 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast AI Surrogate for Coastal Ocean Circulation Models
Oct 19, 2024



Nearly 900 million people live in low-lying coastal zones around the world and bear the brunt of impacts from more frequent and severe hurricanes and storm surges. Oceanographers simulate ocean current circulation along the coasts to develop early warning systems that save lives and prevent loss and damage to property from coastal hazards. Traditionally, such simulations are conducted using coastal ocean circulation models such as the Regional Ocean Modeling System (ROMS), which usually runs on an HPC cluster with multiple CPU cores. However, the process is time-consuming and energy expensive. While coarse-grained ROMS simulations offer faster alternatives, they sacrifice detail and accuracy, particularly in complex coastal environments. Recent advances in deep learning and GPU architecture have enabled the development of faster AI (neural network) surrogates. This paper introduces an AI surrogate based on a 4D Swin Transformer to simulate coastal tidal wave propagation in an estuary for both hindcast and forecast (up to 12 days). Our approach not only accelerates simulations but also incorporates a physics-based constraint to detect and correct inaccurate results, ensuring reliability while minimizing manual intervention. We develop a fully GPU-accelerated workflow, optimizing the model training and inference pipeline on NVIDIA DGX-2 A100 GPUs. Our experiments demonstrate that our AI surrogate reduces the time cost of 12-day forecasting of traditional ROMS simulations from 9,908 seconds (on 512 CPU cores) to 22 seconds (on one A100 GPU), achieving over 450$\times$ speedup while maintaining high-quality simulation results. This work contributes to oceanographic modeling by offering a fast, accurate, and physically consistent alternative to traditional simulation models, particularly for real-time forecasting in rapid disaster response.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
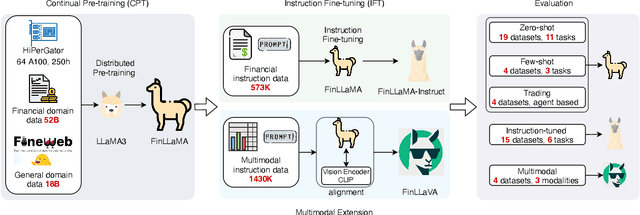
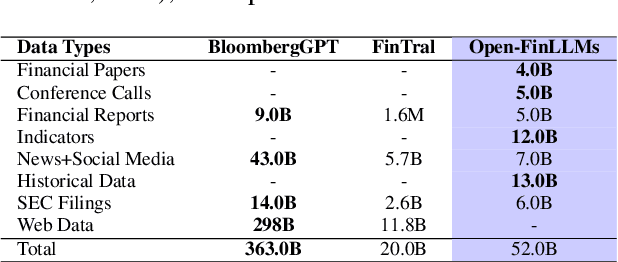
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.