 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTT-LoRA MoE: Unifying Parameter-Efficient Fine-Tuning and Sparse Mixture-of-Experts
Apr 29, 2025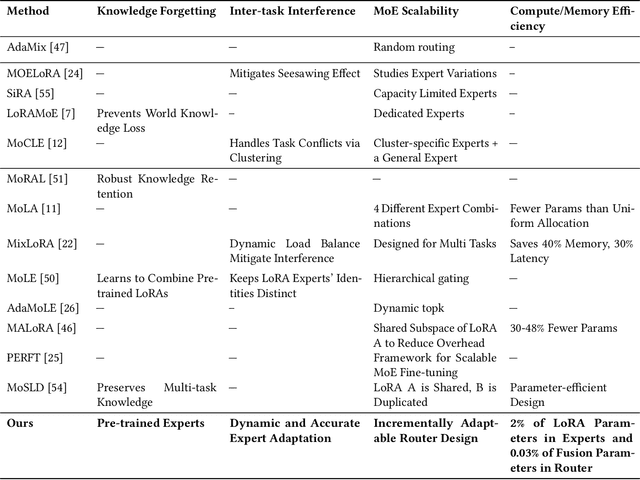
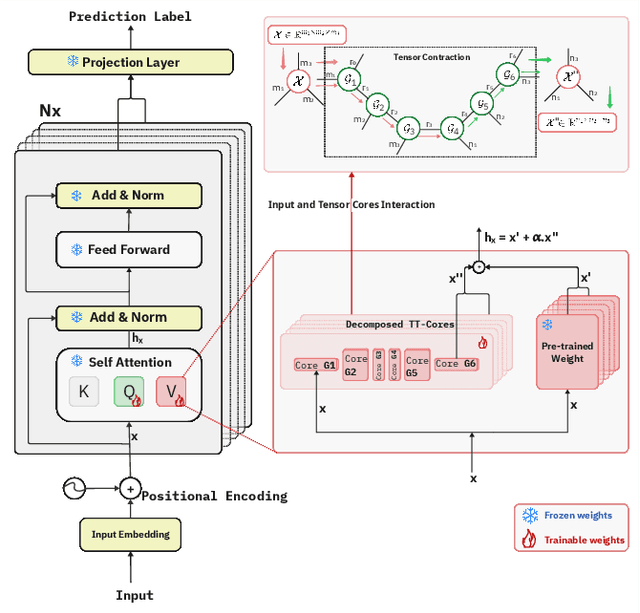
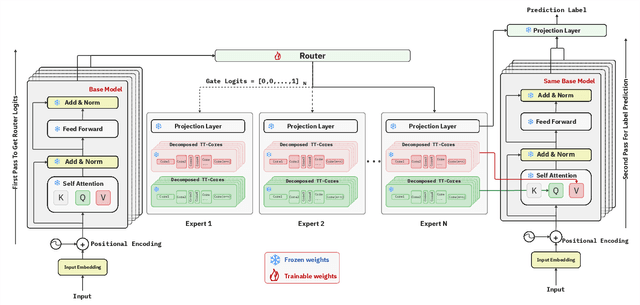

We propose Tensor-Trained Low-Rank Adaptation Mixture of Experts (TT-LoRA MoE), a novel computational framework integrating Parameter-Efficient Fine-Tuning (PEFT) with sparse MoE routing to address scalability challenges in large model deployments. Unlike traditional MoE approaches, which face substantial computational overhead as expert counts grow, TT-LoRA MoE decomposes training into two distinct, optimized stages. First, we independently train lightweight, tensorized low-rank adapters (TT-LoRA experts), each specialized for specific tasks. Subsequently, these expert adapters remain frozen, eliminating inter-task interference and catastrophic forgetting in multi-task setting. A sparse MoE router, trained separately, dynamically leverages base model representations to select exactly one specialized adapter per input at inference time, automating expert selection without explicit task specification. Comprehensive experiments confirm our architecture retains the memory efficiency of low-rank adapters, seamlessly scales to large expert pools, and achieves robust task-level optimization. This structured decoupling significantly enhances computational efficiency and flexibility: uses only 2% of LoRA, 0.3% of Adapters and 0.03% of AdapterFusion parameters and outperforms AdapterFusion by 4 value in multi-tasking, enabling practical and scalable multi-task inference deployments.
CHARME: A chain-based reinforcement learning approach for the minor embedding problem
Jun 11, 2024
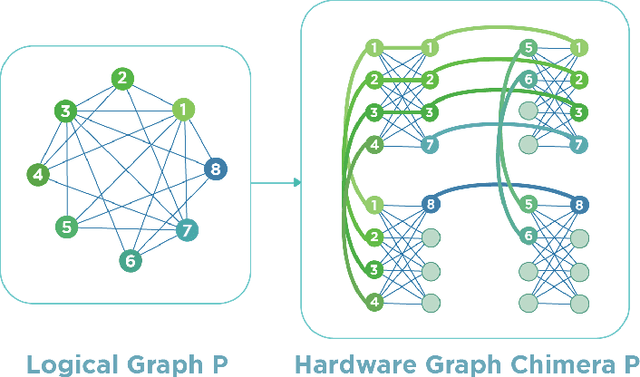
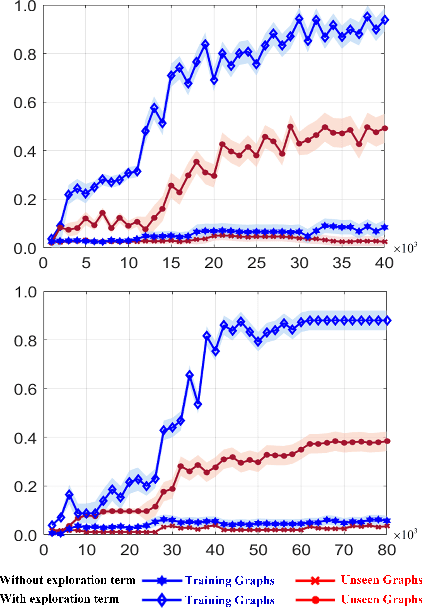

Quantum Annealing (QA) holds great potential for solving combinatorial optimization problems efficiently. However, the effectiveness of QA algorithms heavily relies on the embedding of problem instances, represented as logical graphs, into the quantum unit processing (QPU) whose topology is in form of a limited connectivity graph, known as the minor embedding Problem. Existing methods for the minor embedding problem suffer from scalability issues when confronted with larger problem sizes. In this paper, we propose a novel approach utilizing Reinforcement Learning (RL) techniques to address the minor embedding problem, named CHARME. CHARME includes three key components: a Graph Neural Network (GNN) architecture for policy modeling, a state transition algorithm ensuring solution validity, and an order exploration strategy for effective training. Through comprehensive experiments on synthetic and real-world instances, we demonstrate that the efficiency of our proposed order exploration strategy as well as our proposed RL framework, CHARME. In details, CHARME yields superior solutions compared to fast embedding methods such as Minorminer and ATOM. Moreover, our method surpasses the OCT-based approach, known for its slower runtime but high-quality solutions, in several cases. In addition, our proposed exploration enhances the efficiency of the training of the CHARME framework by providing better solutions compared to the greedy strategy.
Analysis of Privacy Leakage in Federated Large Language Models
Mar 02, 2024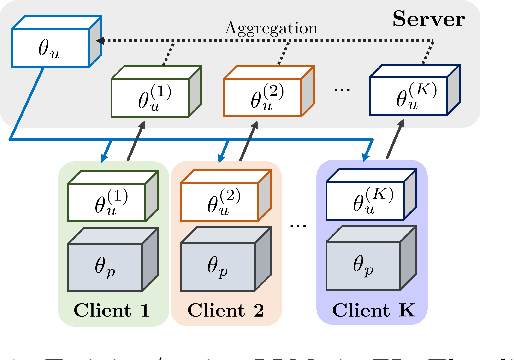



With the rapid adoption of Federated Learning (FL) as the training and tuning protocol for applications utilizing Large Language Models (LLMs), recent research highlights the need for significant modifications to FL to accommodate the large-scale of LLMs. While substantial adjustments to the protocol have been introduced as a response, comprehensive privacy analysis for the adapted FL protocol is currently lacking. To address this gap, our work delves into an extensive examination of the privacy analysis of FL when used for training LLMs, both from theoretical and practical perspectives. In particular, we design two active membership inference attacks with guaranteed theoretical success rates to assess the privacy leakages of various adapted FL configurations. Our theoretical findings are translated into practical attacks, revealing substantial privacy vulnerabilities in popular LLMs, including BERT, RoBERTa, DistilBERT, and OpenAI's GPTs, across multiple real-world language datasets. Additionally, we conduct thorough experiments to evaluate the privacy leakage of these models when data is protected by state-of-the-art differential privacy (DP) mechanisms.
On the Limit of Explaining Black-box Temporal Graph Neural Networks
Dec 02, 2022Temporal Graph Neural Network (TGNN) has been receiving a lot of attention recently due to its capability in modeling time-evolving graph-related tasks. Similar to Graph Neural Networks, it is also non-trivial to interpret predictions made by a TGNN due to its black-box nature. A major approach tackling this problems in GNNs is by analyzing the model' responses on some perturbations of the model's inputs, called perturbation-based explanation methods. While these methods are convenient and flexible since they do not need internal access to the model, does this lack of internal access prevent them from revealing some important information of the predictions? Motivated by that question, this work studies the limit of some classes of perturbation-based explanation methods. Particularly, by constructing some specific instances of TGNNs, we show (i) node-perturbation cannot reliably identify the paths carrying out the prediction, (ii) edge-perturbation is not reliable in determining all nodes contributing to the prediction and (iii) perturbing both nodes and edges does not reliably help us identify the graph's components carrying out the temporal aggregation in TGNNs.
EMaP: Explainable AI with Manifold-based Perturbations
Sep 18, 2022



In the last few years, many explanation methods based on the perturbations of input data have been introduced to improve our understanding of decisions made by black-box models. The goal of this work is to introduce a novel perturbation scheme so that more faithful and robust explanations can be obtained. Our study focuses on the impact of perturbing directions on the data topology. We show that perturbing along the orthogonal directions of the input manifold better preserves the data topology, both in the worst-case analysis of the discrete Gromov-Hausdorff distance and in the average-case analysis via persistent homology. From those results, we introduce EMaP algorithm, realizing the orthogonal perturbation scheme. Our experiments show that EMaP not only improves the explainers' performance but also helps them overcome a recently-developed attack against perturbation-based methods.
NeuCEPT: Locally Discover Neural Networks' Mechanism via Critical Neurons Identification with Precision Guarantee
Sep 18, 2022


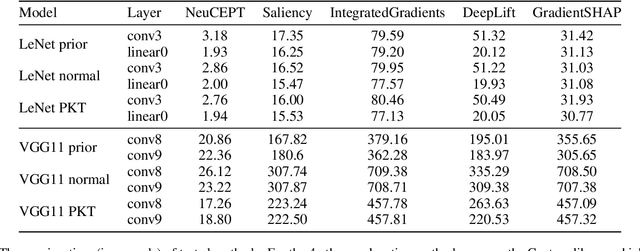
Despite recent studies on understanding deep neural networks (DNNs), there exists numerous questions on how DNNs generate their predictions. Especially, given similar predictions on different input samples, are the underlying mechanisms generating those predictions the same? In this work, we propose NeuCEPT, a method to locally discover critical neurons that play a major role in the model's predictions and identify model's mechanisms in generating those predictions. We first formulate a critical neurons identification problem as maximizing a sequence of mutual-information objectives and provide a theoretical framework to efficiently solve for critical neurons while keeping the precision under control. NeuCEPT next heuristically learns different model's mechanisms in an unsupervised manner. Our experimental results show that neurons identified by NeuCEPT not only have strong influence on the model's predictions but also hold meaningful information about model's mechanisms.
An Explainer for Temporal Graph Neural Networks
Sep 02, 2022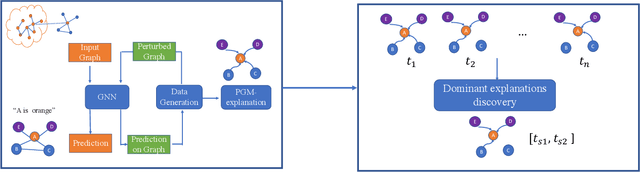
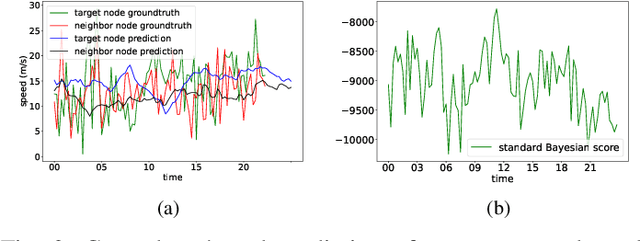
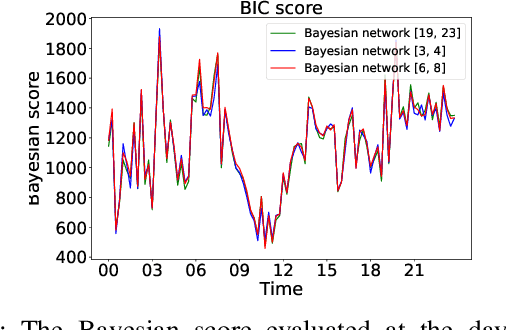
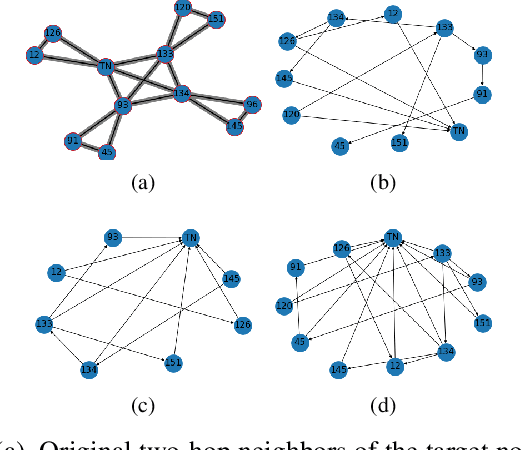
Temporal graph neural networks (TGNNs) have been widely used for modeling time-evolving graph-related tasks due to their ability to capture both graph topology dependency and non-linear temporal dynamic. The explanation of TGNNs is of vital importance for a transparent and trustworthy model. However, the complex topology structure and temporal dependency make explaining TGNN models very challenging. In this paper, we propose a novel explainer framework for TGNN models. Given a time series on a graph to be explained, the framework can identify dominant explanations in the form of a probabilistic graphical model in a time period. Case studies on the transportation domain demonstrate that the proposed approach can discover dynamic dependency structures in a road network for a time period.
Learning Interpretation with Explainable Knowledge Distillation
Nov 12, 2021
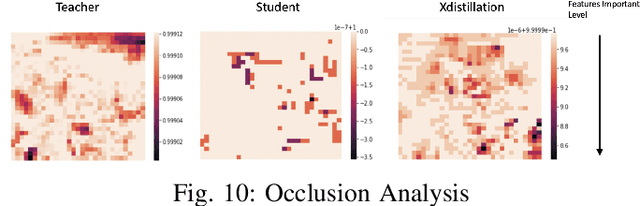

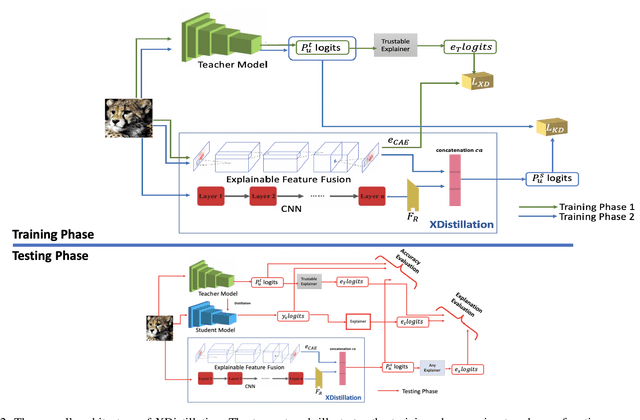
Knowledge Distillation (KD) has been considered as a key solution in model compression and acceleration in recent years. In KD, a small student model is generally trained from a large teacher model by minimizing the divergence between the probabilistic outputs of the two. However, as demonstrated in our experiments, existing KD methods might not transfer critical explainable knowledge of the teacher to the student, i.e. the explanations of predictions made by the two models are not consistent. In this paper, we propose a novel explainable knowledge distillation model, called XDistillation, through which both the performance the explanations' information are transferred from the teacher model to the student model. The XDistillation model leverages the idea of convolutional autoencoders to approximate the teacher explanations. Our experiments shows that models trained by XDistillation outperform those trained by conventional KD methods not only in term of predictive accuracy but also faithfulness to the teacher models.
PGM-Explainer: Probabilistic Graphical Model Explanations for Graph Neural Networks
Oct 12, 2020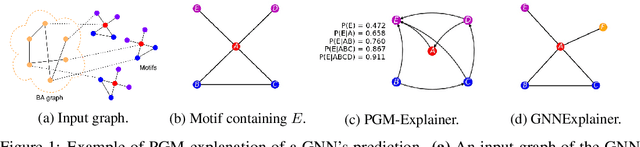



In Graph Neural Networks (GNNs), the graph structure is incorporated into the learning of node representations. This complex structure makes explaining GNNs' predictions become much more challenging. In this paper, we propose PGM-Explainer, a Probabilistic Graphical Model (PGM) model-agnostic explainer for GNNs. Given a prediction to be explained, PGM-Explainer identifies crucial graph components and generates an explanation in form of a PGM approximating that prediction. Different from existing explainers for GNNs where the explanations are drawn from a set of linear functions of explained features, PGM-Explainer is able to demonstrate the dependencies of explained features in form of conditional probabilities. Our theoretical analysis shows that the PGM generated by PGM-Explainer includes the Markov-blanket of the target prediction, i.e. including all its statistical information. We also show that the explanation returned by PGM-Explainer contains the same set of independence statements in the perfect map. Our experiments on both synthetic and real-world datasets show that PGM-Explainer achieves better performance than existing explainers in many benchmark tasks.
Evaluating Explainers via Perturbation
Jun 05, 2019
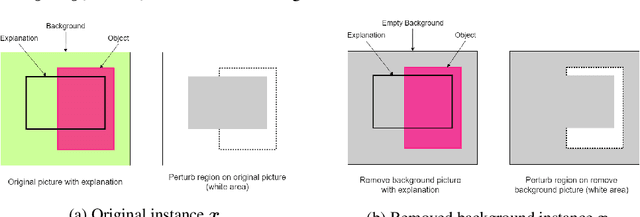
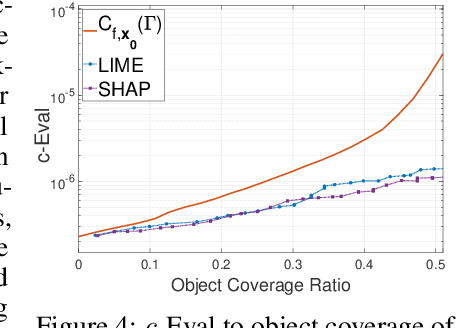
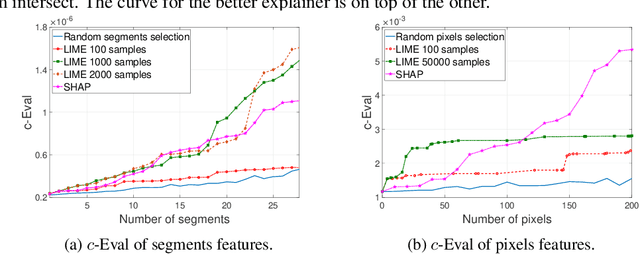
Due to high complexity of many modern machine learning models such as deep convolutional networks, understanding the cause of model's prediction is critical. Many explainers have been designed to give us more insights on the decision of complex classifiers. However, there is no common ground on evaluating the quality of different classification methods. Motivated by the needs for comprehensive evaluation, we introduce the c-Eval metric and the corresponding framework to quantify the explainer's quality on feature-based explainers of machine learning image classifiers. Given a prediction and the corresponding explanation on that prediction, c-Eval is the minimum-power perturbation that successfully alters the prediction while keeping the explanation's features unchanged. We also provide theoretical analysis linking the proposed parameter with the portion of predicted object covered by the explanation. Using a heuristic approach, we introduce the c-Eval plot, which not only displays a strong connection between c-Eval and explainers' quality, but also serves as a low-complexity approach of assessing explainers. We finally conduct extensive experiments of explainers on three different datasets in order to support the adoption of c-Eval in evaluating explainers' performance.