 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast AI Surrogate for Coastal Ocean Circulation Models
Oct 19, 2024



Nearly 900 million people live in low-lying coastal zones around the world and bear the brunt of impacts from more frequent and severe hurricanes and storm surges. Oceanographers simulate ocean current circulation along the coasts to develop early warning systems that save lives and prevent loss and damage to property from coastal hazards. Traditionally, such simulations are conducted using coastal ocean circulation models such as the Regional Ocean Modeling System (ROMS), which usually runs on an HPC cluster with multiple CPU cores. However, the process is time-consuming and energy expensive. While coarse-grained ROMS simulations offer faster alternatives, they sacrifice detail and accuracy, particularly in complex coastal environments. Recent advances in deep learning and GPU architecture have enabled the development of faster AI (neural network) surrogates. This paper introduces an AI surrogate based on a 4D Swin Transformer to simulate coastal tidal wave propagation in an estuary for both hindcast and forecast (up to 12 days). Our approach not only accelerates simulations but also incorporates a physics-based constraint to detect and correct inaccurate results, ensuring reliability while minimizing manual intervention. We develop a fully GPU-accelerated workflow, optimizing the model training and inference pipeline on NVIDIA DGX-2 A100 GPUs. Our experiments demonstrate that our AI surrogate reduces the time cost of 12-day forecasting of traditional ROMS simulations from 9,908 seconds (on 512 CPU cores) to 22 seconds (on one A100 GPU), achieving over 450$\times$ speedup while maintaining high-quality simulation results. This work contributes to oceanographic modeling by offering a fast, accurate, and physically consistent alternative to traditional simulation models, particularly for real-time forecasting in rapid disaster response.
XTSFormer: Cross-Temporal-Scale Transformer for Irregular Time Event Prediction
Feb 03, 2024



Event prediction aims to forecast the time and type of a future event based on a historical event sequence. Despite its significance, several challenges exist, including the irregularity of time intervals between consecutive events, the existence of cycles, periodicity, and multi-scale event interactions, as well as the high computational costs for long event sequences. Existing neural temporal point processes (TPPs) methods do not capture the multi-scale nature of event interactions, which is common in many real-world applications such as clinical event data. To address these issues, we propose the cross-temporal-scale transformer (XTSFormer), designed specifically for irregularly timed event data. Our model comprises two vital components: a novel Feature-based Cycle-aware Time Positional Encoding (FCPE) that adeptly captures the cyclical nature of time, and a hierarchical multi-scale temporal attention mechanism. These scales are determined by a bottom-up clustering algorithm. Extensive experiments on several real-world datasets show that our XTSFormer outperforms several baseline methods in prediction performance.
Spatial Knowledge-Infused Hierarchical Learning: An Application in Flood Mapping on Earth Imagery
Dec 12, 2023
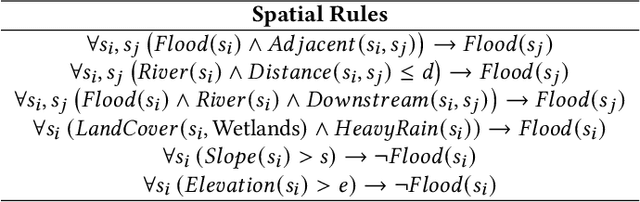


Deep learning for Earth imagery plays an increasingly important role in geoscience applications such as agriculture, ecology, and natural disaster management. Still, progress is often hindered by the limited training labels. Given Earth imagery with limited training labels, a base deep neural network model, and a spatial knowledge base with label constraints, our problem is to infer the full labels while training the neural network. The problem is challenging due to the sparse and noisy input labels, spatial uncertainty within the label inference process, and high computational costs associated with a large number of sample locations. Existing works on neuro-symbolic models focus on integrating symbolic logic into neural networks (e.g., loss function, model architecture, and training label augmentation), but these methods do not fully address the challenges of spatial data (e.g., spatial uncertainty, the trade-off between spatial granularity and computational costs). To bridge this gap, we propose a novel Spatial Knowledge-Infused Hierarchical Learning (SKI-HL) framework that iteratively infers sample labels within a multi-resolution hierarchy. Our framework consists of a module to selectively infer labels in different resolutions based on spatial uncertainty and a module to train neural network parameters with uncertainty-aware multi-instance learning. Extensive experiments on real-world flood mapping datasets show that the proposed model outperforms several baseline methods. The code is available at \url{https://github.com/ZelinXu2000/SKI-HL}.
A Hierarchical Spatial Transformer for Massive Point Samples in Continuous Space
Nov 08, 2023Transformers are widely used deep learning architectures. Existing transformers are mostly designed for sequences (texts or time series), images or videos, and graphs. This paper proposes a novel transformer model for massive (up to a million) point samples in continuous space. Such data are ubiquitous in environment sciences (e.g., sensor observations), numerical simulations (e.g., particle-laden flow, astrophysics), and location-based services (e.g., POIs and trajectories). However, designing a transformer for massive spatial points is non-trivial due to several challenges, including implicit long-range and multi-scale dependency on irregular points in continuous space, a non-uniform point distribution, the potential high computational costs of calculating all-pair attention across massive points, and the risks of over-confident predictions due to varying point density. To address these challenges, we propose a new hierarchical spatial transformer model, which includes multi-resolution representation learning within a quad-tree hierarchy and efficient spatial attention via coarse approximation. We also design an uncertainty quantification branch to estimate prediction confidence related to input feature noise and point sparsity. We provide a theoretical analysis of computational time complexity and memory costs. Extensive experiments on both real-world and synthetic datasets show that our method outperforms multiple baselines in prediction accuracy and our model can scale up to one million points on one NVIDIA A100 GPU. The code is available at \url{https://github.com/spatialdatasciencegroup/HST}.
Uncertainty Quantification of Deep Learning for Spatiotemporal Data: Challenges and Opportunities
Nov 04, 2023
With the advancement of GPS, remote sensing, and computational simulations, large amounts of geospatial and spatiotemporal data are being collected at an increasing speed. Such emerging spatiotemporal big data assets, together with the recent progress of deep learning technologies, provide unique opportunities to transform society. However, it is widely recognized that deep learning sometimes makes unexpected and incorrect predictions with unwarranted confidence, causing severe consequences in high-stake decision-making applications (e.g., disaster management, medical diagnosis, autonomous driving). Uncertainty quantification (UQ) aims to estimate a deep learning model's confidence. This paper provides a brief overview of UQ of deep learning for spatiotemporal data, including its unique challenges and existing methods. We particularly focus on the importance of uncertainty sources. We identify several future research directions for spatiotemporal data.
A Survey on Uncertainty Quantification Methods for Deep Neural Networks: An Uncertainty Source Perspective
Mar 03, 2023



Deep neural networks (DNNs) have achieved tremendous success in making accurate predictions for computer vision, natural language processing, as well as science and engineering domains. However, it is also well-recognized that DNNs sometimes make unexpected, incorrect, but overconfident predictions. This can cause serious consequences in high-stake applications, such as autonomous driving, medical diagnosis, and disaster response. Uncertainty quantification (UQ) aims to estimate the confidence of DNN predictions beyond prediction accuracy. In recent years, many UQ methods have been developed for DNNs. It is of great practical value to systematically categorize these UQ methods and compare their advantages and disadvantages. However, existing surveys mostly focus on categorizing UQ methodologies from a neural network architecture perspective or a Bayesian perspective and ignore the source of uncertainty that each methodology can incorporate, making it difficult to select an appropriate UQ method in practice. To fill the gap, this paper presents a systematic taxonomy of UQ methods for DNNs based on the types of uncertainty sources (data uncertainty versus model uncertainty). We summarize the advantages and disadvantages of methods in each category. We show how our taxonomy of UQ methodologies can potentially help guide the choice of UQ method in different machine learning problems (e.g., active learning, robustness, and reinforcement learning). We also identify current research gaps and propose several future research directions.
An Explainer for Temporal Graph Neural Networks
Sep 02, 2022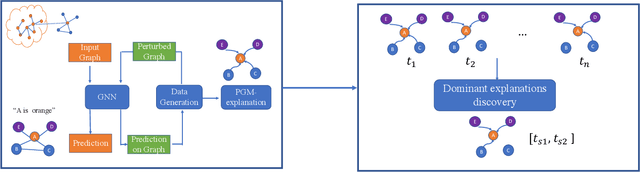
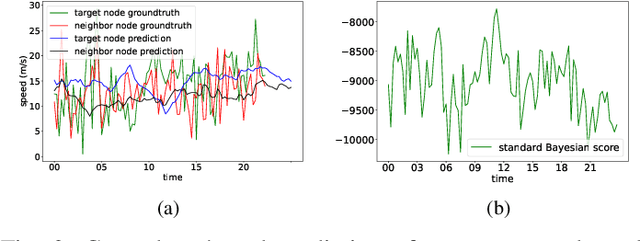
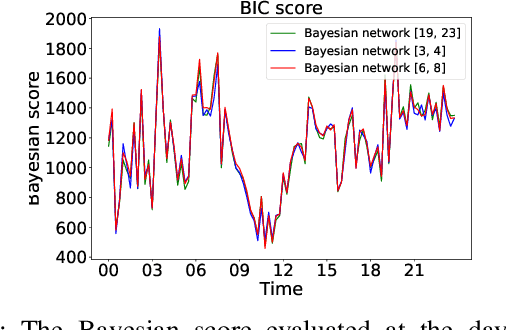
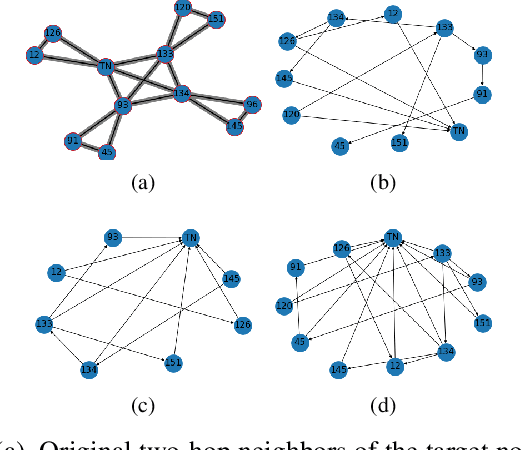
Temporal graph neural networks (TGNNs) have been widely used for modeling time-evolving graph-related tasks due to their ability to capture both graph topology dependency and non-linear temporal dynamic. The explanation of TGNNs is of vital importance for a transparent and trustworthy model. However, the complex topology structure and temporal dependency make explaining TGNN models very challenging. In this paper, we propose a novel explainer framework for TGNN models. Given a time series on a graph to be explained, the framework can identify dominant explanations in the form of a probabilistic graphical model in a time period. Case studies on the transportation domain demonstrate that the proposed approach can discover dynamic dependency structures in a road network for a time period.
Deep Learning for Earth Image Segmentation based on Imperfect Polyline Labels with Annotation Errors
Oct 02, 2020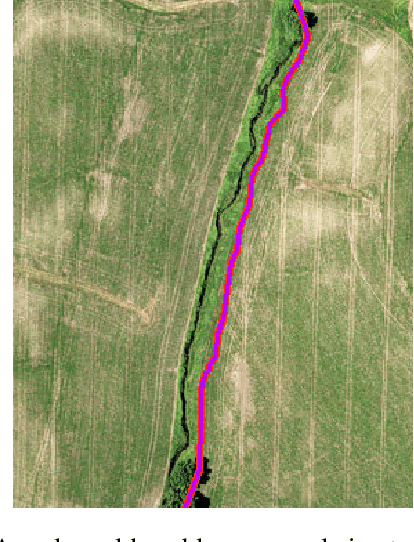
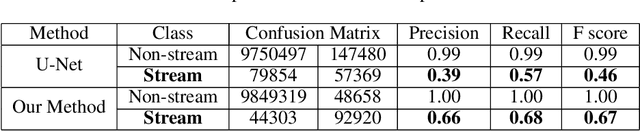

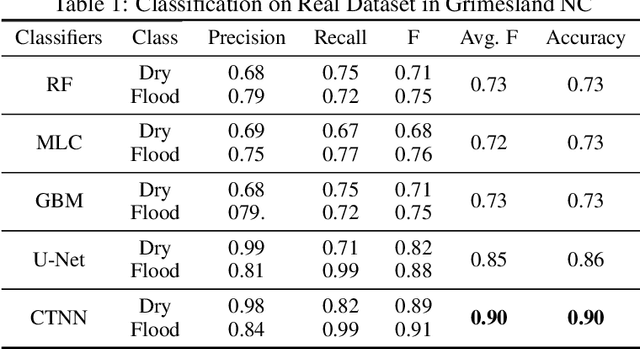
In recent years, deep learning techniques (e.g., U-Net, DeepLab) have achieved tremendous success in image segmentation. The performance of these models heavily relies on high-quality ground truth segment labels. Unfortunately, in many real-world problems, ground truth segment labels often have geometric annotation errors due to manual annotation mistakes, GPS errors, or visually interpreting background imagery at a coarse resolution. Such location errors will significantly impact the training performance of existing deep learning algorithms. Existing research on label errors either models ground truth errors in label semantics (assuming label locations to be correct) or models label location errors with simple square patch shifting. These methods cannot fully incorporate the geometric properties of label location errors. To fill the gap, this paper proposes a generic learning framework based on the EM algorithm to update deep learning model parameters and infer hidden true label locations simultaneously. Evaluations on a real-world hydrological dataset in the streamline refinement application show that the proposed framework outperforms baseline methods in classification accuracy (reducing the number of false positives by 67% and reducing the number of false negatives by 55%).
Semi-supervised Learning with the EM Algorithm: A Comparative Study between Unstructured and Structured Prediction
Aug 28, 2020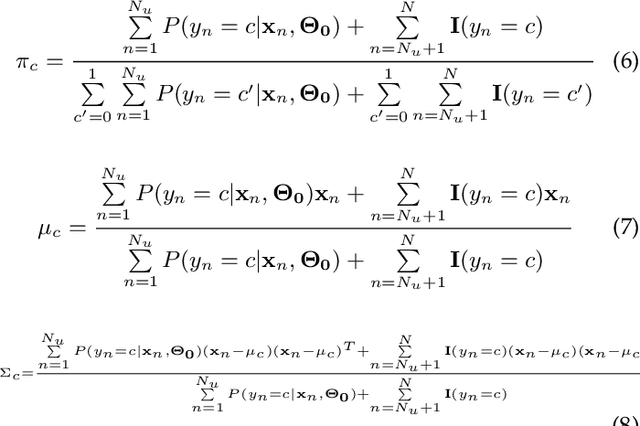
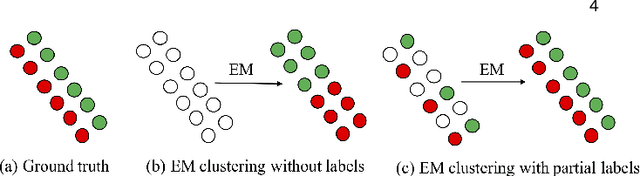


Semi-supervised learning aims to learn prediction models from both labeled and unlabeled samples. There has been extensive research in this area. Among existing work, generative mixture models with Expectation-Maximization (EM) is a popular method due to clear statistical properties. However, existing literature on EM-based semi-supervised learning largely focuses on unstructured prediction, assuming that samples are independent and identically distributed. Studies on EM-based semi-supervised approach in structured prediction is limited. This paper aims to fill the gap through a comparative study between unstructured and structured methods in EM-based semi-supervised learning. Specifically, we compare their theoretical properties and find that both methods can be considered as a generalization of self-training with soft class assignment of unlabeled samples, but the structured method additionally considers structural constraint in soft class assignment. We conducted a case study on real-world flood mapping datasets to compare the two methods. Results show that structured EM is more robust to class confusion caused by noise and obstacles in features in the context of the flood mapping application.
Deep Neural Network for 3D Surface Segmentation based on Contour Tree Hierarchy
Aug 25, 2020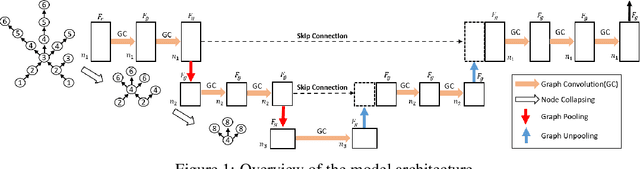
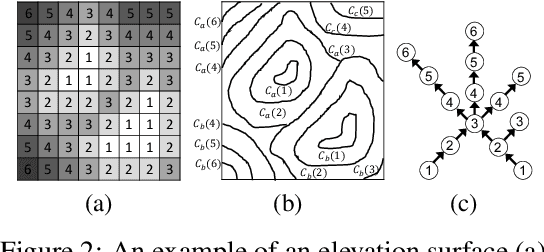
Given a 3D surface defined by an elevation function on a 2D grid as well as non-spatial features observed at each pixel, the problem of surface segmentation aims to classify pixels into contiguous classes based on both non-spatial features and surface topology. The problem has important applications in hydrology, planetary science, and biochemistry but is uniquely challenging for several reasons. First, the spatial extent of class segments follows surface contours in the topological space, regardless of their spatial shapes and directions. Second, the topological structure exists in multiple spatial scales based on different surface resolutions. Existing widely successful deep learning models for image segmentation are often not applicable due to their reliance on convolution and pooling operations to learn regular structural patterns on a grid. In contrast, we propose to represent surface topological structure by a contour tree skeleton, which is a polytree capturing the evolution of surface contours at different elevation levels. We further design a graph neural network based on the contour tree hierarchy to model surface topological structure at different spatial scales. Experimental evaluations based on real-world hydrological datasets show that our model outperforms several baseline methods in classification accuracy.