 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBirds of a Feather Trust Together: Knowing When to Trust a Classifier via Adaptive Neighborhood Aggregation
Paper and Code



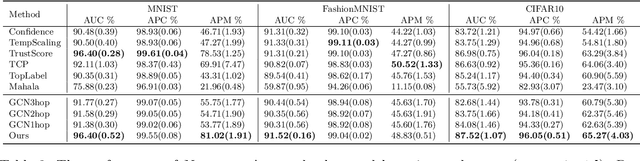
How do we know when the predictions made by a classifier can be trusted? This is a fundamental problem that also has immense practical applicability, especially in safety-critical areas such as medicine and autonomous driving. The de facto approach of using the classifier's softmax outputs as a proxy for trustworthiness suffers from the over-confidence issue; while the most recent works incur problems such as additional retraining cost and accuracy versus trustworthiness trade-off. In this work, we argue that the trustworthiness of a classifier's prediction for a sample is highly associated with two factors: the sample's neighborhood information and the classifier's output. To combine the best of both worlds, we design a model-agnostic post-hoc approach NeighborAgg to leverage the two essential information via an adaptive neighborhood aggregation. Theoretically, we show that NeighborAgg is a generalized version of a one-hop graph convolutional network, inheriting the powerful modeling ability to capture the varying similarity between samples within each class. We also extend our approach to the closely related task of mislabel detection and provide a theoretical coverage guarantee to bound the false negative. Empirically, extensive experiments on image and tabular benchmarks verify our theory and suggest that NeighborAgg outperforms other methods, achieving state-of-the-art trustworthiness performance.