 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere-to-Learn: Analytical Policy Gradient Directed Exploration for On-Policy Robotic Reinforcement Learning
Apr 01, 2026On-policy reinforcement learning (RL) algorithms have demonstrated great potential in robotic control, where effective exploration is crucial for efficient and high-quality policy learning. However, how to encourage the agent to explore the better trajectories efficiently remains a challenge. Most existing methods incentivize exploration by maximizing the policy entropy or encouraging novel state visiting regardless of the potential state value. We propose a new form of directed exploration that uses analytical policy gradients from a differentiable dynamics model to inject task-aware, physics-guided guidance, thereby steering the agent towards high-reward regions for accelerated and more effective policy learning.
Diffusion Policy through Conditional Proximal Policy Optimization
Mar 05, 2026Reinforcement learning (RL) has been extensively employed in a wide range of decision-making problems, such as games and robotics. Recently, diffusion policies have shown strong potential in modeling multi-modal behaviors, enabling more diverse and flexible action generation compared to the conventional Gaussian policy. Despite various attempts to combine RL with diffusion, a key challenge is the difficulty of computing action log-likelihood under the diffusion model. This greatly hinders the direct application of diffusion policies in on-policy reinforcement learning. Most existing methods calculate or approximate the log-likelihood through the entire denoising process in the diffusion model, which can be memory- and computationally inefficient. To overcome this challenge, we propose a novel and efficient method to train a diffusion policy in an on-policy setting that requires only evaluating a simple Gaussian probability. This is achieved by aligning the policy iteration with the diffusion process, which is a distinct paradigm compared to previous work. Moreover, our formulation can naturally handle entropy regularization, which is often difficult to incorporate into diffusion policies. Experiments demonstrate that the proposed method produces multimodal policy behaviors and achieves superior performance on a variety of benchmark tasks in both IsaacLab and MuJoCo Playground.
TKG-Thinker: Towards Dynamic Reasoning over Temporal Knowledge Graphs via Agentic Reinforcement Learning
Feb 05, 2026Temporal knowledge graph question answering (TKGQA) aims to answer time-sensitive questions by leveraging temporal knowledge bases. While Large Language Models (LLMs) demonstrate significant potential in TKGQA, current prompting strategies constrain their efficacy in two primary ways. First, they are prone to reasoning hallucinations under complex temporal constraints. Second, static prompting limits model autonomy and generalization, as it lack optimization through dynamic interaction with temporal knowledge graphs (TKGs) environments. To address these limitations, we propose \textbf{TKG-Thinker}, a novel agent equipped with autonomous planning and adaptive retrieval capabilities for reasoning over TKGs. Specifically, TKG-Thinker performs in-depth temporal reasoning through dynamic multi-turn interactions with TKGs via a dual-training strategy. We first apply Supervised Fine-Tuning (SFT) with chain-of thought data to instill core planning capabilities, followed by a Reinforcement Learning (RL) stage that leverages multi-dimensional rewards to refine reasoning policies under intricate temporal constraints. Experimental results on benchmark datasets with three open-source LLMs show that TKG-Thinker achieves state-of-the-art performance and exhibits strong generalization across complex TKGQA settings.
PolicyFlow: Policy Optimization with Continuous Normalizing Flow in Reinforcement Learning
Feb 01, 2026Among on-policy reinforcement learning algorithms, Proximal Policy Optimization (PPO) demonstrates is widely favored for its simplicity, numerical stability, and strong empirical performance. Standard PPO relies on surrogate objectives defined via importance ratios, which require evaluating policy likelihood that is typically straightforward when the policy is modeled as a Gaussian distribution. However, extending PPO to more expressive, high-capacity policy models such as continuous normalizing flows (CNFs), also known as flow-matching models, is challenging because likelihood evaluation along the full flow trajectory is computationally expensive and often numerically unstable. To resolve this issue, we propose PolicyFlow, a novel on-policy CNF-based reinforcement learning algorithm that integrates expressive CNF policies with PPO-style objectives without requiring likelihood evaluation along the full flow path. PolicyFlow approximates importance ratios using velocity field variations along a simple interpolation path, reducing computational overhead without compromising training stability. To further prevent mode collapse and further encourage diverse behaviors, we propose the Brownian Regularizer, an implicit policy entropy regularizer inspired by Brownian motion, which is conceptually elegant and computationally lightweight. Experiments on diverse tasks across various environments including MultiGoal, PointMaze, IsaacLab and MuJoCo Playground show that PolicyFlow achieves competitive or superior performance compared to PPO using Gaussian policies and flow-based baselines including FPO and DPPO. Notably, results on MultiGoal highlight PolicyFlow's ability to capture richer multimodal action distributions.
Plan Then Retrieve: Reinforcement Learning-Guided Complex Reasoning over Knowledge Graphs
Oct 23, 2025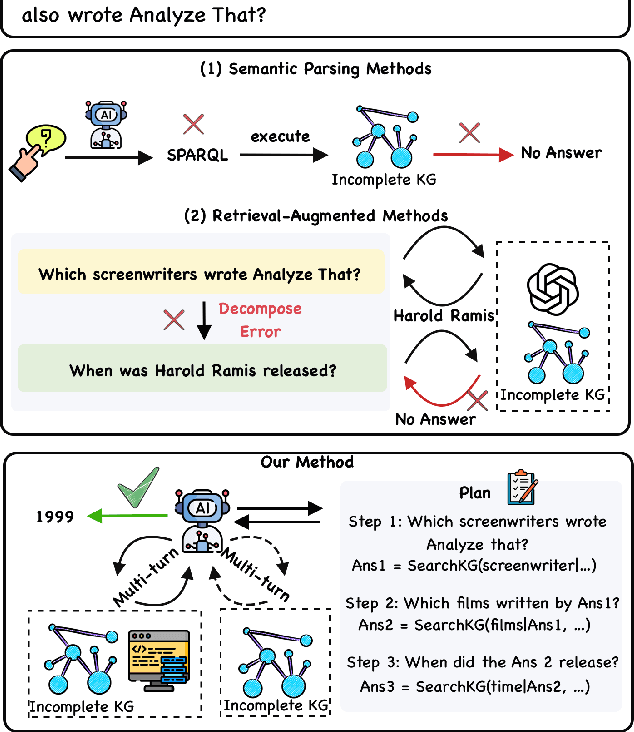

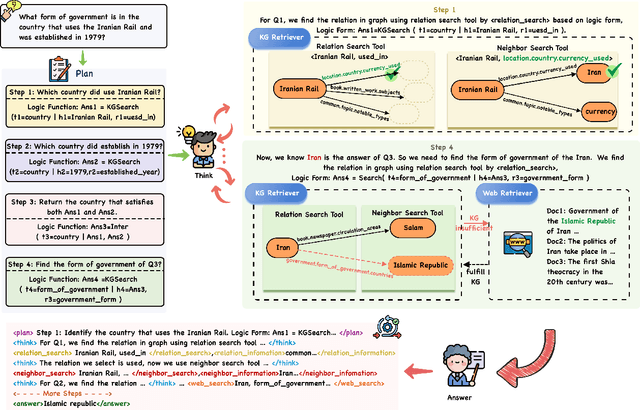
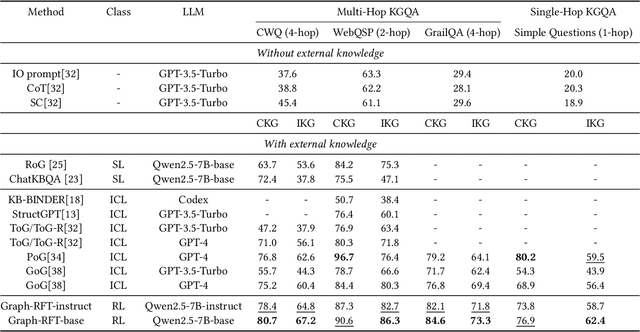
Knowledge Graph Question Answering aims to answer natural language questions by reasoning over structured knowledge graphs. While large language models have advanced KGQA through their strong reasoning capabilities, existing methods continue to struggle to fully exploit both the rich knowledge encoded in KGs and the reasoning capabilities of LLMs, particularly in complex scenarios. They often assume complete KG coverage and lack mechanisms to judge when external information is needed, and their reasoning remains locally myopic, failing to maintain coherent multi-step planning, leading to reasoning failures even when relevant knowledge exists. We propose Graph-RFT, a novel two-stage reinforcement fine-tuning KGQA framework with a 'plan-KGsearch-and-Websearch-during-think' paradigm, that enables LLMs to perform autonomous planning and adaptive retrieval scheduling across KG and web sources under incomplete knowledge conditions. Graph-RFT introduces a chain-of-thought fine-tuning method with a customized plan-retrieval dataset activates structured reasoning and resolves the GRPO cold-start problem. It then introduces a novel plan-retrieval guided reinforcement learning process integrates explicit planning and retrieval actions with a multi-reward design, enabling coverage-aware retrieval scheduling. It employs a Cartesian-inspired planning module to decompose complex questions into ordered subquestions, and logical expression to guide tool invocation for globally consistent multi-step reasoning. This reasoning retrieval process is optimized with a multi-reward combining outcome and retrieval specific signals, enabling the model to learn when and how to combine KG and web retrieval effectively.
Whole-body Motion Control of an Omnidirectional Wheel-Legged Mobile Manipulator via Contact-Aware Dynamic Optimization
Sep 17, 2025Wheel-legged robots with integrated manipulators hold great promise for mobile manipulation in logistics, industrial automation, and human-robot collaboration. However, unified control of such systems remains challenging due to the redundancy in degrees of freedom, complex wheel-ground contact dynamics, and the need for seamless coordination between locomotion and manipulation. In this work, we present the design and whole-body motion control of an omnidirectional wheel-legged quadrupedal robot equipped with a dexterous manipulator. The proposed platform incorporates independently actuated steering modules and hub-driven wheels, enabling agile omnidirectional locomotion with high maneuverability in structured environments. To address the challenges of contact-rich interaction, we develop a contact-aware whole-body dynamic optimization framework that integrates point-contact modeling for manipulation with line-contact modeling for wheel-ground interactions. A warm-start strategy is introduced to accelerate online optimization, ensuring real-time feasibility for high-dimensional control. Furthermore, a unified kinematic model tailored for the robot's 4WIS-4WID actuation scheme eliminates the need for mode switching across different locomotion strategies, improving control consistency and robustness. Simulation and experimental results validate the effectiveness of the proposed framework, demonstrating agile terrain traversal, high-speed omnidirectional mobility, and precise manipulation under diverse scenarios, underscoring the system's potential for factory automation, urban logistics, and service robotics in semi-structured environments.
Forecast-Then-Optimize Deep Learning Methods
Jun 16, 2025Time series forecasting underpins vital decision-making across various sectors, yet raw predictions from sophisticated models often harbor systematic errors and biases. We examine the Forecast-Then-Optimize (FTO) framework, pioneering its systematic synopsis. Unlike conventional Predict-Then-Optimize (PTO) methods, FTO explicitly refines forecasts through optimization techniques such as ensemble methods, meta-learners, and uncertainty adjustments. Furthermore, deep learning and large language models have established superiority over traditional parametric forecasting models for most enterprise applications. This paper surveys significant advancements from 2016 to 2025, analyzing mainstream deep learning FTO architectures. Focusing on real-world applications in operations management, we demonstrate FTO's crucial role in enhancing predictive accuracy, robustness, and decision efficacy. Our study establishes foundational guidelines for future forecasting methodologies, bridging theory and operational practicality.
A Retrieval-Augmented Multi-Agent Framework for Psychiatry Diagnosis
Jun 04, 2025The application of AI in psychiatric diagnosis faces significant challenges, including the subjective nature of mental health assessments, symptom overlap across disorders, and privacy constraints limiting data availability. To address these issues, we present MoodAngels, the first specialized multi-agent framework for mood disorder diagnosis. Our approach combines granular-scale analysis of clinical assessments with a structured verification process, enabling more accurate interpretation of complex psychiatric data. Complementing this framework, we introduce MoodSyn, an open-source dataset of 1,173 synthetic psychiatric cases that preserves clinical validity while ensuring patient privacy. Experimental results demonstrate that MoodAngels outperforms conventional methods, with our baseline agent achieving 12.3% higher accuracy than GPT-4o on real-world cases, and our full multi-agent system delivering further improvements. Evaluation in the MoodSyn dataset demonstrates exceptional fidelity, accurately reproducing both the core statistical patterns and complex relationships present in the original data while maintaining strong utility for machine learning applications. Together, these contributions provide both an advanced diagnostic tool and a critical research resource for computational psychiatry, bridging important gaps in AI-assisted mental health assessment.
G-DReaM: Graph-conditioned Diffusion Retargeting across Multiple Embodiments
May 27, 2025Motion retargeting for specific robot from existing motion datasets is one critical step in transferring motion patterns from human behaviors to and across various robots. However, inconsistencies in topological structure, geometrical parameters as well as joint correspondence make it difficult to handle diverse embodiments with a unified retargeting architecture. In this work, we propose a novel unified graph-conditioned diffusion-based motion generation framework for retargeting reference motions across diverse embodiments. The intrinsic characteristics of heterogeneous embodiments are represented with graph structure that effectively captures topological and geometrical features of different robots. Such a graph-based encoding further allows for knowledge exploitation at the joint level with a customized attention mechanisms developed in this work. For lacking ground truth motions of the desired embodiment, we utilize an energy-based guidance formulated as retargeting losses to train the diffusion model. As one of the first cross-embodiment motion retargeting methods in robotics, our experiments validate that the proposed model can retarget motions across heterogeneous embodiments in a unified manner. Moreover, it demonstrates a certain degree of generalization to both diverse skeletal structures and similar motion patterns.
Towards Explainable Temporal Reasoning in Large Language Models: A Structure-Aware Generative Framework
May 21, 2025While large language models (LLMs) show great potential in temporal reasoning, most existing work focuses heavily on enhancing performance, often neglecting the explainable reasoning processes underlying the results. To address this gap, we introduce a comprehensive benchmark covering a wide range of temporal granularities, designed to systematically evaluate LLMs' capabilities in explainable temporal reasoning. Furthermore, our findings reveal that LLMs struggle to deliver convincing explanations when relying solely on textual information. To address challenge, we propose GETER, a novel structure-aware generative framework that integrates Graph structures with text for Explainable TEmporal Reasoning. Specifically, we first leverage temporal knowledge graphs to develop a temporal encoder that captures structural information for the query. Subsequently, we introduce a structure-text prefix adapter to map graph structure features into the text embedding space. Finally, LLMs generate explanation text by seamlessly integrating the soft graph token with instruction-tuning prompt tokens. Experimental results indicate that GETER achieves state-of-the-art performance while also demonstrating its effectiveness as well as strong generalization capabilities. Our dataset and code are available at https://github.com/carryTatum/GETER.