 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Reranker: Boundary-Aware Evidence Selection for Robust Retrieval-Augmented Generation
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems remain brittle under realistic retrieval noise, even when the required evidence appears in the top-K results. A key reason is that retrievers and rerankers optimize solely for relevance, often selecting either trivial, answer-revealing passages or evidence that lacks the critical information required to answer the question, without considering whether the evidence is suitable for the generator. We propose BAR-RAG, which reframes the reranker as a boundary-aware evidence selector that targets the generator's Goldilocks Zone -- evidence that is neither trivially easy nor fundamentally unanswerable for the generator, but is challenging yet sufficient for inference and thus provides the strongest learning signal. BAR-RAG trains the selector with reinforcement learning using generator feedback, and adopts a two-stage pipeline that fine-tunes the generator under the induced evidence distribution to mitigate the distribution mismatch between training and inference. Experiments on knowledge-intensive question answering benchmarks show that BAR-RAG consistently improves end-to-end performance under noisy retrieval, achieving an average gain of 10.3 percent over strong RAG and reranking baselines while substantially improving robustness. Code is publicly avaliable at https://github.com/GasolSun36/BAR-RAG.
BibAgent: An Agentic Framework for Traceable Miscitation Detection in Scientific Literature
Jan 12, 2026Citations are the bedrock of scientific authority, yet their integrity is compromised by widespread miscitations: ranging from nuanced distortions to fabricated references. Systematic citation verification is currently unfeasible; manual review cannot scale to modern publishing volumes, while existing automated tools are restricted by abstract-only analysis or small-scale, domain-specific datasets in part due to the "paywall barrier" of full-text access. We introduce BibAgent, a scalable, end-to-end agentic framework for automated citation verification. BibAgent integrates retrieval, reasoning, and adaptive evidence aggregation, applying distinct strategies for accessible and paywalled sources. For paywalled references, it leverages a novel Evidence Committee mechanism that infers citation validity via downstream citation consensus. To support systematic evaluation, we contribute a 5-category Miscitation Taxonomy and MisciteBench, a massive cross-disciplinary benchmark comprising 6,350 miscitation samples spanning 254 fields. Our results demonstrate that BibAgent outperforms state-of-the-art Large Language Model (LLM) baselines in citation verification accuracy and interpretability, providing scalable, transparent detection of citation misalignments across the scientific literature.
Adaptation of Agentic AI
Dec 22, 2025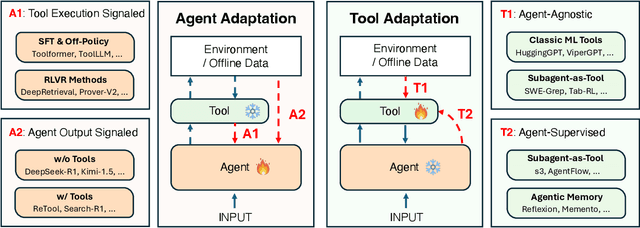
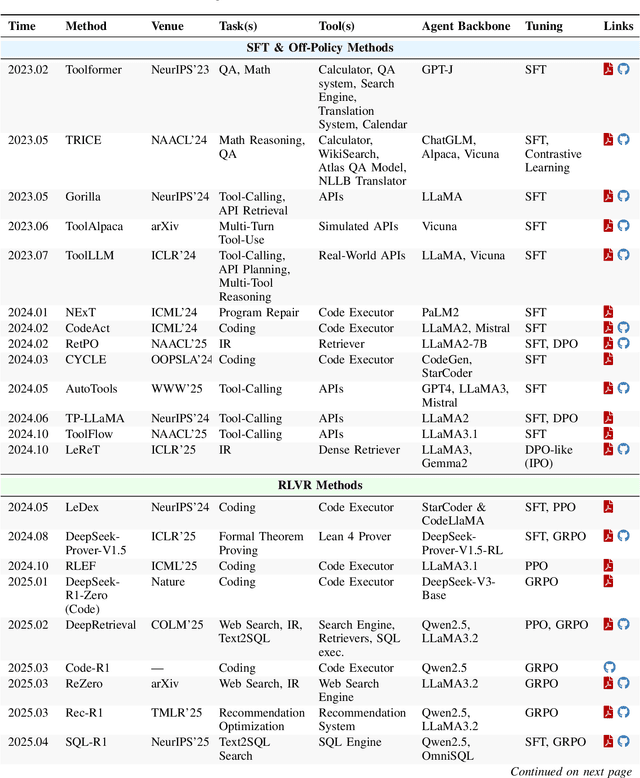
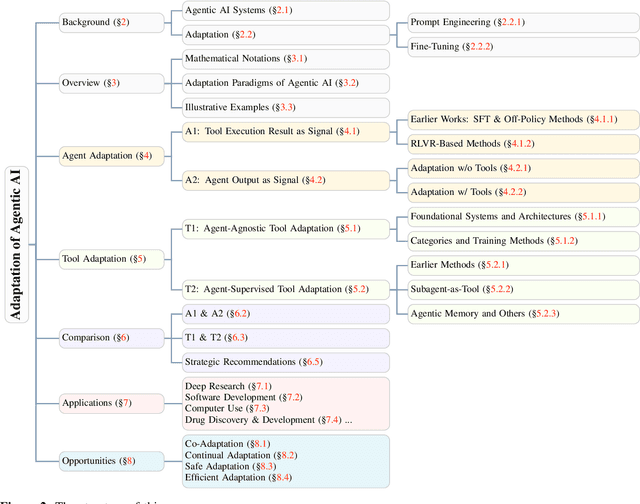
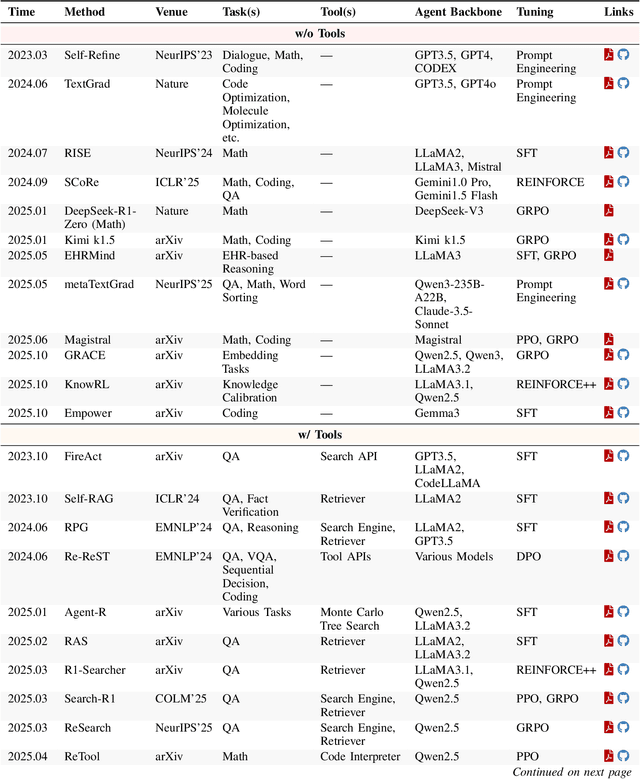
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
GRACE: Generative Representation Learning via Contrastive Policy Optimization
Oct 06, 2025Prevailing methods for training Large Language Models (LLMs) as text encoders rely on contrastive losses that treat the model as a black box function, discarding its generative and reasoning capabilities in favor of static embeddings. We introduce GRACE (Generative Representation Learning via Contrastive Policy Optimization), a novel framework that reimagines contrastive signals not as losses to be minimized, but as rewards that guide a generative policy. In GRACE, the LLM acts as a policy that produces explicit, human-interpretable rationales--structured natural language explanations of its semantic understanding. These rationales are then encoded into high-quality embeddings via mean pooling. Using policy gradient optimization, we train the model with a multi-component reward function that maximizes similarity between query positive pairs and minimizes similarity with negatives. This transforms the LLM from an opaque encoder into an interpretable agent whose reasoning process is transparent and inspectable. On MTEB benchmark, GRACE yields broad cross category gains: averaged over four backbones, the supervised setting improves overall score by 11.5% over base models, and the unsupervised variant adds 6.9%, while preserving general capabilities. This work treats contrastive objectives as rewards over rationales, unifying representation learning with generation to produce stronger embeddings and transparent rationales. The model, data and code are available at https://github.com/GasolSun36/GRACE.
DynamicRAG: Leveraging Outputs of Large Language Model as Feedback for Dynamic Reranking in Retrieval-Augmented Generation
May 12, 2025Retrieval-augmented generation (RAG) systems combine large language models (LLMs) with external knowledge retrieval, making them highly effective for knowledge-intensive tasks. A crucial but often under-explored component of these systems is the reranker, which refines retrieved documents to enhance generation quality and explainability. The challenge of selecting the optimal number of documents (k) remains unsolved: too few may omit critical information, while too many introduce noise and inefficiencies. Although recent studies have explored LLM-based rerankers, they primarily leverage internal model knowledge and overlook the rich supervisory signals that LLMs can provide, such as using response quality as feedback for optimizing reranking decisions. In this paper, we propose DynamicRAG, a novel RAG framework where the reranker dynamically adjusts both the order and number of retrieved documents based on the query. We model the reranker as an agent optimized through reinforcement learning (RL), using rewards derived from LLM output quality. Across seven knowledge-intensive datasets, DynamicRAG demonstrates superior performance, achieving state-of-the-art results. The model, data and code are available at https://github.com/GasolSun36/DynamicRAG
Benchmarking Multimodal Mathematical Reasoning with Explicit Visual Dependency
Apr 29, 2025Recent advancements in Large Vision-Language Models (LVLMs) have significantly enhanced their ability to integrate visual and linguistic information, achieving near-human proficiency in tasks like object recognition, captioning, and visual question answering. However, current benchmarks typically focus on knowledge-centric evaluations that assess domain-specific expertise, often neglecting the core ability to reason about fundamental mathematical elements and visual concepts. We identify a gap in evaluating elementary-level math problems, which rely on explicit visual dependencies-requiring models to discern, integrate, and reason across multiple images while incorporating commonsense knowledge, all of which are crucial for advancing toward broader AGI capabilities. To address this gap, we introduce VCBENCH, a comprehensive benchmark for multimodal mathematical reasoning with explicit visual dependencies. VCBENCH includes 1,720 problems across six cognitive domains, featuring 6,697 images (averaging 3.9 per question) to ensure multi-image reasoning. We evaluate 26 state-of-the-art LVLMs on VCBENCH, revealing substantial performance disparities, with even the top models unable to exceed 50% accuracy. Our findings highlight the ongoing challenges in visual-mathematical integration and suggest avenues for future LVLM advancements.
From Captions to Rewards (CAREVL): Leveraging Large Language Model Experts for Enhanced Reward Modeling in Large Vision-Language Models
Mar 08, 2025
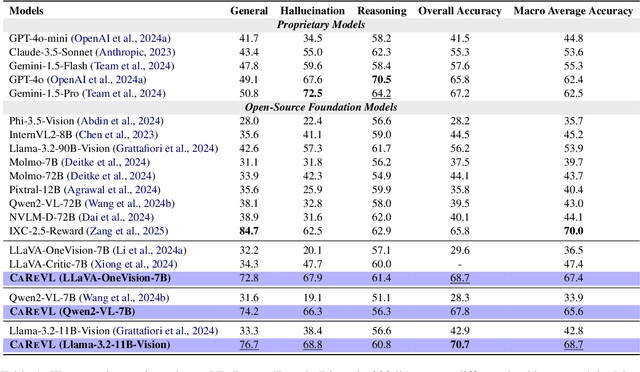
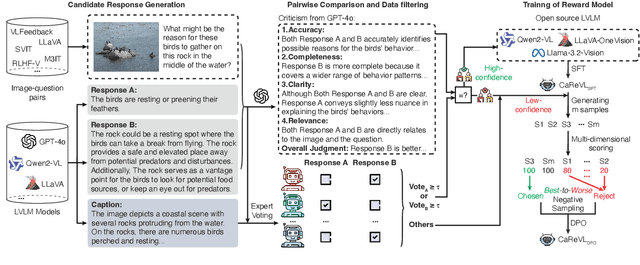
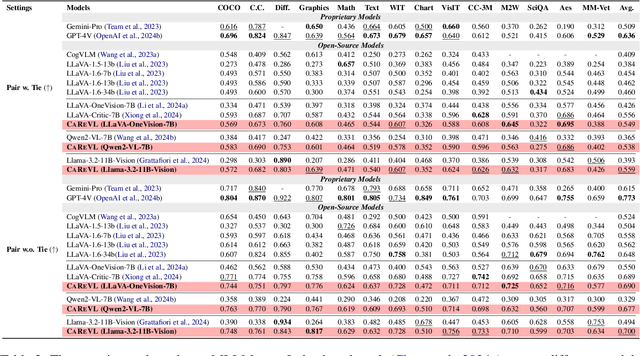
Aligning large vision-language models (LVLMs) with human preferences is challenging due to the scarcity of fine-grained, high-quality, and multimodal preference data without human annotations. Existing methods relying on direct distillation often struggle with low-confidence data, leading to suboptimal performance. To address this, we propose CAREVL, a novel method for preference reward modeling by reliably using both high- and low-confidence data. First, a cluster of auxiliary expert models (textual reward models) innovatively leverages image captions as weak supervision signals to filter high-confidence data. The high-confidence data are then used to fine-tune the LVLM. Second, low-confidence data are used to generate diverse preference samples using the fine-tuned LVLM. These samples are then scored and selected to construct reliable chosen-rejected pairs for further training. CAREVL achieves performance improvements over traditional distillation-based methods on VL-RewardBench and MLLM-as-a-Judge benchmark, demonstrating its effectiveness. The code will be released soon.
2.5 Years in Class: A Multimodal Textbook for Vision-Language Pretraining
Jan 03, 2025



Compared to image-text pair data, interleaved corpora enable Vision-Language Models (VLMs) to understand the world more naturally like humans. However, such existing datasets are crawled from webpage, facing challenges like low knowledge density, loose image-text relations, and poor logical coherence between images. On the other hand, the internet hosts vast instructional videos (e.g., online geometry courses) that are widely used by humans to learn foundational subjects, yet these valuable resources remain underexplored in VLM training. In this paper, we introduce a high-quality \textbf{multimodal textbook} corpus with richer foundational knowledge for VLM pretraining. It collects over 2.5 years of instructional videos, totaling 22,000 class hours. We first use an LLM-proposed taxonomy to systematically gather instructional videos. Then we progressively extract and refine visual (keyframes), audio (ASR), and textual knowledge (OCR) from the videos, and organize as an image-text interleaved corpus based on temporal order. Compared to its counterparts, our video-centric textbook offers more coherent context, richer knowledge, and better image-text alignment. Experiments demonstrate its superb pretraining performance, particularly in knowledge- and reasoning-intensive tasks like ScienceQA and MathVista. Moreover, VLMs pre-trained on our textbook exhibit outstanding interleaved context awareness, leveraging visual and textual cues in their few-shot context for task solving~\footnote{Our code are available at \url{https://github.com/DAMO-NLP-SG/multimodal_textbook}}.
SURf: Teaching Large Vision-Language Models to Selectively Utilize Retrieved Information
Sep 21, 2024



Large Vision-Language Models (LVLMs) have become pivotal at the intersection of computer vision and natural language processing. However, the full potential of LVLMs Retrieval-Augmented Generation (RAG) capabilities remains underutilized. Existing works either focus solely on the text modality or are limited to specific tasks. Moreover, most LVLMs struggle to selectively utilize retrieved information and are sensitive to irrelevant or misleading references. To address these challenges, we propose a self-refinement framework designed to teach LVLMs to Selectively Utilize Retrieved Information (SURf). Specifically, when given questions that are incorrectly answered by the LVLM backbone, we obtain references that help correct the answers (positive references) and those that do not (negative references). We then fine-tune the LVLM backbone using a combination of these positive and negative references. Our experiments across three tasks and seven datasets demonstrate that our framework significantly enhances LVLMs ability to effectively utilize retrieved multimodal references and improves their robustness against irrelevant or misleading information. The source code is available at https://github.com/GasolSun36/SURf.
Look, Compare, Decide: Alleviating Hallucination in Large Vision-Language Models via Multi-View Multi-Path Reasoning
Aug 30, 2024



Recently, Large Vision-Language Models (LVLMs) have demonstrated impressive capabilities in multi-modal context comprehension. However, they still suffer from hallucination problems referring to generating inconsistent outputs with the image content. To mitigate hallucinations, previous studies mainly focus on retraining LVLMs with custom datasets. Although effective, they inherently come with additional computational costs. In this paper, we propose a training-free framework, \textbf{MVP}, that aims to reduce hallucinations by making the most of the innate capabilities of the LVLMs via \textbf{M}ulti-\textbf{V}iew Multi-\textbf{P}ath Reasoning. Specifically, we first devise a multi-view information-seeking strategy to thoroughly perceive the comprehensive information in the image, which enriches the general global information captured by the original vision encoder in LVLMs. Furthermore, during the answer decoding, we observe that the occurrence of hallucinations has a strong correlation with the certainty of the answer tokens. Thus, we propose multi-path reasoning for each information view to quantify and aggregate the certainty scores for each potential answer among multiple decoding paths and finally decide the output answer. By fully grasping the information in the image and carefully considering the certainty of the potential answers when decoding, our MVP can effectively reduce hallucinations in LVLMs.The extensive experiments verify that our proposed MVP significantly mitigates the hallucination problem across four well-known LVLMs. The source code is available at: \url{https://github.com/GasolSun36/MVP}.