 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTKG-Thinker: Towards Dynamic Reasoning over Temporal Knowledge Graphs via Agentic Reinforcement Learning
Feb 05, 2026Temporal knowledge graph question answering (TKGQA) aims to answer time-sensitive questions by leveraging temporal knowledge bases. While Large Language Models (LLMs) demonstrate significant potential in TKGQA, current prompting strategies constrain their efficacy in two primary ways. First, they are prone to reasoning hallucinations under complex temporal constraints. Second, static prompting limits model autonomy and generalization, as it lack optimization through dynamic interaction with temporal knowledge graphs (TKGs) environments. To address these limitations, we propose \textbf{TKG-Thinker}, a novel agent equipped with autonomous planning and adaptive retrieval capabilities for reasoning over TKGs. Specifically, TKG-Thinker performs in-depth temporal reasoning through dynamic multi-turn interactions with TKGs via a dual-training strategy. We first apply Supervised Fine-Tuning (SFT) with chain-of thought data to instill core planning capabilities, followed by a Reinforcement Learning (RL) stage that leverages multi-dimensional rewards to refine reasoning policies under intricate temporal constraints. Experimental results on benchmark datasets with three open-source LLMs show that TKG-Thinker achieves state-of-the-art performance and exhibits strong generalization across complex TKGQA settings.
Incentivizing In-depth Reasoning over Long Contexts with Process Advantage Shaping
Jan 18, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective in enhancing LLMs short-context reasoning, but its performance degrades in long-context scenarios that require both precise grounding and robust long-range reasoning. We identify the "almost-there" phenomenon in long-context reasoning, where trajectories are largely correct but fail at the final step, and attribute this failure to two factors: (1) the lack of high reasoning density in long-context QA data that push LLMs beyond mere grounding toward sophisticated multi-hop reasoning; and (2) the loss of valuable learning signals during long-context RL training due to the indiscriminate penalization of partially correct trajectories with incorrect outcomes. To overcome this bottleneck, we propose DeepReasonQA, a KG-driven synthesis framework that controllably constructs high-difficulty, multi-hop long-context QA pairs with inherent reasoning chains. Building on this, we introduce Long-context Process Advantage Shaping (LongPAS), a simple yet effective method that performs fine-grained credit assignment by evaluating reasoning steps along Validity and Relevance dimensions, which captures critical learning signals from "almost-there" trajectories. Experiments on three long-context reasoning benchmarks show that our approach substantially outperforms RLVR baselines and matches frontier LLMs while using far fewer parameters. Further analysis confirms the effectiveness of our methods in strengthening long-context reasoning while maintaining stable RL training.
QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
Dec 15, 2025We introduce QwenLong-L1.5, a model that achieves superior long-context reasoning capabilities through systematic post-training innovations. The key technical breakthroughs of QwenLong-L1.5 are as follows: (1) Long-Context Data Synthesis Pipeline: We develop a systematic synthesis framework that generates challenging reasoning tasks requiring multi-hop grounding over globally distributed evidence. By deconstructing documents into atomic facts and their underlying relationships, and then programmatically composing verifiable reasoning questions, our approach creates high-quality training data at scale, moving substantially beyond simple retrieval tasks to enable genuine long-range reasoning capabilities. (2) Stabilized Reinforcement Learning for Long-Context Training: To overcome the critical instability in long-context RL, we introduce task-balanced sampling with task-specific advantage estimation to mitigate reward bias, and propose Adaptive Entropy-Controlled Policy Optimization (AEPO) that dynamically regulates exploration-exploitation trade-offs. (3) Memory-Augmented Architecture for Ultra-Long Contexts: Recognizing that even extended context windows cannot accommodate arbitrarily long sequences, we develop a memory management framework with multi-stage fusion RL training that seamlessly integrates single-pass reasoning with iterative memory-based processing for tasks exceeding 4M tokens. Based on Qwen3-30B-A3B-Thinking, QwenLong-L1.5 achieves performance comparable to GPT-5 and Gemini-2.5-Pro on long-context reasoning benchmarks, surpassing its baseline by 9.90 points on average. On ultra-long tasks (1M~4M tokens), QwenLong-L1.5's memory-agent framework yields a 9.48-point gain over the agent baseline. Additionally, the acquired long-context reasoning ability translates to enhanced performance in general domains like scientific reasoning, memory tool using, and extended dialogue.
Improving LLMs' Generalized Reasoning Abilities by Graph Problems
Jul 23, 2025Large Language Models (LLMs) have made remarkable strides in reasoning tasks, yet their performance often falters on novel and complex problems. Domain-specific continued pretraining (CPT) methods, such as those tailored for mathematical reasoning, have shown promise but lack transferability to broader reasoning tasks. In this work, we pioneer the use of Graph Problem Reasoning (GPR) to enhance the general reasoning capabilities of LLMs. GPR tasks, spanning pathfinding, network analysis, numerical computation, and topological reasoning, require sophisticated logical and relational reasoning, making them ideal for teaching diverse reasoning patterns. To achieve this, we introduce GraphPile, the first large-scale corpus specifically designed for CPT using GPR data. Spanning 10.9 billion tokens across 23 graph tasks, the dataset includes chain-of-thought, program-of-thought, trace of execution, and real-world graph data. Using GraphPile, we train GraphMind on popular base models Llama 3 and 3.1, as well as Gemma 2, achieving up to 4.9 percent higher accuracy in mathematical reasoning and up to 21.2 percent improvement in non-mathematical reasoning tasks such as logical and commonsense reasoning. By being the first to harness GPR for enhancing reasoning patterns and introducing the first dataset of its kind, our work bridges the gap between domain-specific pretraining and universal reasoning capabilities, advancing the adaptability and robustness of LLMs.
How does Misinformation Affect Large Language Model Behaviors and Preferences?
May 27, 2025Large Language Models (LLMs) have shown remarkable capabilities in knowledge-intensive tasks, while they remain vulnerable when encountering misinformation. Existing studies have explored the role of LLMs in combating misinformation, but there is still a lack of fine-grained analysis on the specific aspects and extent to which LLMs are influenced by misinformation. To bridge this gap, we present MisBench, the current largest and most comprehensive benchmark for evaluating LLMs' behavior and knowledge preference toward misinformation. MisBench consists of 10,346,712 pieces of misinformation, which uniquely considers both knowledge-based conflicts and stylistic variations in misinformation. Empirical results reveal that while LLMs demonstrate comparable abilities in discerning misinformation, they still remain susceptible to knowledge conflicts and stylistic variations. Based on these findings, we further propose a novel approach called Reconstruct to Discriminate (RtD) to strengthen LLMs' ability to detect misinformation. Our study provides valuable insights into LLMs' interactions with misinformation, and we believe MisBench can serve as an effective benchmark for evaluating LLM-based detectors and enhancing their reliability in real-world applications. Codes and data are available at https://github.com/GKNL/MisBench.
Towards Explainable Temporal Reasoning in Large Language Models: A Structure-Aware Generative Framework
May 21, 2025While large language models (LLMs) show great potential in temporal reasoning, most existing work focuses heavily on enhancing performance, often neglecting the explainable reasoning processes underlying the results. To address this gap, we introduce a comprehensive benchmark covering a wide range of temporal granularities, designed to systematically evaluate LLMs' capabilities in explainable temporal reasoning. Furthermore, our findings reveal that LLMs struggle to deliver convincing explanations when relying solely on textual information. To address challenge, we propose GETER, a novel structure-aware generative framework that integrates Graph structures with text for Explainable TEmporal Reasoning. Specifically, we first leverage temporal knowledge graphs to develop a temporal encoder that captures structural information for the query. Subsequently, we introduce a structure-text prefix adapter to map graph structure features into the text embedding space. Finally, LLMs generate explanation text by seamlessly integrating the soft graph token with instruction-tuning prompt tokens. Experimental results indicate that GETER achieves state-of-the-art performance while also demonstrating its effectiveness as well as strong generalization capabilities. Our dataset and code are available at https://github.com/carryTatum/GETER.
Deja vu: Contrastive Historical Modeling with Prefix-tuning for Temporal Knowledge Graph Reasoning
Mar 25, 2024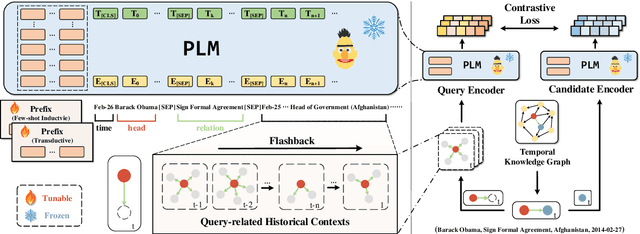
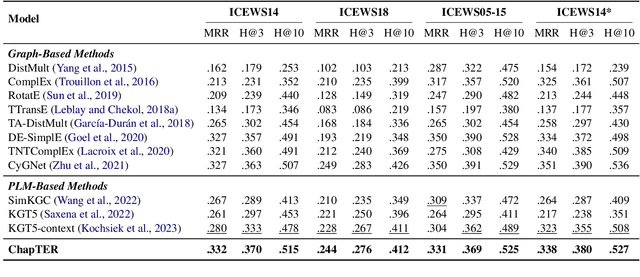
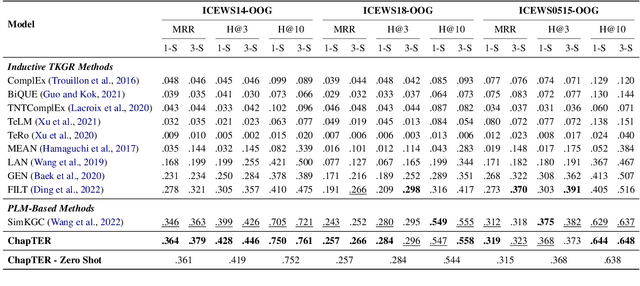
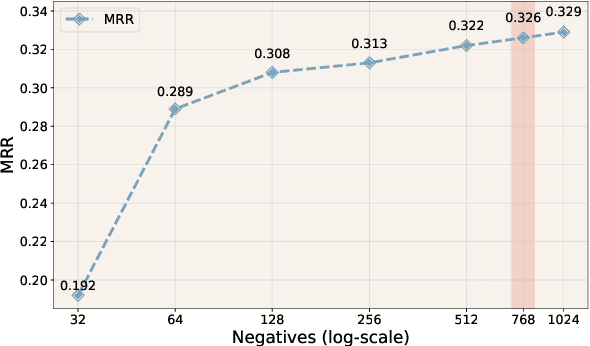
Temporal Knowledge Graph Reasoning (TKGR) is the task of inferring missing facts for incomplete TKGs in complex scenarios (e.g., transductive and inductive settings), which has been gaining increasing attention. Recently, to mitigate dependence on structured connections in TKGs, text-based methods have been developed to utilize rich linguistic information from entity descriptions. However, suffering from the enormous parameters and inflexibility of pre-trained language models, existing text-based methods struggle to balance the textual knowledge and temporal information with computationally expensive purpose-built training strategies. To tap the potential of text-based models for TKGR in various complex scenarios, we propose ChapTER, a Contrastive historical modeling framework with prefix-tuning for TEmporal Reasoning. ChapTER feeds history-contextualized text into the pseudo-Siamese encoders to strike a textual-temporal balance via contrastive estimation between queries and candidates. By introducing virtual time prefix tokens, it applies a prefix-based tuning method to facilitate the frozen PLM capable for TKGR tasks under different settings. We evaluate ChapTER on four transductive and three few-shot inductive TKGR benchmarks, and experimental results demonstrate that ChapTER achieves superior performance compared to competitive baselines with only 0.17% tuned parameters. We conduct thorough analysis to verify the effectiveness, flexibility and efficiency of ChapTER.
Pre-trained Language Model with Prompts for Temporal Knowledge Graph Completion
May 13, 2023



Temporal Knowledge graph completion (TKGC) is a crucial task that involves reasoning at known timestamps to complete the missing part of facts and has attracted more and more attention in recent years. Most existing methods focus on learning representations based on graph neural networks while inaccurately extracting information from timestamps and insufficiently utilizing the implied information in relations. To address these problems, we propose a novel TKGC model, namely Pre-trained Language Model with Prompts for TKGC (PPT). We convert a series of sampled quadruples into pre-trained language model inputs and convert intervals between timestamps into different prompts to make coherent sentences with implicit semantic information. We train our model with a masking strategy to convert TKGC task into a masked token prediction task, which can leverage the semantic information in pre-trained language models. Experiments on three benchmark datasets and extensive analysis demonstrate that our model has great competitiveness compared to other models with four metrics. Our model can effectively incorporate information from temporal knowledge graphs into the language models.
SMiLE: Schema-augmented Multi-level Contrastive Learning for Knowledge Graph Link Prediction
Oct 10, 2022



Link prediction is the task of inferring missing links between entities in knowledge graphs. Embedding-based methods have shown effectiveness in addressing this problem by modeling relational patterns in triples. However, the link prediction task often requires contextual information in entity neighborhoods, while most existing embedding-based methods fail to capture it. Additionally, little attention is paid to the diversity of entity representations in different contexts, which often leads to false prediction results. In this situation, we consider that the schema of knowledge graph contains the specific contextual information, and it is beneficial for preserving the consistency of entities across contexts. In this paper, we propose a novel schema-augmented multi-level contrastive learning framework (SMiLE) to conduct knowledge graph link prediction. Specifically, we first exploit network schema as the prior constraint to sample negatives and pre-train our model by employing a multi-level contrastive learning method to yield both prior schema and contextual information. Then we fine-tune our model under the supervision of individual triples to learn subtler representations for link prediction. Extensive experimental results on four knowledge graph datasets with thorough analysis of each component demonstrate the effectiveness of our proposed framework against state-of-the-art baselines.