 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXRand: Differentially Private Defense against Explanation-Guided Attacks
Paper and Code
Dec 14, 2022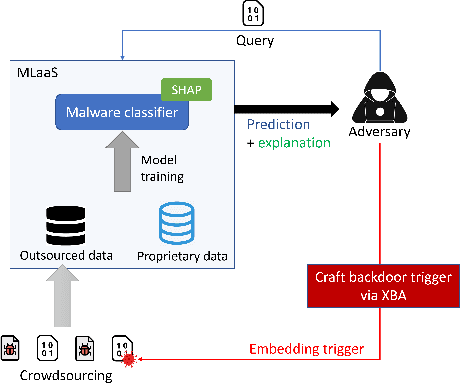
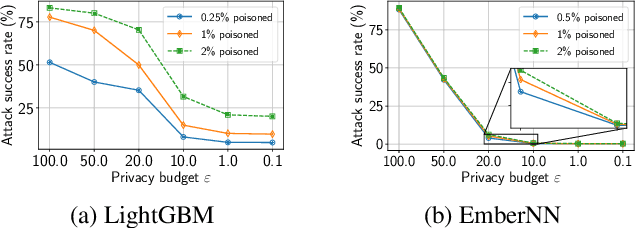
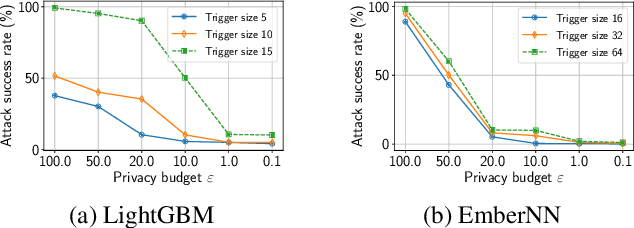
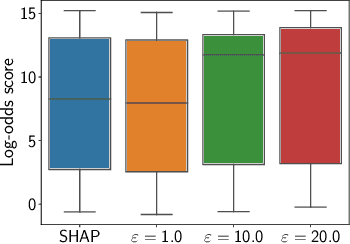
Recent development in the field of explainable artificial intelligence (XAI) has helped improve trust in Machine-Learning-as-a-Service (MLaaS) systems, in which an explanation is provided together with the model prediction in response to each query. However, XAI also opens a door for adversaries to gain insights into the black-box models in MLaaS, thereby making the models more vulnerable to several attacks. For example, feature-based explanations (e.g., SHAP) could expose the top important features that a black-box model focuses on. Such disclosure has been exploited to craft effective backdoor triggers against malware classifiers. To address this trade-off, we introduce a new concept of achieving local differential privacy (LDP) in the explanations, and from that we establish a defense, called XRand, against such attacks. We show that our mechanism restricts the information that the adversary can learn about the top important features, while maintaining the faithfulness of the explanations.