 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTKG-Thinker: Towards Dynamic Reasoning over Temporal Knowledge Graphs via Agentic Reinforcement Learning
Feb 05, 2026Temporal knowledge graph question answering (TKGQA) aims to answer time-sensitive questions by leveraging temporal knowledge bases. While Large Language Models (LLMs) demonstrate significant potential in TKGQA, current prompting strategies constrain their efficacy in two primary ways. First, they are prone to reasoning hallucinations under complex temporal constraints. Second, static prompting limits model autonomy and generalization, as it lack optimization through dynamic interaction with temporal knowledge graphs (TKGs) environments. To address these limitations, we propose \textbf{TKG-Thinker}, a novel agent equipped with autonomous planning and adaptive retrieval capabilities for reasoning over TKGs. Specifically, TKG-Thinker performs in-depth temporal reasoning through dynamic multi-turn interactions with TKGs via a dual-training strategy. We first apply Supervised Fine-Tuning (SFT) with chain-of thought data to instill core planning capabilities, followed by a Reinforcement Learning (RL) stage that leverages multi-dimensional rewards to refine reasoning policies under intricate temporal constraints. Experimental results on benchmark datasets with three open-source LLMs show that TKG-Thinker achieves state-of-the-art performance and exhibits strong generalization across complex TKGQA settings.
Towards Explainable Temporal Reasoning in Large Language Models: A Structure-Aware Generative Framework
May 21, 2025While large language models (LLMs) show great potential in temporal reasoning, most existing work focuses heavily on enhancing performance, often neglecting the explainable reasoning processes underlying the results. To address this gap, we introduce a comprehensive benchmark covering a wide range of temporal granularities, designed to systematically evaluate LLMs' capabilities in explainable temporal reasoning. Furthermore, our findings reveal that LLMs struggle to deliver convincing explanations when relying solely on textual information. To address challenge, we propose GETER, a novel structure-aware generative framework that integrates Graph structures with text for Explainable TEmporal Reasoning. Specifically, we first leverage temporal knowledge graphs to develop a temporal encoder that captures structural information for the query. Subsequently, we introduce a structure-text prefix adapter to map graph structure features into the text embedding space. Finally, LLMs generate explanation text by seamlessly integrating the soft graph token with instruction-tuning prompt tokens. Experimental results indicate that GETER achieves state-of-the-art performance while also demonstrating its effectiveness as well as strong generalization capabilities. Our dataset and code are available at https://github.com/carryTatum/GETER.
Can Atomic Step Decomposition Enhance the Self-structured Reasoning of Multimodal Large Models?
Mar 08, 2025In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of "slow thinking" into multimodal large language models (MLLMs). Our core idea is that different levels of reasoning abilities can be combined dynamically to tackle questions with different complexity. To this end, we propose a paradigm of Self-structured Chain of Thought (SCoT), which is composed of minimal semantic atomic steps. Different from existing methods that rely on structured templates or free-form paradigms, our method can not only generate cognitive CoT structures for various complex tasks but also mitigates the phenomenon of overthinking. To introduce structured reasoning capabilities into visual understanding models, we further design a novel AtomThink framework with four key modules, including (i) a data engine to generate high-quality multimodal reasoning paths; (ii) a supervised fine-tuning process with serialized inference data; (iii) a policy-guided multi-turn inference method; and (iv) an atomic capability metric to evaluate the single step utilization rate. We conduct extensive experiments to show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving more than 10\% average accuracy gains on MathVista and MathVerse. Compared to state-of-the-art structured CoT approaches, our method not only achieves higher accuracy but also improves data utilization by 5 times and boosts inference efficiency by 85.3\%. Our code is now public available in https://github.com/Quinn777/AtomThink.
Enhancing Financial Time-Series Forecasting with Retrieval-Augmented Large Language Models
Feb 11, 2025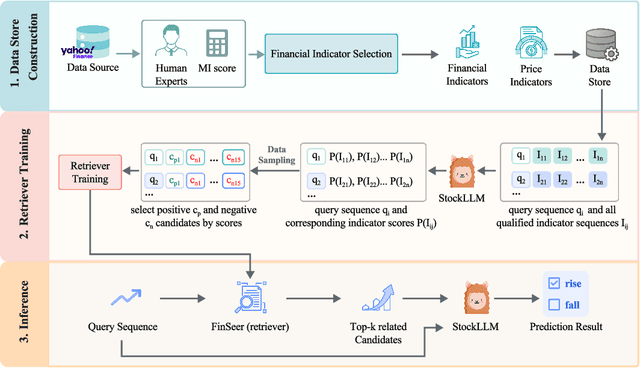

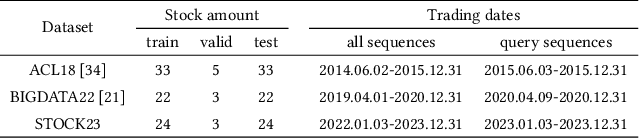
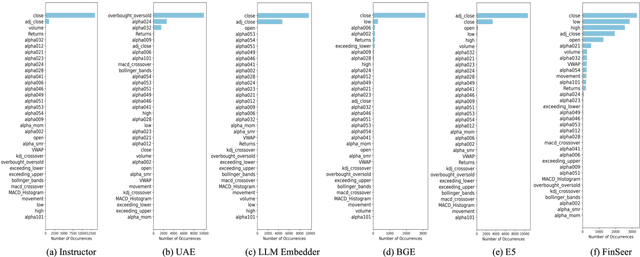
Stock movement prediction, a critical task in financial time-series forecasting, relies on identifying and retrieving key influencing factors from vast and complex datasets. However, traditional text-trained or numeric similarity-based retrieval methods often struggle to handle the intricacies of financial data. To address this, we propose the first retrieval-augmented generation (RAG) framework specifically designed for financial time-series forecasting. Our framework incorporates three key innovations: a fine-tuned 1B large language model (StockLLM) as its backbone, a novel candidate selection method enhanced by LLM feedback, and a training objective that maximizes the similarity between queries and historically significant sequences. These advancements enable our retriever, FinSeer, to uncover meaningful patterns while effectively minimizing noise in complex financial datasets. To support robust evaluation, we also construct new datasets that integrate financial indicators and historical stock prices. Experimental results demonstrate that our RAG framework outperforms both the baseline StockLLM and random retrieval methods, showcasing its effectiveness. FinSeer, as the retriever, achieves an 8% higher accuracy on the BIGDATA22 benchmark and retrieves more impactful sequences compared to existing retrieval methods. This work highlights the importance of tailored retrieval models in financial forecasting and provides a novel, scalable framework for future research in the field.
Retrieval-augmented Large Language Models for Financial Time Series Forecasting
Feb 09, 2025Stock movement prediction, a fundamental task in financial time-series forecasting, requires identifying and retrieving critical influencing factors from vast amounts of time-series data. However, existing text-trained or numeric similarity-based retrieval methods fall short in handling complex financial analysis. To address this, we propose the first retrieval-augmented generation (RAG) framework for financial time-series forecasting, featuring three key innovations: a fine-tuned 1B parameter large language model (StockLLM) as the backbone, a novel candidate selection method leveraging LLM feedback, and a training objective that maximizes similarity between queries and historically significant sequences. This enables our retriever, FinSeer, to uncover meaningful patterns while minimizing noise in complex financial data. We also construct new datasets integrating financial indicators and historical stock prices to train FinSeer and ensure robust evaluation. Experimental results demonstrate that our RAG framework outperforms bare StockLLM and random retrieval, highlighting its effectiveness, while FinSeer surpasses existing retrieval methods, achieving an 8\% higher accuracy on BIGDATA22 and retrieving more impactful sequences. This work underscores the importance of tailored retrieval models in financial forecasting and provides a novel framework for future research.
AtomThink: A Slow Thinking Framework for Multimodal Mathematical Reasoning
Nov 18, 2024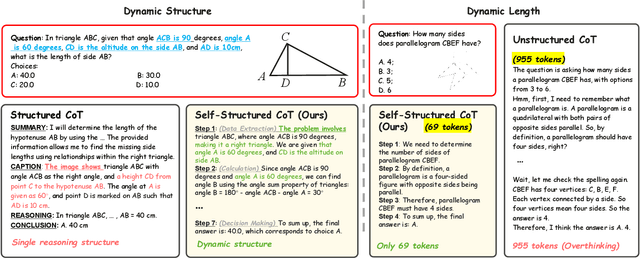
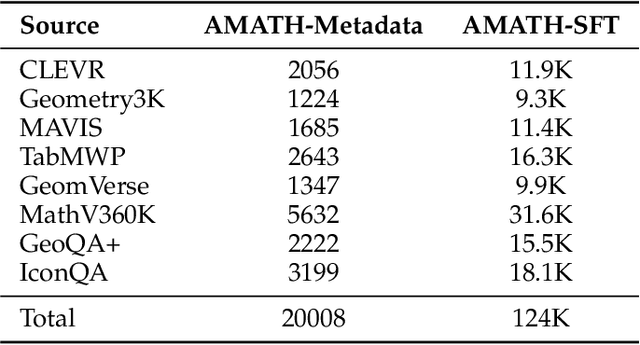
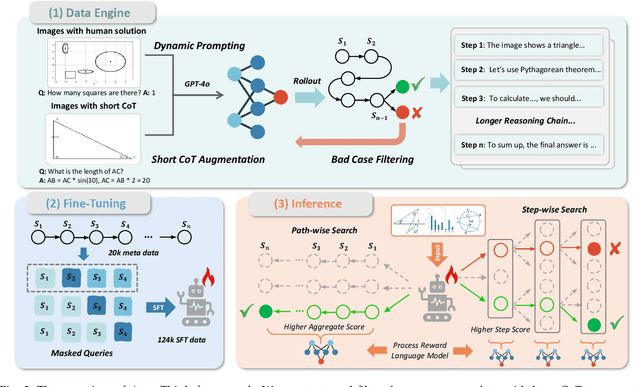
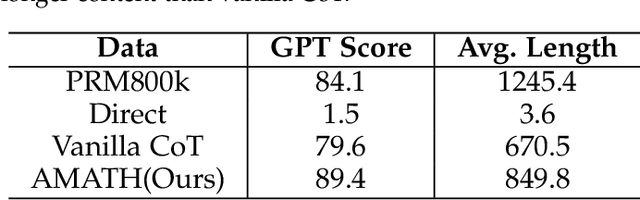
In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of ``slow thinking" into multimodal large language models (MLLMs). Contrary to existing methods that rely on direct or fast thinking, our key idea is to construct long chains of thought (CoT) consisting of atomic actions in a step-by-step manner, guiding MLLMs to perform complex reasoning. To this end, we design a novel AtomThink framework composed of three key modules: (i) a CoT annotation engine that automatically generates high-quality CoT annotations to address the lack of high-quality visual mathematical data; (ii) an atomic step fine-tuning strategy that jointly optimizes an MLLM and a policy reward model (PRM) for step-wise reasoning; and (iii) four different search strategies that can be applied with the PRM to complete reasoning. Additionally, we propose AtomMATH, a large-scale multimodal dataset of long CoTs, and an atomic capability evaluation metric for mathematical tasks. Extensive experimental results show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving approximately 50\% relative accuracy gains on MathVista and 120\% on MathVerse. To support the advancement of multimodal slow-thinking models, we will make our code and dataset publicly available on https://github.com/Quinn777/AtomThink.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
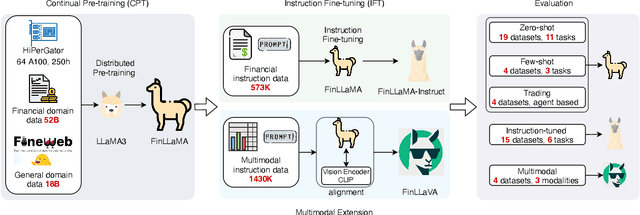
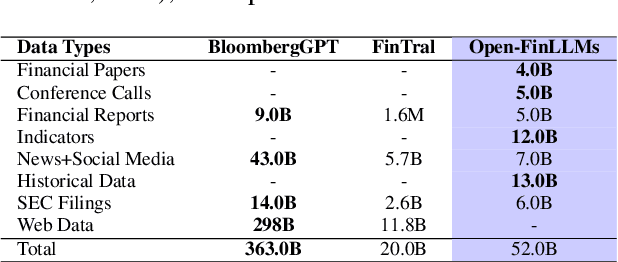
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
Deja vu: Contrastive Historical Modeling with Prefix-tuning for Temporal Knowledge Graph Reasoning
Mar 25, 2024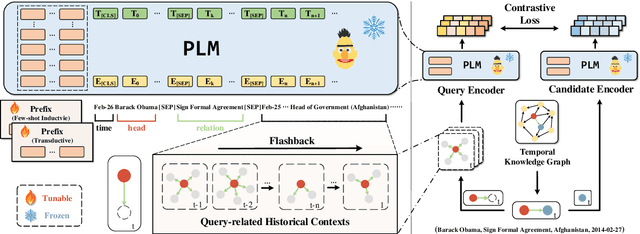
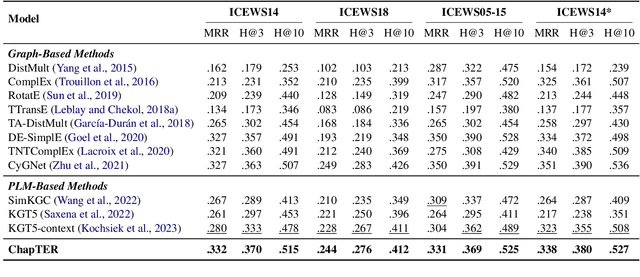
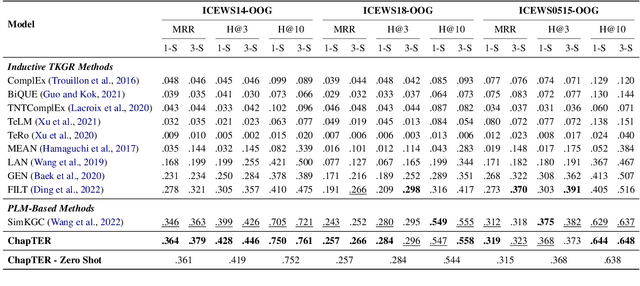
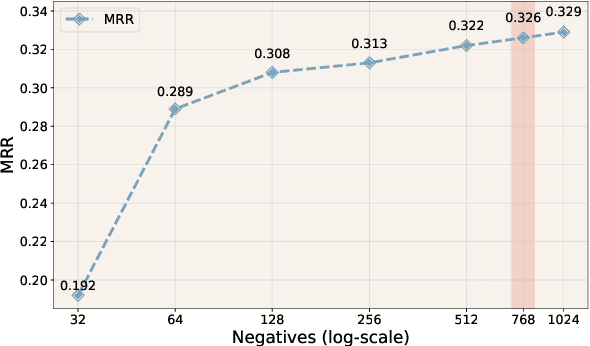
Temporal Knowledge Graph Reasoning (TKGR) is the task of inferring missing facts for incomplete TKGs in complex scenarios (e.g., transductive and inductive settings), which has been gaining increasing attention. Recently, to mitigate dependence on structured connections in TKGs, text-based methods have been developed to utilize rich linguistic information from entity descriptions. However, suffering from the enormous parameters and inflexibility of pre-trained language models, existing text-based methods struggle to balance the textual knowledge and temporal information with computationally expensive purpose-built training strategies. To tap the potential of text-based models for TKGR in various complex scenarios, we propose ChapTER, a Contrastive historical modeling framework with prefix-tuning for TEmporal Reasoning. ChapTER feeds history-contextualized text into the pseudo-Siamese encoders to strike a textual-temporal balance via contrastive estimation between queries and candidates. By introducing virtual time prefix tokens, it applies a prefix-based tuning method to facilitate the frozen PLM capable for TKGR tasks under different settings. We evaluate ChapTER on four transductive and three few-shot inductive TKGR benchmarks, and experimental results demonstrate that ChapTER achieves superior performance compared to competitive baselines with only 0.17% tuned parameters. We conduct thorough analysis to verify the effectiveness, flexibility and efficiency of ChapTER.
InstructionGPT-4: A 200-Instruction Paradigm for Fine-Tuning MiniGPT-4
Aug 23, 2023Multimodal large language models acquire their instruction-following capabilities through a two-stage training process: pre-training on image-text pairs and fine-tuning on supervised vision-language instruction data. Recent studies have shown that large language models can achieve satisfactory results even with a limited amount of high-quality instruction-following data. In this paper, we introduce InstructionGPT-4, which is fine-tuned on a small dataset comprising only 200 examples, amounting to approximately 6% of the instruction-following data used in the alignment dataset for MiniGPT-4. We first propose several metrics to access the quality of multimodal instruction data. Based on these metrics, we present a simple and effective data selector to automatically identify and filter low-quality vision-language data. By employing this method, InstructionGPT-4 outperforms the original MiniGPT-4 on various evaluations (e.g., visual question answering, GPT-4 preference). Overall, our findings demonstrate that less but high-quality instruction tuning data is efficient to enable multimodal large language models to generate better output.
FILM: How can Few-Shot Image Classification Benefit from Pre-Trained Language Models?
Jul 09, 2023
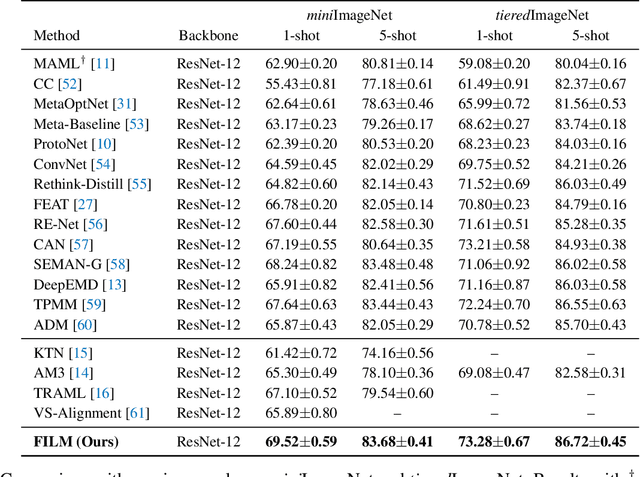


Few-shot learning aims to train models that can be generalized to novel classes with only a few samples. Recently, a line of works are proposed to enhance few-shot learning with accessible semantic information from class names. However, these works focus on improving existing modules such as visual prototypes and feature extractors of the standard few-shot learning framework. This limits the full potential use of semantic information. In this paper, we propose a novel few-shot learning framework that uses pre-trained language models based on contrastive learning. To address the challenge of alignment between visual features and textual embeddings obtained from text-based pre-trained language model, we carefully design the textual branch of our framework and introduce a metric module to generalize the cosine similarity. For better transferability, we let the metric module adapt to different few-shot tasks and adopt MAML to train the model via bi-level optimization. Moreover, we conduct extensive experiments on multiple benchmarks to demonstrate the effectiveness of our method.