 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Guided Reasoning with Large Language Models for Vietnamese Speech Emotion Recognition
Apr 02, 2026Vietnamese Speech Emotion Recognition (SER) remains challenging due to ambiguous acoustic patterns and the lack of reliable annotated data, especially in real-world conditions where emotional boundaries are not clearly separable. To address this problem, this paper proposes a human-machine collaborative framework that integrates human knowledge into the learning process rather than relying solely on data-driven models. The proposed framework is centered around LLM-based reasoning, where acoustic feature-based models are used to provide auxiliary signals such as confidence and feature-level evidence. A confidence-based routing mechanism is introduced to distinguish between easy and ambiguous samples, allowing uncertain cases to be delegated to LLMs for deeper reasoning guided by structured rules derived from human annotation behavior. In addition, an iterative refinement strategy is employed to continuously improve system performance through error analysis and rule updates. Experiments are conducted on a Vietnamese speech dataset of 2,764 samples across three emotion classes (calm, angry, panic), with high inter-annotator agreement (Fleiss Kappa = 0.8574), ensuring reliable ground truth. The proposed method achieves strong performance, reaching up to 86.59% accuracy and Macro F1 around 0.85-0.86, demonstrating its effectiveness in handling ambiguous and hard-to-classify cases. Overall, this work highlights the importance of combining data-driven models with human reasoning, providing a robust and model-agnostic approach for speech emotion recognition in low-resource settings.
Swift Hydra: Self-Reinforcing Generative Framework for Anomaly Detection with Multiple Mamba Models
Mar 09, 2025



Despite a plethora of anomaly detection models developed over the years, their ability to generalize to unseen anomalies remains an issue, particularly in critical systems. This paper aims to address this challenge by introducing Swift Hydra, a new framework for training an anomaly detection method based on generative AI and reinforcement learning (RL). Through featuring an RL policy that operates on the latent variables of a generative model, the framework synthesizes novel and diverse anomaly samples that are capable of bypassing a detection model. These generated synthetic samples are, in turn, used to augment the detection model, further improving its ability to handle challenging anomalies. Swift Hydra also incorporates Mamba models structured as a Mixture of Experts (MoE) to enable scalable adaptation of the number of Mamba experts based on data complexity, effectively capturing diverse feature distributions without increasing the model's inference time. Empirical evaluations on ADBench benchmark demonstrate that Swift Hydra outperforms other state-of-the-art anomaly detection models while maintaining a relatively short inference time. From these results, our research highlights a new and auspicious paradigm of integrating RL and generative AI for advancing anomaly detection.
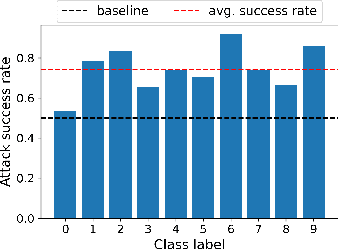
XSub: Explanation-Driven Adversarial Attack against Blackbox Classifiers via Feature Substitution
Sep 13, 2024Despite its significant benefits in enhancing the transparency and trustworthiness of artificial intelligence (AI) systems, explainable AI (XAI) has yet to reach its full potential in real-world applications. One key challenge is that XAI can unintentionally provide adversaries with insights into black-box models, inevitably increasing their vulnerability to various attacks. In this paper, we develop a novel explanation-driven adversarial attack against black-box classifiers based on feature substitution, called XSub. The key idea of XSub is to strategically replace important features (identified via XAI) in the original sample with corresponding important features from a "golden sample" of a different label, thereby increasing the likelihood of the model misclassifying the perturbed sample. The degree of feature substitution is adjustable, allowing us to control how much of the original samples information is replaced. This flexibility effectively balances a trade-off between the attacks effectiveness and its stealthiness. XSub is also highly cost-effective in that the number of required queries to the prediction model and the explanation model in conducting the attack is in O(1). In addition, XSub can be easily extended to launch backdoor attacks in case the attacker has access to the models training data. Our evaluation demonstrates that XSub is not only effective and stealthy but also cost-effective, enabling its application across a wide range of AI models.
Detection of False Data Injection Attacks (FDIA) on Power Dynamical Systems With a State Prediction Method
Sep 06, 2024



With the deeper penetration of inverter-based resources in power systems, false data injection attacks (FDIA) are a growing cyber-security concern. They have the potential to disrupt the system's stability like frequency stability, thereby leading to catastrophic failures. Therefore, an FDIA detection method would be valuable to protect power systems. FDIAs typically induce a discrepancy between the desired and the effective behavior of the power system dynamics. A suitable detection method can leverage power dynamics predictions to identify whether such a discrepancy was induced by an FDIA. This work investigates the efficacy of temporal and spatio-temporal state prediction models, such as Long Short-Term Memory (LSTM) and a combination of Graph Neural Networks (GNN) with LSTM, for predicting frequency dynamics in the absence of an FDIA but with noisy measurements, and thereby identify FDIA events. For demonstration purposes, the IEEE 39 New England Kron-reduced model simulated with a swing equation is considered. It is shown that the proposed state prediction models can be used as a building block for developing an effective FDIA detection method that can maintain high detection accuracy across various attack and deployment settings. It is also shown how the FDIA detection should be deployed to limit its exposure to detection inaccuracies and mitigate its computational burden.
SysCaps: Language Interfaces for Simulation Surrogates of Complex Systems
May 30, 2024



Data-driven simulation surrogates help computational scientists study complex systems. They can also help inform impactful policy decisions. We introduce a learning framework for surrogate modeling where language is used to interface with the underlying system being simulated. We call a language description of a system a "system caption", or SysCap. To address the lack of datasets of paired natural language SysCaps and simulation runs, we use large language models (LLMs) to synthesize high-quality captions. Using our framework, we train multimodal text and timeseries regression models for two real-world simulators of complex energy systems. Our experiments demonstrate the feasibility of designing language interfaces for real-world surrogate models at comparable accuracy to standard baselines. We qualitatively and quantitatively show that SysCaps unlock text-prompt-style surrogate modeling and new generalization abilities beyond what was previously possible. We will release the generated SysCaps datasets and our code to support follow-on studies.
Analysis of Privacy Leakage in Federated Large Language Models
Mar 02, 2024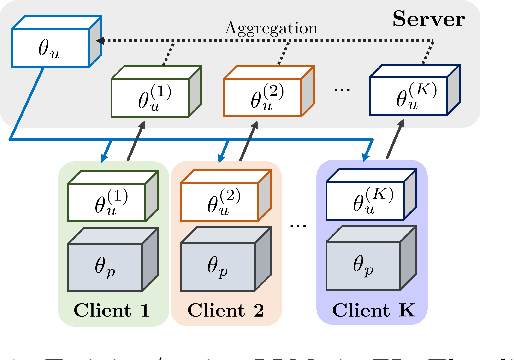



With the rapid adoption of Federated Learning (FL) as the training and tuning protocol for applications utilizing Large Language Models (LLMs), recent research highlights the need for significant modifications to FL to accommodate the large-scale of LLMs. While substantial adjustments to the protocol have been introduced as a response, comprehensive privacy analysis for the adapted FL protocol is currently lacking. To address this gap, our work delves into an extensive examination of the privacy analysis of FL when used for training LLMs, both from theoretical and practical perspectives. In particular, we design two active membership inference attacks with guaranteed theoretical success rates to assess the privacy leakages of various adapted FL configurations. Our theoretical findings are translated into practical attacks, revealing substantial privacy vulnerabilities in popular LLMs, including BERT, RoBERTa, DistilBERT, and OpenAI's GPTs, across multiple real-world language datasets. Additionally, we conduct thorough experiments to evaluate the privacy leakage of these models when data is protected by state-of-the-art differential privacy (DP) mechanisms.
OASIS: Offsetting Active Reconstruction Attacks in Federated Learning
Nov 23, 2023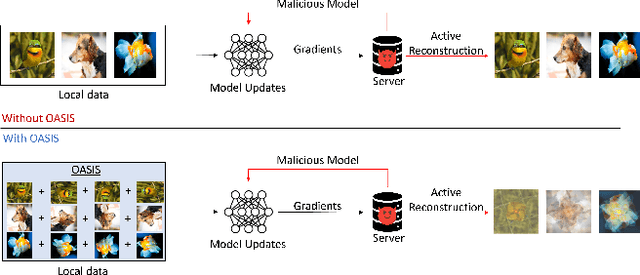



Federated Learning (FL) has garnered significant attention for its potential to protect user privacy while enhancing model training efficiency. However, recent research has demonstrated that FL protocols can be easily compromised by active reconstruction attacks executed by dishonest servers. These attacks involve the malicious modification of global model parameters, allowing the server to obtain a verbatim copy of users' private data by inverting their gradient updates. Tackling this class of attack remains a crucial challenge due to the strong threat model. In this paper, we propose OASIS, a defense mechanism based on image augmentation that effectively counteracts active reconstruction attacks while preserving model performance. We first uncover the core principle of gradient inversion that enables these attacks and theoretically identify the main conditions by which the defense can be robust regardless of the attack strategies. We then construct OASIS with image augmentation showing that it can undermine the attack principle. Comprehensive evaluations demonstrate the efficacy of OASIS highlighting its feasibility as a solution.
Active Membership Inference Attack under Local Differential Privacy in Federated Learning
Feb 24, 2023


Federated learning (FL) was originally regarded as a framework for collaborative learning among clients with data privacy protection through a coordinating server. In this paper, we propose a new active membership inference (AMI) attack carried out by a dishonest server in FL. In AMI attacks, the server crafts and embeds malicious parameters into global models to effectively infer whether a target data sample is included in a client's private training data or not. By exploiting the correlation among data features through a non-linear decision boundary, AMI attacks with a certified guarantee of success can achieve severely high success rates under rigorous local differential privacy (LDP) protection; thereby exposing clients' training data to significant privacy risk. Theoretical and experimental results on several benchmark datasets show that adding sufficient privacy-preserving noise to prevent our attack would significantly damage FL's model utility.
XRand: Differentially Private Defense against Explanation-Guided Attacks
Dec 14, 2022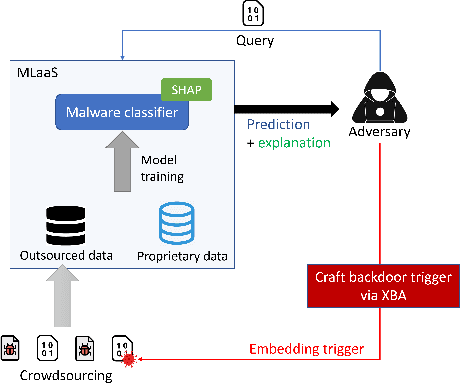
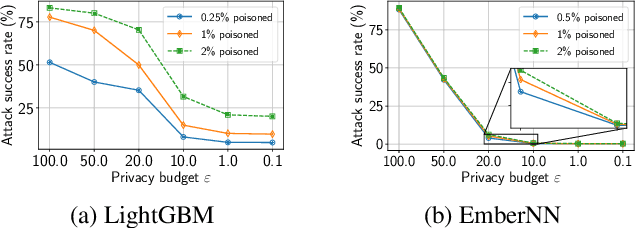
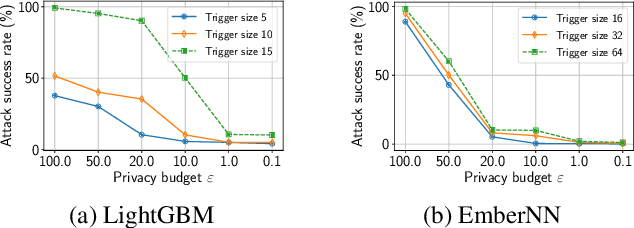
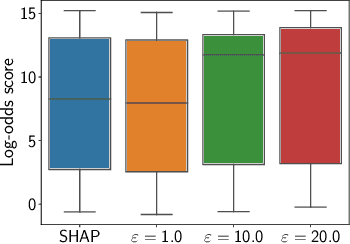
Recent development in the field of explainable artificial intelligence (XAI) has helped improve trust in Machine-Learning-as-a-Service (MLaaS) systems, in which an explanation is provided together with the model prediction in response to each query. However, XAI also opens a door for adversaries to gain insights into the black-box models in MLaaS, thereby making the models more vulnerable to several attacks. For example, feature-based explanations (e.g., SHAP) could expose the top important features that a black-box model focuses on. Such disclosure has been exploited to craft effective backdoor triggers against malware classifiers. To address this trade-off, we introduce a new concept of achieving local differential privacy (LDP) in the explanations, and from that we establish a defense, called XRand, against such attacks. We show that our mechanism restricts the information that the adversary can learn about the top important features, while maintaining the faithfulness of the explanations.
Blockchain-based Secure Client Selection in Federated Learning
May 11, 2022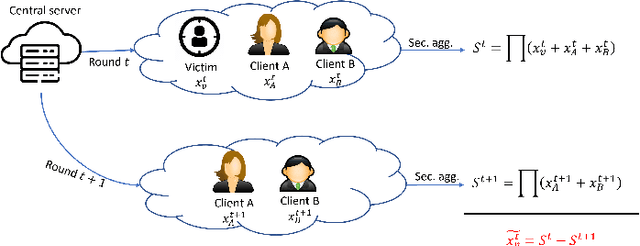
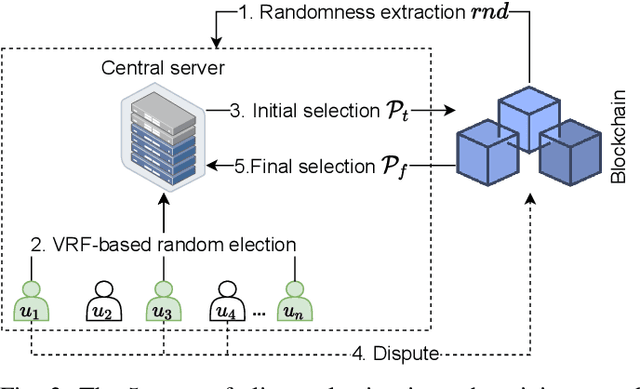
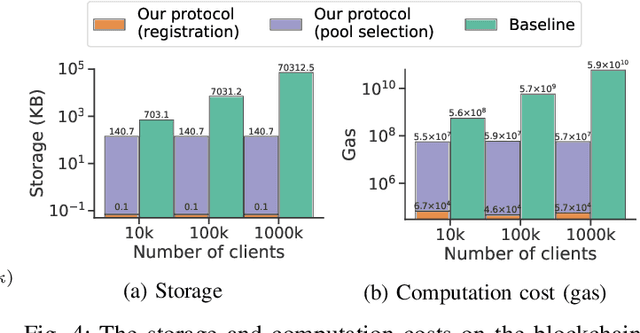
Despite the great potential of Federated Learning (FL) in large-scale distributed learning, the current system is still subject to several privacy issues due to the fact that local models trained by clients are exposed to the central server. Consequently, secure aggregation protocols for FL have been developed to conceal the local models from the server. However, we show that, by manipulating the client selection process, the server can circumvent the secure aggregation to learn the local models of a victim client, indicating that secure aggregation alone is inadequate for privacy protection. To tackle this issue, we leverage blockchain technology to propose a verifiable client selection protocol. Owing to the immutability and transparency of blockchain, our proposed protocol enforces a random selection of clients, making the server unable to control the selection process at its discretion. We present security proofs showing that our protocol is secure against this attack. Additionally, we conduct several experiments on an Ethereum-like blockchain to demonstrate the feasibility and practicality of our solution.