 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIIB-LPO: Latent Policy Optimization via Iterative Information Bottleneck
Jan 09, 2026Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) for Large Language Model (LLM) reasoning have been hindered by a persistent challenge: exploration collapse. The semantic homogeneity of random rollouts often traps models in narrow, over-optimized behaviors. While existing methods leverage policy entropy to encourage exploration, they face inherent limitations. Global entropy regularization is susceptible to reward hacking, which can induce meaningless verbosity, whereas local token-selective updates struggle with the strong inductive bias of pre-trained models. To address this, we propose Latent Policy Optimization via Iterative Information Bottleneck (IIB-LPO), a novel approach that shifts exploration from statistical perturbation of token distributions to topological branching of reasoning trajectories. IIB-LPO triggers latent branching at high-entropy states to diversify reasoning paths and employs the Information Bottleneck principle both as a trajectory filter and a self-reward mechanism, ensuring concise and informative exploration. Empirical results across four mathematical reasoning benchmarks demonstrate that IIB-LPO achieves state-of-the-art performance, surpassing prior methods by margins of up to 5.3% in accuracy and 7.4% in diversity metrics.
Are Unified Vision-Language Models Necessary: Generalization Across Understanding and Generation
May 29, 2025Recent advancements in unified vision-language models (VLMs), which integrate both visual understanding and generation capabilities, have attracted significant attention. The underlying hypothesis is that a unified architecture with mixed training on both understanding and generation tasks can enable mutual enhancement between understanding and generation. However, this hypothesis remains underexplored in prior works on unified VLMs. To address this gap, this paper systematically investigates the generalization across understanding and generation tasks in unified VLMs. Specifically, we design a dataset closely aligned with real-world scenarios to facilitate extensive experiments and quantitative evaluations. We evaluate multiple unified VLM architectures to validate our findings. Our key findings are as follows. First, unified VLMs trained with mixed data exhibit mutual benefits in understanding and generation tasks across various architectures, and this mutual benefits can scale up with increased data. Second, better alignment between multimodal input and output spaces will lead to better generalization. Third, the knowledge acquired during generation tasks can transfer to understanding tasks, and this cross-task generalization occurs within the base language model, beyond modality adapters. Our findings underscore the critical necessity of unifying understanding and generation in VLMs, offering valuable insights for the design and optimization of unified VLMs.
Unveiling the Compositional Ability Gap in Vision-Language Reasoning Model
May 26, 2025While large language models (LLMs) demonstrate strong reasoning capabilities utilizing reinforcement learning (RL) with verifiable reward, whether large vision-language models (VLMs) can directly inherit such capabilities through similar post-training strategies remains underexplored. In this work, we conduct a systematic compositional probing study to evaluate whether current VLMs trained with RL or other post-training strategies can compose capabilities across modalities or tasks under out-of-distribution conditions. We design a suite of diagnostic tasks that train models on unimodal tasks or isolated reasoning skills, and evaluate them on multimodal, compositional variants requiring skill integration. Through comparisons between supervised fine-tuning (SFT) and RL-trained models, we identify three key findings: (1) RL-trained models consistently outperform SFT on compositional generalization, demonstrating better integration of learned skills; (2) although VLMs achieve strong performance on individual tasks, they struggle to generalize compositionally under cross-modal and cross-task scenario, revealing a significant gap in current training strategies; (3) enforcing models to explicitly describe visual content before reasoning (e.g., caption-before-thinking), along with rewarding progressive vision-to-text grounding, yields notable gains. It highlights two essential ingredients for improving compositionality in VLMs: visual-to-text alignment and accurate visual grounding. Our findings shed light on the current limitations of RL-based reasoning VLM training and provide actionable insights toward building models that reason compositionally across modalities and tasks.
SymAgent: A Neural-Symbolic Self-Learning Agent Framework for Complex Reasoning over Knowledge Graphs
Feb 05, 2025Recent advancements have highlighted that Large Language Models (LLMs) are prone to hallucinations when solving complex reasoning problems, leading to erroneous results. To tackle this issue, researchers incorporate Knowledge Graphs (KGs) to improve the reasoning ability of LLMs. However, existing methods face two limitations: 1) they typically assume that all answers to the questions are contained in KGs, neglecting the incompleteness issue of KGs, and 2) they treat the KG as a static repository and overlook the implicit logical reasoning structures inherent in KGs. In this paper, we introduce SymAgent, an innovative neural-symbolic agent framework that achieves collaborative augmentation between KGs and LLMs. We conceptualize KGs as dynamic environments and transform complex reasoning tasks into a multi-step interactive process, enabling KGs to participate deeply in the reasoning process. SymAgent consists of two modules: Agent-Planner and Agent-Executor. The Agent-Planner leverages LLM's inductive reasoning capability to extract symbolic rules from KGs, guiding efficient question decomposition. The Agent-Executor autonomously invokes predefined action tools to integrate information from KGs and external documents, addressing the issues of KG incompleteness. Furthermore, we design a self-learning framework comprising online exploration and offline iterative policy updating phases, enabling the agent to automatically synthesize reasoning trajectories and improve performance. Experimental results demonstrate that SymAgent with weak LLM backbones (i.e., 7B series) yields better or comparable performance compared to various strong baselines. Further analysis reveals that our agent can identify missing triples, facilitating automatic KG updates.
Filter-then-Generate: Large Language Models with Structure-Text Adapter for Knowledge Graph Completion
Dec 12, 2024



Large Language Models (LLMs) present massive inherent knowledge and superior semantic comprehension capability, which have revolutionized various tasks in natural language processing. Despite their success, a critical gap remains in enabling LLMs to perform knowledge graph completion (KGC). Empirical evidence suggests that LLMs consistently perform worse than conventional KGC approaches, even through sophisticated prompt design or tailored instruction-tuning. Fundamentally, applying LLMs on KGC introduces several critical challenges, including a vast set of entity candidates, hallucination issue of LLMs, and under-exploitation of the graph structure. To address these challenges, we propose a novel instruction-tuning-based method, namely FtG. Specifically, we present a \textit{filter-then-generate} paradigm and formulate the KGC task into a multiple-choice question format. In this way, we can harness the capability of LLMs while mitigating the issue casused by hallucinations. Moreover, we devise a flexible ego-graph serialization prompt and employ a structure-text adapter to couple structure and text information in a contextualized manner. Experimental results demonstrate that FtG achieves substantial performance gain compared to existing state-of-the-art methods. The instruction dataset and code are available at \url{https://github.com/LB0828/FtG}.
CLIP-MoE: Towards Building Mixture of Experts for CLIP with Diversified Multiplet Upcycling
Sep 28, 2024In recent years, Contrastive Language-Image Pre-training (CLIP) has become a cornerstone in multimodal intelligence. However, recent studies have identified that the information loss in the CLIP encoding process is substantial, and CLIP tends to capture only coarse-grained features from the input. This deficiency significantly limits the ability of a single CLIP model to handle images rich in visual detail. In this work, we propose a simple yet effective model-agnostic strategy, Diversified Multiplet Upcycling (DMU), for CLIP. DMU efficiently fine-tunes a series of CLIP models that capture different feature spaces, from a dense pre-trained CLIP checkpoint, sharing parameters except for the Feed-Forward Network (FFN). These models can then be transformed into a CLIP-MoE with a larger model capacity, leading to significantly enhanced performance with minimal computational overhead. To the best of our knowledge, Diversified Multiplet Upcycling is the first approach to introduce sparsely activated MoE into CLIP foundation models. Extensive experiments demonstrate the significant performance of CLIP-MoE across various zero-shot retrieval, zero-shot image classification tasks, and downstream Multimodal Large Language Model (MLLM) benchmarks by serving as a vision encoder. Furthermore, Diversified Multiplet Upcycling enables the conversion of any dense CLIP model into CLIP-MoEs, which can seamlessly replace CLIP in a plug-and-play manner without requiring further adaptation in downstream frameworks. Through Diversified Multiplet Upcycling, we aim to provide valuable insights for future research on developing more efficient and effective multimodal learning systems.
SURf: Teaching Large Vision-Language Models to Selectively Utilize Retrieved Information
Sep 21, 2024



Large Vision-Language Models (LVLMs) have become pivotal at the intersection of computer vision and natural language processing. However, the full potential of LVLMs Retrieval-Augmented Generation (RAG) capabilities remains underutilized. Existing works either focus solely on the text modality or are limited to specific tasks. Moreover, most LVLMs struggle to selectively utilize retrieved information and are sensitive to irrelevant or misleading references. To address these challenges, we propose a self-refinement framework designed to teach LVLMs to Selectively Utilize Retrieved Information (SURf). Specifically, when given questions that are incorrectly answered by the LVLM backbone, we obtain references that help correct the answers (positive references) and those that do not (negative references). We then fine-tune the LVLM backbone using a combination of these positive and negative references. Our experiments across three tasks and seven datasets demonstrate that our framework significantly enhances LVLMs ability to effectively utilize retrieved multimodal references and improves their robustness against irrelevant or misleading information. The source code is available at https://github.com/GasolSun36/SURf.
Solving General Natural-Language-Description Optimization Problems with Large Language Models
Jul 09, 2024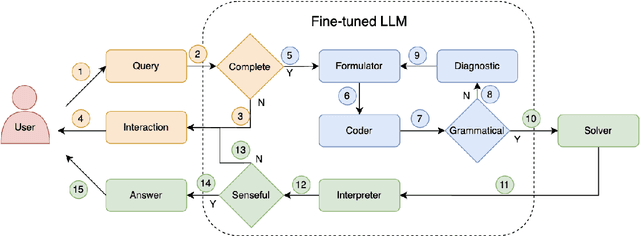


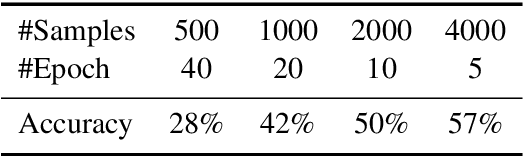
Optimization problems seek to find the best solution to an objective under a set of constraints, and have been widely investigated in real-world applications. Modeling and solving optimization problems in a specific domain typically require a combination of domain knowledge, mathematical skills, and programming ability, making it difficult for general users and even domain professionals. In this paper, we propose a novel framework called OptLLM that augments LLMs with external solvers. Specifically, OptLLM accepts user queries in natural language, convert them into mathematical formulations and programming codes, and calls the solvers to calculate the results for decision-making. In addition, OptLLM supports multi-round dialogues to gradually refine the modeling and solving of optimization problems. To illustrate the effectiveness of OptLLM, we provide tutorials on three typical optimization applications and conduct experiments on both prompt-based GPT models and a fine-tuned Qwen model using a large-scale selfdeveloped optimization dataset. Experimental results show that OptLLM works with various LLMs, and the fine-tuned model achieves an accuracy boost compared to the promptbased models. Some features of OptLLM framework have been available for trial since June 2023 (https://opt.alibabacloud.com/chat or https://opt.aliyun.com/chat).
Avoiding Feature Suppression in Contrastive Learning: Learning What Has Not Been Learned Before
Feb 19, 2024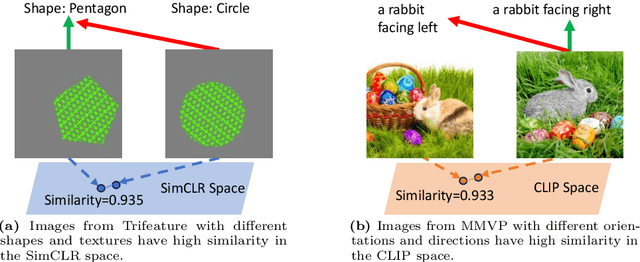



Self-Supervised contrastive learning has emerged as a powerful method for obtaining high-quality representations from unlabeled data. However, feature suppression has recently been identified in standard contrastive learning ($e.g.$, SimCLR, CLIP): in a single end-to-end training stage, the contrastive model captures only parts of the shared information across contrasting views, while ignore the other potentially useful information. With feature suppression, contrastive models often fail to learn sufficient representations capable for various downstream tasks. To mitigate the feature suppression problem and ensure the contrastive model to learn comprehensive representations, we develop a novel Multistage Contrastive Learning (MCL) framework. Unlike standard contrastive learning that often result in feature suppression, MCL progressively learn new features that have not been explored in the previous stage, while maintaining the well-learned features. Extensive experiments conducted on various publicly available benchmarks validate the effectiveness of our proposed framework. In addition, we demonstrate that the proposed MCL can be adapted to a variety of popular contrastive learning backbones and boost their performance by learning features that could not be gained from standard contrastive learning procedures.
A Stochastic Online Forecast-and-Optimize Framework for Real-Time Energy Dispatch in Virtual Power Plants under Uncertainty
Sep 15, 2023Aggregating distributed energy resources in power systems significantly increases uncertainties, in particular caused by the fluctuation of renewable energy generation. This issue has driven the necessity of widely exploiting advanced predictive control techniques under uncertainty to ensure long-term economics and decarbonization. In this paper, we propose a real-time uncertainty-aware energy dispatch framework, which is composed of two key elements: (i) A hybrid forecast-and-optimize sequential task, integrating deep learning-based forecasting and stochastic optimization, where these two stages are connected by the uncertainty estimation at multiple temporal resolutions; (ii) An efficient online data augmentation scheme, jointly involving model pre-training and online fine-tuning stages. In this way, the proposed framework is capable to rapidly adapt to the real-time data distribution, as well as to target on uncertainties caused by data drift, model discrepancy and environment perturbations in the control process, and finally to realize an optimal and robust dispatch solution. The proposed framework won the championship in CityLearn Challenge 2022, which provided an influential opportunity to investigate the potential of AI application in the energy domain. In addition, comprehensive experiments are conducted to interpret its effectiveness in the real-life scenario of smart building energy management.