, 2026Speech large language models (LLMs) have driven significant progress in end-to-end speech understanding and recognition, yet they continue to struggle with accurately recognizing rare words and domain-specific terminology. This paper presents a novel fine-tuning method, Reinforcement Learning with Biasing Rewards (RLBR), which employs a specialized biasing words preferred reward to explicitly emphasize biasing words in the reward calculation. In addition, we introduce reference-aware mechanisms that extend the reinforcement learning algorithm with reference transcription to strengthen the potential trajectory exploration space. Experiments on the LibriSpeech corpus across various biasing list sizes demonstrate that RLBR delivers substantial performance improvements over a strong supervised fine-tuning (SFT) baseline and consistently outperforms several recently published methods. The proposed approach achieves excellent performance on the LibriSpeech test-clean and test-other sets, reaching Biasing Word Error Rates (BWERs) of 0.59% / 2.11%, 1.09% / 3.24%, and 1.36% / 4.04% for biasing list sizes of 100, 500, and 1000, respectively, without compromising the overall WERs.
Training Matryoshka Mixture-of-Experts for Elastic Inference-Time Expert Utilization
Sep 30, 2025Mixture-of-Experts (MoE) has emerged as a promising paradigm for efficiently scaling large language models without a proportional increase in computational cost. However, the standard training strategy of Top-K router prevents MoE models from realizing their full potential for elastic inference. When the number of activated experts is altered at inference time, these models exhibit precipitous performance degradation. In this work, we introduce Matryoshka MoE (M-MoE), a training framework that instills a coarse-to-fine structure directly into the expert ensemble. By systematically varying the number of activated experts during training, M-MoE compels the model to learn a meaningful ranking: top-ranked experts collaborate to provide essential, coarse-grained capabilities, while subsequent experts add progressively finer-grained detail. We explore this principle at multiple granularities, identifying a layer-wise randomization strategy as the most effective. Our experiments demonstrate that a single M-MoE model achieves remarkable elasticity, with its performance at various expert counts closely matching that of an entire suite of specialist models, but at only a fraction of the total training cost. This flexibility not only unlocks elastic inference but also enables optimizing performance by allocating different computational budgets to different model layers. Our work paves the way for more practical and adaptable deployments of large-scale MoE models.
SAS: Simulated Attention Score
Jul 10, 2025The attention mechanism is a core component of the Transformer architecture. Various methods have been developed to compute attention scores, including multi-head attention (MHA), multi-query attention, group-query attention and so on. We further analyze the MHA and observe that its performance improves as the number of attention heads increases, provided the hidden size per head remains sufficiently large. Therefore, increasing both the head count and hidden size per head with minimal parameter overhead can lead to significant performance gains at a low cost. Motivated by this insight, we introduce Simulated Attention Score (SAS), which maintains a compact model size while simulating a larger number of attention heads and hidden feature dimension per head. This is achieved by projecting a low-dimensional head representation into a higher-dimensional space, effectively increasing attention capacity without increasing parameter count. Beyond the head representations, we further extend the simulation approach to feature dimension of the key and query embeddings, enhancing expressiveness by mimicking the behavior of a larger model while preserving the original model size. To control the parameter cost, we also propose Parameter-Efficient Attention Aggregation (PEAA). Comprehensive experiments on a variety of datasets and tasks demonstrate the effectiveness of the proposed SAS method, achieving significant improvements over different attention variants.
Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
Jul 09, 2025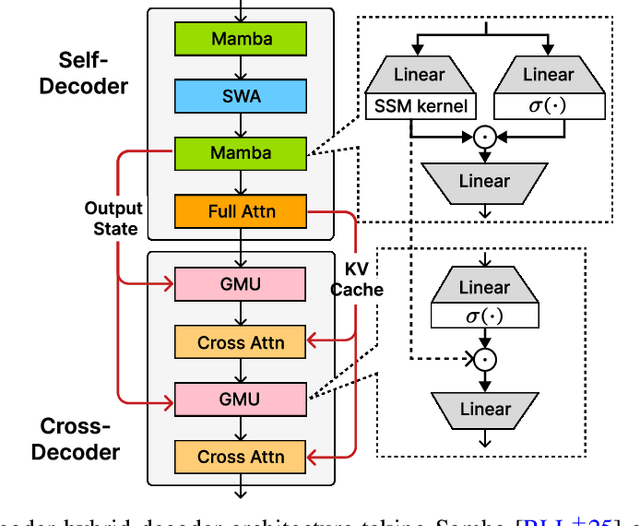
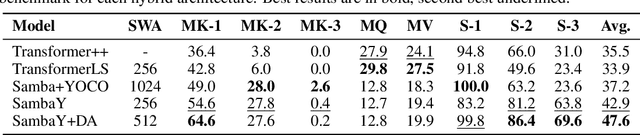
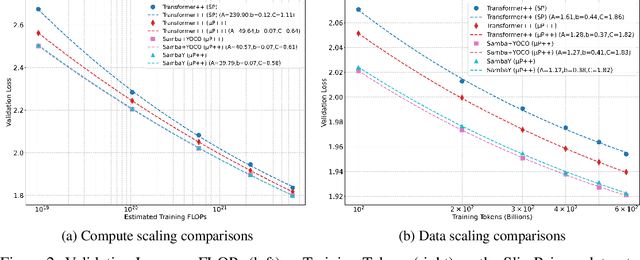
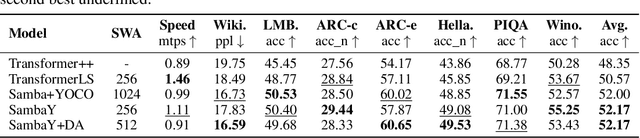
Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.
PeRL: Permutation-Enhanced Reinforcement Learning for Interleaved Vision-Language Reasoning
Jun 17, 2025Inspired by the impressive reasoning capabilities demonstrated by reinforcement learning approaches like DeepSeek-R1, recent emerging research has begun exploring the use of reinforcement learning (RL) to enhance vision-language models (VLMs) for multimodal reasoning tasks. However, most existing multimodal reinforcement learning approaches remain limited to spatial reasoning within single-image contexts, yet still struggle to generalize to more complex and real-world scenarios involving multi-image positional reasoning, where understanding the relationships across images is crucial. To address this challenge, we propose a general reinforcement learning approach PeRL tailored for interleaved multimodal tasks, and a multi-stage strategy designed to enhance the exploration-exploitation trade-off, thereby improving learning efficiency and task performance. Specifically, we introduce permutation of image sequences to simulate varied positional relationships to explore more spatial and positional diversity. Furthermore, we design a rollout filtering mechanism for resampling to focus on trajectories that contribute most to learning optimal behaviors to exploit learned policies effectively. We evaluate our model on 5 widely-used multi-image benchmarks and 3 single-image benchmarks. Our experiments confirm that PeRL trained model consistently surpasses R1-related and interleaved VLM baselines by a large margin, achieving state-of-the-art performance on multi-image benchmarks, while preserving comparable performance on single-image tasks.
SwS: Self-aware Weakness-driven Problem Synthesis in Reinforcement Learning for LLM Reasoning
Jun 10, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for training large language models (LLMs) on complex reasoning tasks, such as mathematical problem solving. A prerequisite for the scalability of RLVR is a high-quality problem set with precise and verifiable answers. However, the scarcity of well-crafted human-labeled math problems and limited-verification answers in existing distillation-oriented synthetic datasets limit their effectiveness in RL. Additionally, most problem synthesis strategies indiscriminately expand the problem set without considering the model's capabilities, leading to low efficiency in generating useful questions. To mitigate this issue, we introduce a Self-aware Weakness-driven problem Synthesis framework (SwS) that systematically identifies model deficiencies and leverages them for problem augmentation. Specifically, we define weaknesses as questions that the model consistently fails to learn through its iterative sampling during RL training. We then extract the core concepts from these failure cases and synthesize new problems to strengthen the model's weak areas in subsequent augmented training, enabling it to focus on and gradually overcome its weaknesses. Without relying on external knowledge distillation, our framework enables robust generalization byempowering the model to self-identify and address its weaknesses in RL, yielding average performance gains of 10.0% and 7.7% on 7B and 32B models across eight mainstream reasoning benchmarks.
SoK: Are Watermarks in LLMs Ready for Deployment?
Jun 05, 2025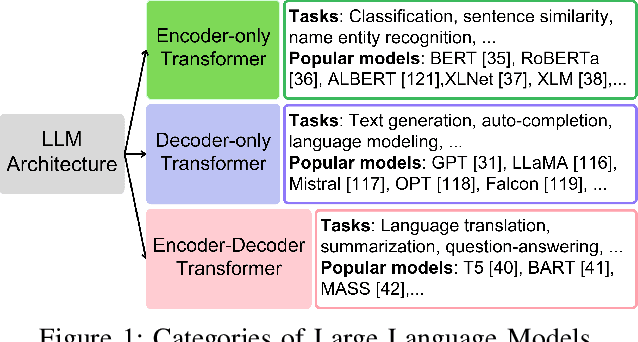
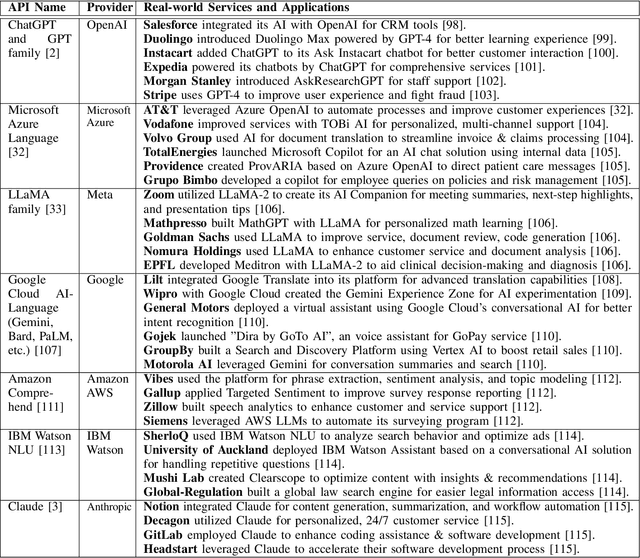
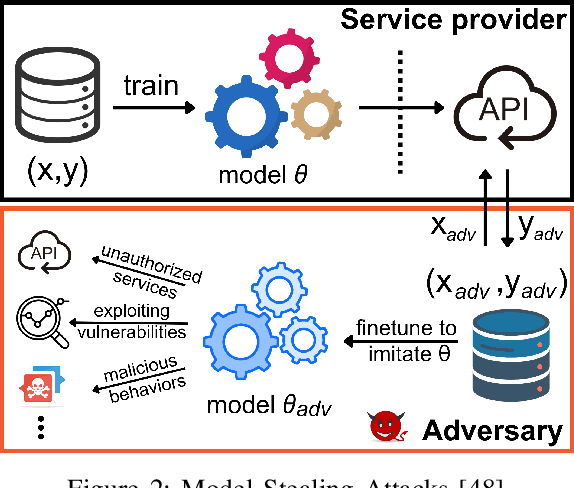
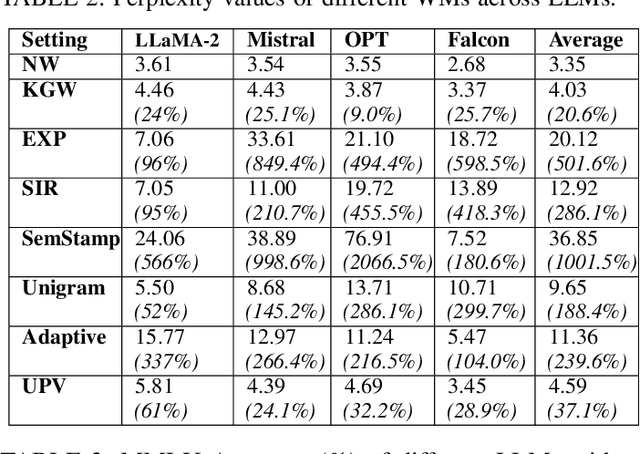
Large Language Models (LLMs) have transformed natural language processing, demonstrating impressive capabilities across diverse tasks. However, deploying these models introduces critical risks related to intellectual property violations and potential misuse, particularly as adversaries can imitate these models to steal services or generate misleading outputs. We specifically focus on model stealing attacks, as they are highly relevant to proprietary LLMs and pose a serious threat to their security, revenue, and ethical deployment. While various watermarking techniques have emerged to mitigate these risks, it remains unclear how far the community and industry have progressed in developing and deploying watermarks in LLMs. To bridge this gap, we aim to develop a comprehensive systematization for watermarks in LLMs by 1) presenting a detailed taxonomy for watermarks in LLMs, 2) proposing a novel intellectual property classifier to explore the effectiveness and impacts of watermarks on LLMs under both attack and attack-free environments, 3) analyzing the limitations of existing watermarks in LLMs, and 4) discussing practical challenges and potential future directions for watermarks in LLMs. Through extensive experiments, we show that despite promising research outcomes and significant attention from leading companies and community to deploy watermarks, these techniques have yet to reach their full potential in real-world applications due to their unfavorable impacts on model utility of LLMs and downstream tasks. Our findings provide an insightful understanding of watermarks in LLMs, highlighting the need for practical watermarks solutions tailored to LLM deployment.