 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLI:Non-uniform Linear Interpolation Approximation of Nonlinear Operations for Efficient LLMs Inference
Feb 03, 2026Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of tasks, but their deployment is often constrained by substantial memory footprints and computational costs. While prior work has achieved significant progress in compressing and accelerating linear layers, nonlinear layers-such as SiLU, RMSNorm, and Softmax-still heavily depend on high-precision floating-point operations. In this paper, we propose a calibration-free, dynamic-programming-optimal, and hardware-friendly framework called Non-uniform Linear Interpolation (NLI). NLI is capable of efficiently approximating a variety of nonlinear functions, enabling seamless integration into LLMs and other deep neural networks with almost no loss in accuracy. NLI ingeniously recasts cutpoint selection as a dynamic-programming problem, achieving the globally minimal interpolation error in O(MxN2) time via Bellman's optimality principle. Based on the NLI algorithm, we also design and implement a plug-and-play universal nonlinear computation unit. Hardware experiments demonstrate that the NLI Engine achieves more than 4x improvement in computational efficiency compared to the state-of-the-art designs.
$D^2Prune$: Sparsifying Large Language Models via Dual Taylor Expansion and Attention Distribution Awareness
Jan 14, 2026Large language models (LLMs) face significant deployment challenges due to their massive computational demands. % While pruning offers a promising compression solution, existing methods suffer from two critical limitations: (1) They neglect activation distribution shifts between calibration data and test data, resulting in inaccurate error estimations; (2) They overlook the long-tail distribution characteristics of activations in the attention module. To address these limitations, this paper proposes a novel pruning method, $D^2Prune$. First, we propose a dual Taylor expansion-based method that jointly models weight and activation perturbations for precise error estimation, leading to precise pruning mask selection and weight updating and facilitating error minimization during pruning. % Second, we propose an attention-aware dynamic update strategy that preserves the long-tail attention pattern by jointly minimizing the KL divergence of attention distributions and the reconstruction error. Extensive experiments show that $D^2Prune$ consistently outperforms SOTA methods across various LLMs (e.g., OPT-125M, LLaMA2/3, and Qwen3). Moreover, the dynamic attention update mechanism also generalizes well to ViT-based vision models like DeiT, achieving superior accuracy on ImageNet-1K.
VNU-Bench: A Benchmarking Dataset for Multi-Source Multimodal News Video Understanding
Jan 06, 2026News videos are carefully edited multimodal narratives that combine narration, visuals, and external quotations into coherent storylines. In recent years, there have been significant advances in evaluating multimodal large language models (MLLMs) for news video understanding. However, existing benchmarks largely focus on single-source, intra-video reasoning, where each report is processed in isolation. In contrast, real-world news consumption is inherently multi-sourced: the same event is reported by different outlets with complementary details, distinct narrative choices, and sometimes conflicting claims that unfold over time. Robust news understanding, therefore, requires models to compare perspectives from different sources, align multimodal evidence across sources, and synthesize multi-source information. To fill this gap, we introduce VNU-Bench, the first benchmark for multi-source, cross-video understanding in the news domain. We design a set of new question types that are unique in testing models' ability of understanding multi-source multimodal news from a variety of different angles. We design a novel hybrid human-model QA generation process that addresses the issues of scalability and quality control in building a large dataset for cross-source news understanding. The dataset comprises 429 news groups, 1,405 videos, and 2,501 high-quality questions. Comprehensive evaluation of both closed- and open-source multimodal models shows that VNU-Bench poses substantial challenges for current MLLMs.
EarthLink: A Self-Evolving AI Agent for Climate Science
Jul 24, 2025


Modern Earth science is at an inflection point. The vast, fragmented, and complex nature of Earth system data, coupled with increasingly sophisticated analytical demands, creates a significant bottleneck for rapid scientific discovery. Here we introduce EarthLink, the first AI agent designed as an interactive copilot for Earth scientists. It automates the end-to-end research workflow, from planning and code generation to multi-scenario analysis. Unlike static diagnostic tools, EarthLink can learn from user interaction, continuously refining its capabilities through a dynamic feedback loop. We validated its performance on a number of core scientific tasks of climate change, ranging from model-observation comparisons to the diagnosis of complex phenomena. In a multi-expert evaluation, EarthLink produced scientifically sound analyses and demonstrated an analytical competency that was rated as comparable to specific aspects of a human junior researcher's workflow. Additionally, its transparent, auditable workflows and natural language interface empower scientists to shift from laborious manual execution to strategic oversight and hypothesis generation. EarthLink marks a pivotal step towards an efficient, trustworthy, and collaborative paradigm for Earth system research in an era of accelerating global change. The system is accessible at our website https://earthlink.intern-ai.org.cn.
DecoyDB: A Dataset for Graph Contrastive Learning in Protein-Ligand Binding Affinity Prediction
Jul 08, 2025Predicting the binding affinity of protein-ligand complexes plays a vital role in drug discovery. Unfortunately, progress has been hindered by the lack of large-scale and high-quality binding affinity labels. The widely used PDBbind dataset has fewer than 20K labeled complexes. Self-supervised learning, especially graph contrastive learning (GCL), provides a unique opportunity to break the barrier by pre-training graph neural network models based on vast unlabeled complexes and fine-tuning the models on much fewer labeled complexes. However, the problem faces unique challenges, including a lack of a comprehensive unlabeled dataset with well-defined positive/negative complex pairs and the need to design GCL algorithms that incorporate the unique characteristics of such data. To fill the gap, we propose DecoyDB, a large-scale, structure-aware dataset specifically designed for self-supervised GCL on protein-ligand complexes. DecoyDB consists of high-resolution ground truth complexes (less than 2.5 Angstrom) and diverse decoy structures with computationally generated binding poses that range from realistic to suboptimal (negative pairs). Each decoy is annotated with a Root Mean Squared Deviation (RMSD) from the native pose. We further design a customized GCL framework to pre-train graph neural networks based on DecoyDB and fine-tune the models with labels from PDBbind. Extensive experiments confirm that models pre-trained with DecoyDB achieve superior accuracy, label efficiency, and generalizability.
ReChisel: Effective Automatic Chisel Code Generation by LLM with Reflection
May 26, 2025Coding with hardware description languages (HDLs) such as Verilog is a time-intensive and laborious task. With the rapid advancement of large language models (LLMs), there is increasing interest in applying LLMs to assist with HDL coding. Recent efforts have demonstrated the potential of LLMs in translating natural language to traditional HDL Verilog. Chisel, a next-generation HDL based on Scala, introduces higher-level abstractions, facilitating more concise, maintainable, and scalable hardware designs. However, the potential of using LLMs for Chisel code generation remains largely unexplored. This work proposes ReChisel, an LLM-based agentic system designed to enhance the effectiveness of Chisel code generation. ReChisel incorporates a reflection mechanism to iteratively refine the quality of generated code using feedback from compilation and simulation processes, and introduces an escape mechanism to break free from non-progress loops. Experiments demonstrate that ReChisel significantly improves the success rate of Chisel code generation, achieving performance comparable to state-of-the-art LLM-based agentic systems for Verilog code generation.
VeriDebug: A Unified LLM for Verilog Debugging via Contrastive Embedding and Guided Correction
Apr 27, 2025Large Language Models (LLMs) have demonstrated remarkable potential in debugging for various programming languages. However, the application of LLMs to Verilog debugging remains insufficiently explored. Here, we present VeriDebug, an approach that integrates contrastive representation and guided correction capabilities for automated Verilog debugging. Unlike existing methods, VeriDebug employs an embedding-based technique to accurately retrieve internal information, followed by bug-fixing. VeriDebug unifies Verilog bug detection and correction through a shared parameter space. By simultaneously learning bug patterns and fixes, it streamlines debugging via contrastive embedding and guided correction. Empirical results show the efficacy of VeriDebug in enhancing Verilog debugging. Our VeriDebugLoc, Type model achieves 64.7 accuracy in bug fixing (Acc1), a significant improvement from the existing open-source SOTAs 11.3. This performance not only outperforms open-source alternatives but also exceeds larger closed-source models like GPT-3.5-turbo (36.6), offering a more accurate alternative to conventional debugging methods.
Insights from Verification: Training a Verilog Generation LLM with Reinforcement Learning with Testbench Feedback
Apr 22, 2025Large language models (LLMs) have shown strong performance in Verilog generation from natural language description. However, ensuring the functional correctness of the generated code remains a significant challenge. This paper introduces a method that integrates verification insights from testbench into the training of Verilog generation LLMs, aligning the training with the fundamental goal of hardware design: functional correctness. The main obstacle in using LLMs for Verilog code generation is the lack of sufficient functional verification data, particularly testbenches paired with design specifications and code. To address this problem, we introduce an automatic testbench generation pipeline that decomposes the process and uses feedback from the Verilog compiler simulator (VCS) to reduce hallucination and ensure correctness. We then use the testbench to evaluate the generated codes and collect them for further training, where verification insights are introduced. Our method applies reinforcement learning (RL), specifically direct preference optimization (DPO), to align Verilog code generation with functional correctness by training preference pairs based on testbench outcomes. In evaluations on VerilogEval-Machine, VerilogEval-Human, RTLLM v1.1, RTLLM v2, and VerilogEval v2, our approach consistently outperforms state-of-the-art baselines in generating functionally correct Verilog code. We open source all training code, data, and models at https://anonymous.4open.science/r/VeriPrefer-E88B.
Unlocking a New Rust Programming Experience: Fast and Slow Thinking with LLMs to Conquer Undefined Behaviors
Mar 04, 2025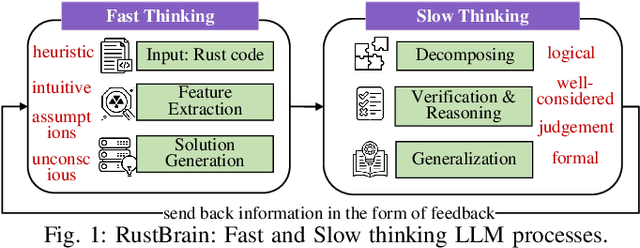
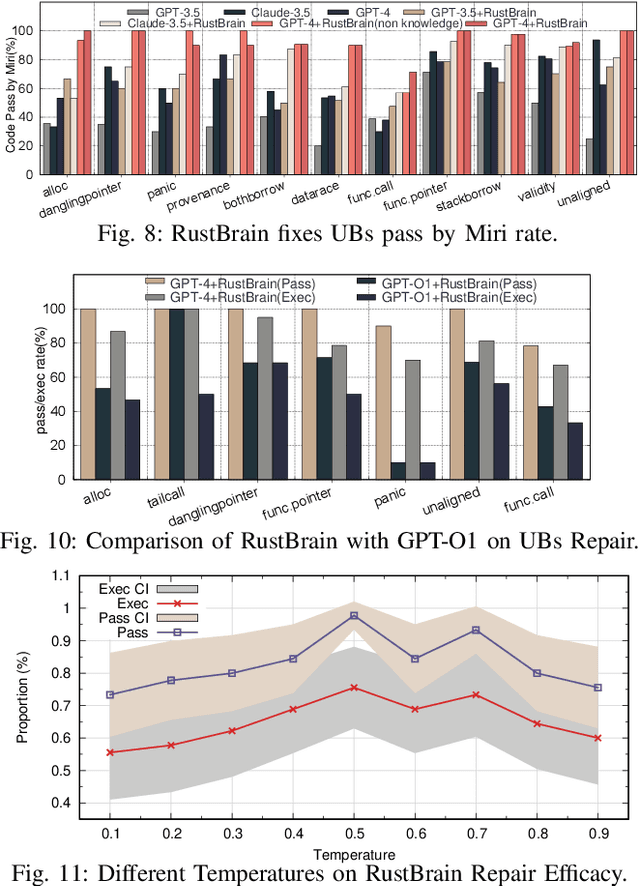
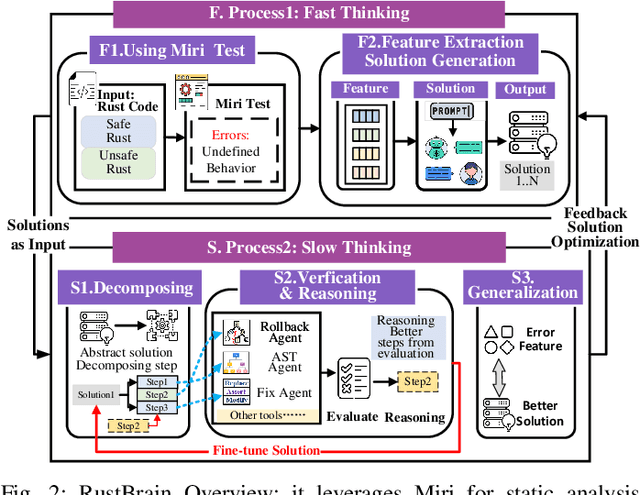

To provide flexibility and low-level interaction capabilities, the unsafe tag in Rust is essential in many projects, but undermines memory safety and introduces Undefined Behaviors (UBs) that reduce safety. Eliminating these UBs requires a deep understanding of Rust's safety rules and strong typing. Traditional methods require depth analysis of code, which is laborious and depends on knowledge design. The powerful semantic understanding capabilities of LLM offer new opportunities to solve this problem. Although existing large model debugging frameworks excel in semantic tasks, limited by fixed processes and lack adaptive and dynamic adjustment capabilities. Inspired by the dual process theory of decision-making (Fast and Slow Thinking), we present a LLM-based framework called RustBrain that automatically and flexibly minimizes UBs in Rust projects. Fast thinking extracts features to generate solutions, while slow thinking decomposes, verifies, and generalizes them abstractly. To apply verification and generalization results to solution generation, enabling dynamic adjustments and precise outputs, RustBrain integrates two thinking through a feedback mechanism. Experimental results on Miri dataset show a 94.3% pass rate and 80.4% execution rate, improving flexibility and Rust projects safety.
NVR: Vector Runahead on NPUs for Sparse Memory Access
Feb 19, 2025Deep Neural Networks are increasingly leveraging sparsity to reduce the scaling up of model parameter size. However, reducing wall-clock time through sparsity and pruning remains challenging due to irregular memory access patterns, leading to frequent cache misses. In this paper, we present NPU Vector Runahead (NVR), a prefetching mechanism tailored for NPUs to address cache miss problems in sparse DNN workloads. Rather than optimising memory patterns with high overhead and poor portability, NVR adapts runahead execution to the unique architecture of NPUs. NVR provides a general micro-architectural solution for sparse DNN workloads without requiring compiler or algorithmic support, operating as a decoupled, speculative, lightweight hardware sub-thread alongside the NPU, with minimal hardware overhead (under 5%). NVR achieves an average 90% reduction in cache misses compared to SOTA prefetching in general-purpose processors, delivering 4x average speedup on sparse workloads versus NPUs without prefetching. Moreover, we investigate the advantages of incorporating a small cache (16KB) into the NPU combined with NVR. Our evaluation shows that expanding this modest cache delivers 5x higher performance benefits than increasing the L2 cache size by the same amount.