 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOIR: Privacy-Preserving Generation of Code with Open-Source LLMs
Jan 22, 2026Although boosting software development performance, large language model (LLM)-powered code generation introduces intellectual property and data security risks rooted in the fact that a service provider (cloud) observes a client's prompts and generated code, which can be proprietary in commercial systems. To mitigate this problem, we propose NOIR, the first framework to protect the client's prompts and generated code from the cloud. NOIR uses an encoder and a decoder at the client to encode and send the prompts' embeddings to the cloud to get enriched embeddings from the LLM, which are then decoded to generate the code locally at the client. Since the cloud can use the embeddings to infer the prompt and the generated code, NOIR introduces a new mechanism to achieve indistinguishability, a local differential privacy protection at the token embedding level, in the vocabulary used in the prompts and code, and a data-independent and randomized tokenizer on the client side. These components effectively defend against reconstruction and frequency analysis attacks by an honest-but-curious cloud. Extensive analysis and results using open-source LLMs show that NOIR significantly outperforms existing baselines on benchmarks, including the Evalplus (MBPP and HumanEval, Pass@1 of 76.7 and 77.4), and BigCodeBench (Pass@1 of 38.7, only a 1.77% drop from the original LLM) under strong privacy against attacks.
ViGText: Deepfake Image Detection with Vision-Language Model Explanations and Graph Neural Networks
Jul 24, 2025The rapid rise of deepfake technology, which produces realistic but fraudulent digital content, threatens the authenticity of media. Traditional deepfake detection approaches often struggle with sophisticated, customized deepfakes, especially in terms of generalization and robustness against malicious attacks. This paper introduces ViGText, a novel approach that integrates images with Vision Large Language Model (VLLM) Text explanations within a Graph-based framework to improve deepfake detection. The novelty of ViGText lies in its integration of detailed explanations with visual data, as it provides a more context-aware analysis than captions, which often lack specificity and fail to reveal subtle inconsistencies. ViGText systematically divides images into patches, constructs image and text graphs, and integrates them for analysis using Graph Neural Networks (GNNs) to identify deepfakes. Through the use of multi-level feature extraction across spatial and frequency domains, ViGText captures details that enhance its robustness and accuracy to detect sophisticated deepfakes. Extensive experiments demonstrate that ViGText significantly enhances generalization and achieves a notable performance boost when it detects user-customized deepfakes. Specifically, average F1 scores rise from 72.45% to 98.32% under generalization evaluation, and reflects the model's superior ability to generalize to unseen, fine-tuned variations of stable diffusion models. As for robustness, ViGText achieves an increase of 11.1% in recall compared to other deepfake detection approaches. When facing targeted attacks that exploit its graph-based architecture, ViGText limits classification performance degradation to less than 4%. ViGText uses detailed visual and textual analysis to set a new standard for detecting deepfakes, helping ensure media authenticity and information integrity.
SoK: Are Watermarks in LLMs Ready for Deployment?
Jun 05, 2025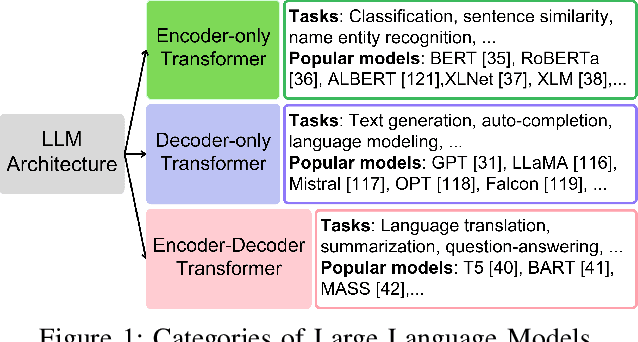
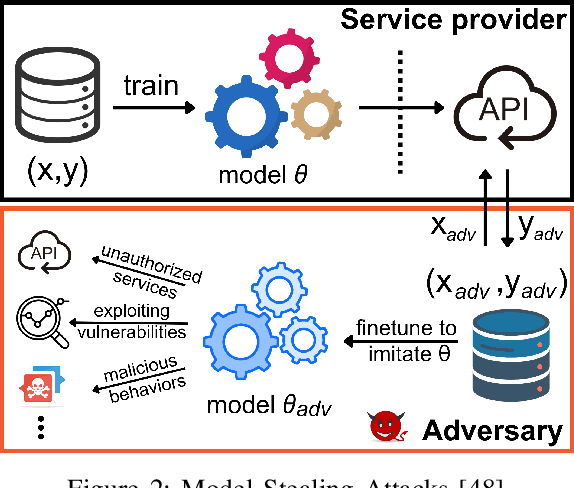
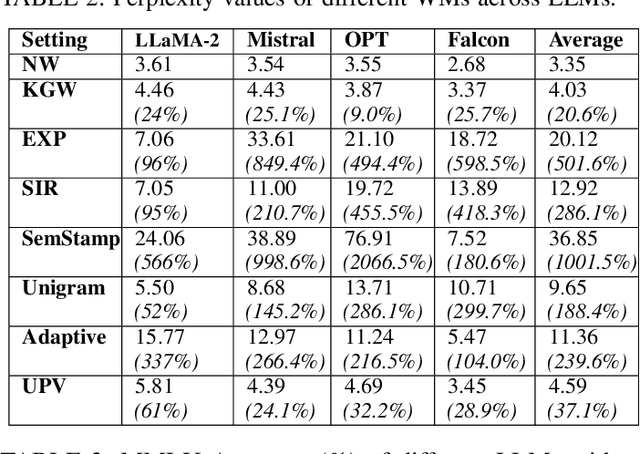
Large Language Models (LLMs) have transformed natural language processing, demonstrating impressive capabilities across diverse tasks. However, deploying these models introduces critical risks related to intellectual property violations and potential misuse, particularly as adversaries can imitate these models to steal services or generate misleading outputs. We specifically focus on model stealing attacks, as they are highly relevant to proprietary LLMs and pose a serious threat to their security, revenue, and ethical deployment. While various watermarking techniques have emerged to mitigate these risks, it remains unclear how far the community and industry have progressed in developing and deploying watermarks in LLMs. To bridge this gap, we aim to develop a comprehensive systematization for watermarks in LLMs by 1) presenting a detailed taxonomy for watermarks in LLMs, 2) proposing a novel intellectual property classifier to explore the effectiveness and impacts of watermarks on LLMs under both attack and attack-free environments, 3) analyzing the limitations of existing watermarks in LLMs, and 4) discussing practical challenges and potential future directions for watermarks in LLMs. Through extensive experiments, we show that despite promising research outcomes and significant attention from leading companies and community to deploy watermarks, these techniques have yet to reach their full potential in real-world applications due to their unfavorable impacts on model utility of LLMs and downstream tasks. Our findings provide an insightful understanding of watermarks in LLMs, highlighting the need for practical watermarks solutions tailored to LLM deployment.
Watermarking Degrades Alignment in Language Models: Analysis and Mitigation
Jun 04, 2025Watermarking techniques for large language models (LLMs) can significantly impact output quality, yet their effects on truthfulness, safety, and helpfulness remain critically underexamined. This paper presents a systematic analysis of how two popular watermarking approaches-Gumbel and KGW-affect these core alignment properties across four aligned LLMs. Our experiments reveal two distinct degradation patterns: guard attenuation, where enhanced helpfulness undermines model safety, and guard amplification, where excessive caution reduces model helpfulness. These patterns emerge from watermark-induced shifts in token distribution, surfacing the fundamental tension that exists between alignment objectives. To mitigate these degradations, we propose Alignment Resampling (AR), an inference-time sampling method that uses an external reward model to restore alignment. We establish a theoretical lower bound on the improvement in expected reward score as the sample size is increased and empirically demonstrate that sampling just 2-4 watermarked generations effectively recovers or surpasses baseline (unwatermarked) alignment scores. To overcome the limited response diversity of standard Gumbel watermarking, our modified implementation sacrifices strict distortion-freeness while maintaining robust detectability, ensuring compatibility with AR. Experimental results confirm that AR successfully recovers baseline alignment in both watermarking approaches, while maintaining strong watermark detectability. This work reveals the critical balance between watermark strength and model alignment, providing a simple inference-time solution to responsibly deploy watermarked LLMs in practice.
* Published at the 1st Workshop on GenAI Watermarking, collocated with ICLR 2025. OpenReview: https://openreview.net/forum?id=SIBkIV48gF
A Client-level Assessment of Collaborative Backdoor Poisoning in Non-IID Federated Learning
Apr 21, 2025Federated learning (FL) enables collaborative model training using decentralized private data from multiple clients. While FL has shown robustness against poisoning attacks with basic defenses, our research reveals new vulnerabilities stemming from non-independent and identically distributed (non-IID) data among clients. These vulnerabilities pose a substantial risk of model poisoning in real-world FL scenarios. To demonstrate such vulnerabilities, we develop a novel collaborative backdoor poisoning attack called CollaPois. In this attack, we distribute a single pre-trained model infected with a Trojan to a group of compromised clients. These clients then work together to produce malicious gradients, causing the FL model to consistently converge towards a low-loss region centered around the Trojan-infected model. Consequently, the impact of the Trojan is amplified, especially when the benign clients have diverse local data distributions and scattered local gradients. CollaPois stands out by achieving its goals while involving only a limited number of compromised clients, setting it apart from existing attacks. Also, CollaPois effectively avoids noticeable shifts or degradation in the FL model's performance on legitimate data samples, allowing it to operate stealthily and evade detection by advanced robust FL algorithms. Thorough theoretical analysis and experiments conducted on various benchmark datasets demonstrate the superiority of CollaPois compared to state-of-the-art backdoor attacks. Notably, CollaPois bypasses existing backdoor defenses, especially in scenarios where clients possess diverse data distributions. Moreover, the results show that CollaPois remains effective even when involving a small number of compromised clients. Notably, clients whose local data is closely aligned with compromised clients experience higher risks of backdoor infections.
Demo: SGCode: A Flexible Prompt-Optimizing System for Secure Generation of Code
Sep 11, 2024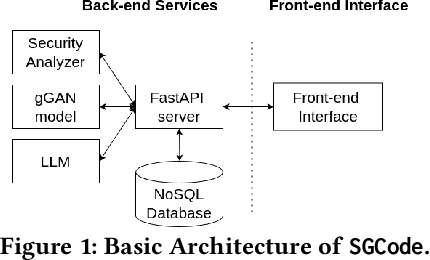
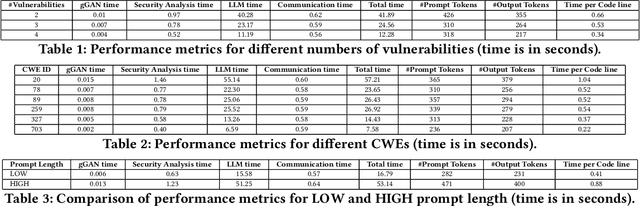
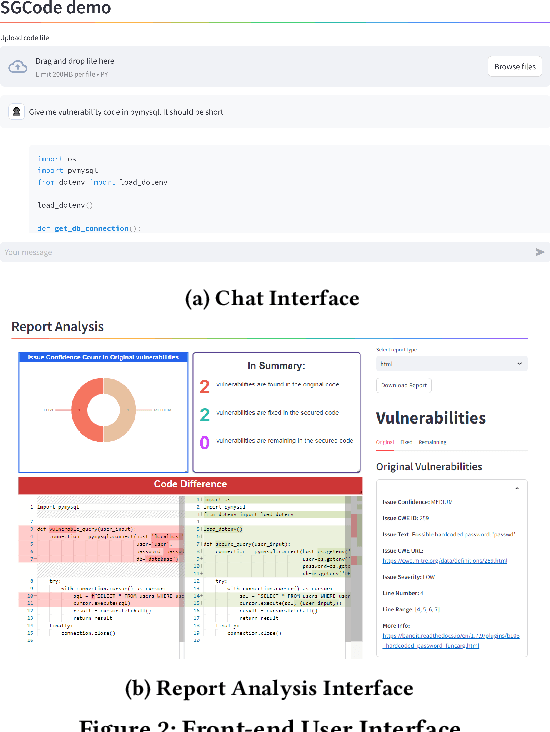
This paper introduces SGCode, a flexible prompt-optimizing system to generate secure code with large language models (LLMs). SGCode integrates recent prompt-optimization approaches with LLMs in a unified system accessible through front-end and back-end APIs, enabling users to 1) generate secure code, which is free of vulnerabilities, 2) review and share security analysis, and 3) easily switch from one prompt optimization approach to another, while providing insights on model and system performance. We populated SGCode on an AWS server with PromSec, an approach that optimizes prompts by combining an LLM and security tools with a lightweight generative adversarial graph neural network to detect and fix security vulnerabilities in the generated code. Extensive experiments show that SGCode is practical as a public tool to gain insights into the trade-offs between model utility, secure code generation, and system cost. SGCode has only a marginal cost compared with prompting LLMs. SGCode is available at: http://3.131.141.63:8501/.
Operationalizing a Threat Model for Red-Teaming Large Language Models (LLMs)
Jul 20, 2024

Creating secure and resilient applications with large language models (LLM) requires anticipating, adjusting to, and countering unforeseen threats. Red-teaming has emerged as a critical technique for identifying vulnerabilities in real-world LLM implementations. This paper presents a detailed threat model and provides a systematization of knowledge (SoK) of red-teaming attacks on LLMs. We develop a taxonomy of attacks based on the stages of the LLM development and deployment process and extract various insights from previous research. In addition, we compile methods for defense and practical red-teaming strategies for practitioners. By delineating prominent attack motifs and shedding light on various entry points, this paper provides a framework for improving the security and robustness of LLM-based systems.
Multi-Instance Adversarial Attack on GNN-Based Malicious Domain Detection
Aug 22, 2023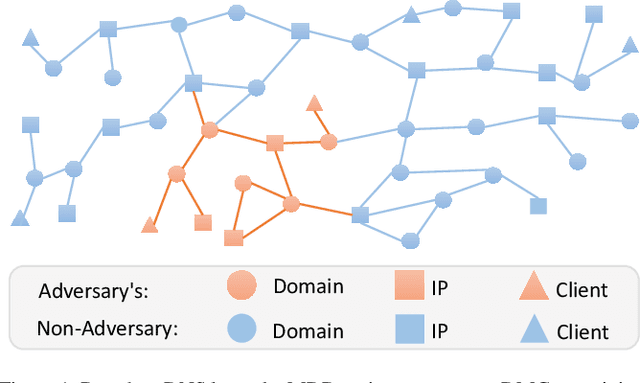

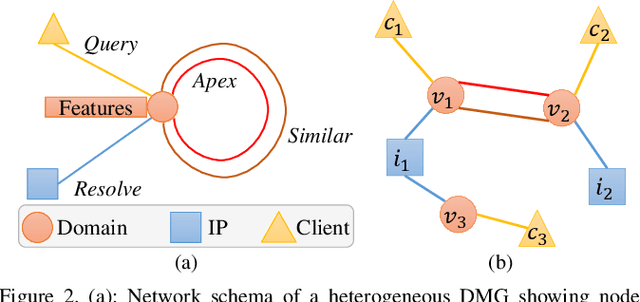

Malicious domain detection (MDD) is an open security challenge that aims to detect if an Internet domain is associated with cyber-attacks. Among many approaches to this problem, graph neural networks (GNNs) are deemed highly effective. GNN-based MDD uses DNS logs to represent Internet domains as nodes in a maliciousness graph (DMG) and trains a GNN to infer their maliciousness by leveraging identified malicious domains. Since this method relies on accessible DNS logs to construct DMGs, it exposes a vulnerability for adversaries to manipulate their domain nodes' features and connections within DMGs. Existing research mainly concentrates on threat models that manipulate individual attacker nodes. However, adversaries commonly generate multiple domains to achieve their goals economically and avoid detection. Their objective is to evade discovery across as many domains as feasible. In this work, we call the attack that manipulates several nodes in the DMG concurrently a multi-instance evasion attack. We present theoretical and empirical evidence that the existing single-instance evasion techniques for are inadequate to launch multi-instance evasion attacks against GNN-based MDDs. Therefore, we introduce MintA, an inference-time multi-instance adversarial attack on GNN-based MDDs. MintA enhances node and neighborhood evasiveness through optimized perturbations and operates successfully with only black-box access to the target model, eliminating the need for knowledge about the model's specifics or non-adversary nodes. We formulate an optimization challenge for MintA, achieving an approximate solution. Evaluating MintA on a leading GNN-based MDD technique with real-world data showcases an attack success rate exceeding 80%. These findings act as a warning for security experts, underscoring GNN-based MDDs' susceptibility to practical attacks that can undermine their effectiveness and benefits.
FairDP: Certified Fairness with Differential Privacy
May 25, 2023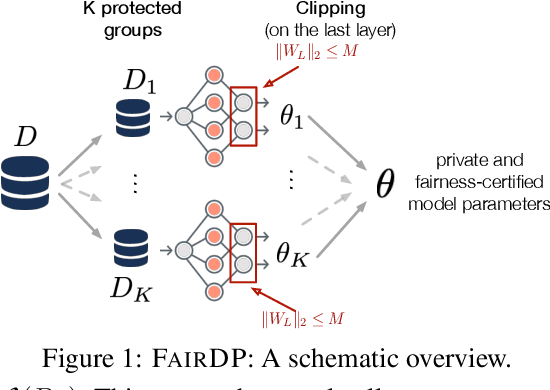

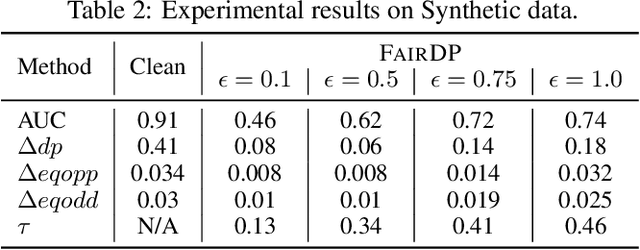
This paper introduces FairDP, a novel mechanism designed to simultaneously ensure differential privacy (DP) and fairness. FairDP operates by independently training models for distinct individual groups, using group-specific clipping terms to assess and bound the disparate impacts of DP. Throughout the training process, the mechanism progressively integrates knowledge from group models to formulate a comprehensive model that balances privacy, utility, and fairness in downstream tasks. Extensive theoretical and empirical analyses validate the efficacy of FairDP, demonstrating improved trade-offs between model utility, privacy, and fairness compared with existing methods.
Zone-based Federated Learning for Mobile Sensing Data
Mar 10, 2023

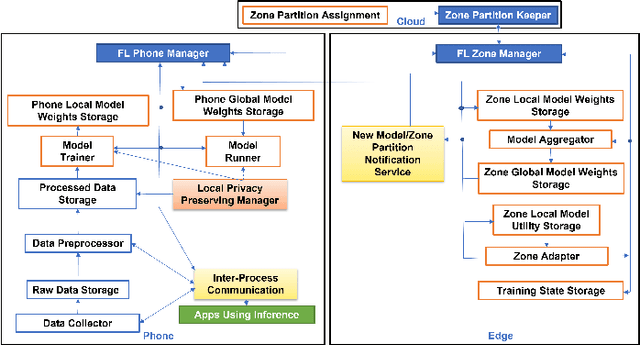

Mobile apps, such as mHealth and wellness applications, can benefit from deep learning (DL) models trained with mobile sensing data collected by smart phones or wearable devices. However, currently there is no mobile sensing DL system that simultaneously achieves good model accuracy while adapting to user mobility behavior, scales well as the number of users increases, and protects user data privacy. We propose Zone-based Federated Learning (ZoneFL) to address these requirements. ZoneFL divides the physical space into geographical zones mapped to a mobile-edge-cloud system architecture for good model accuracy and scalability. Each zone has a federated training model, called a zone model, which adapts well to data and behaviors of users in that zone. Benefiting from the FL design, the user data privacy is protected during the ZoneFL training. We propose two novel zone-based federated training algorithms to optimize zone models to user mobility behavior: Zone Merge and Split (ZMS) and Zone Gradient Diffusion (ZGD). ZMS optimizes zone models by adapting the zone geographical partitions through merging of neighboring zones or splitting of large zones into smaller ones. Different from ZMS, ZGD maintains fixed zones and optimizes a zone model by incorporating the gradients derived from neighboring zones' data. ZGD uses a self-attention mechanism to dynamically control the impact of one zone on its neighbors. Extensive analysis and experimental results demonstrate that ZoneFL significantly outperforms traditional FL in two models for heart rate prediction and human activity recognition. In addition, we developed a ZoneFL system using Android phones and AWS cloud. The system was used in a heart rate prediction field study with 63 users for 4 months, and we demonstrated the feasibility of ZoneFL in real-life.