 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval is Cheap, Show Me the Code: Executable Multi-Hop Reasoning for Retrieval-Augmented Generation
May 13, 2026Retrieval-Augmented Generation (RAG) has become a standard approach for knowledge-intensive question answering, but existing systems remain brittle on multi-hop questions, where solving the task requires chaining multiple retrieval and reasoning steps. Key challenges are that current methods represent reasoning through free-form natural language, where intermediate states are implicit, retrieval queries can drift from intended entities, and errors are detected by the same model that produces them making self-reflection an unreliable, ungrounded signal. We observe that multi-hop question answering is a typical form of step-by-step computation, and that this structured process aligns closely with how code-specialized language models are trained to operate. Motivated by this, we introduce \pyrag, a framework that reformulates multi-hop RAG as program synthesis and execution. Instead of free-form reasoning trajectories, \pyrag represents the reasoning process as an executable Python program over retrieval and QA tools, exposing intermediate states as variables, producing deterministic feedback through execution, and yielding an inspectable trace of the entire reasoning process. This formulation further enables compiler-grounded self-repair and execution-driven adaptive retrieval without any additional training. Experiments on five QA benchmarks (PopQA, HotpotQA, 2WikiMultihopQA, MuSiQue, and Bamboogle) show that \pyrag consistently outperforms strong baselines under both training-free and RL-trained settings, with especially large gains on compositional multi-hop datasets. Our code, data and models are publicly available at https://github.com/GasolSun36/PyRAG.
Rethinking the Reranker: Boundary-Aware Evidence Selection for Robust Retrieval-Augmented Generation
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems remain brittle under realistic retrieval noise, even when the required evidence appears in the top-K results. A key reason is that retrievers and rerankers optimize solely for relevance, often selecting either trivial, answer-revealing passages or evidence that lacks the critical information required to answer the question, without considering whether the evidence is suitable for the generator. We propose BAR-RAG, which reframes the reranker as a boundary-aware evidence selector that targets the generator's Goldilocks Zone -- evidence that is neither trivially easy nor fundamentally unanswerable for the generator, but is challenging yet sufficient for inference and thus provides the strongest learning signal. BAR-RAG trains the selector with reinforcement learning using generator feedback, and adopts a two-stage pipeline that fine-tunes the generator under the induced evidence distribution to mitigate the distribution mismatch between training and inference. Experiments on knowledge-intensive question answering benchmarks show that BAR-RAG consistently improves end-to-end performance under noisy retrieval, achieving an average gain of 10.3 percent over strong RAG and reranking baselines while substantially improving robustness. Code is publicly avaliable at https://github.com/GasolSun36/BAR-RAG.
QuantBench: Benchmarking AI Methods for Quantitative Investment
Apr 24, 2025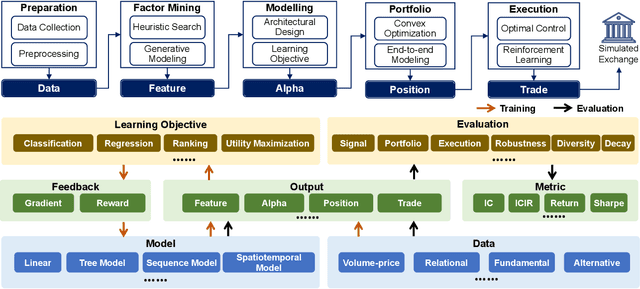



The field of artificial intelligence (AI) in quantitative investment has seen significant advancements, yet it lacks a standardized benchmark aligned with industry practices. This gap hinders research progress and limits the practical application of academic innovations. We present QuantBench, an industrial-grade benchmark platform designed to address this critical need. QuantBench offers three key strengths: (1) standardization that aligns with quantitative investment industry practices, (2) flexibility to integrate various AI algorithms, and (3) full-pipeline coverage of the entire quantitative investment process. Our empirical studies using QuantBench reveal some critical research directions, including the need for continual learning to address distribution shifts, improved methods for modeling relational financial data, and more robust approaches to mitigate overfitting in low signal-to-noise environments. By providing a common ground for evaluation and fostering collaboration between researchers and practitioners, QuantBench aims to accelerate progress in AI for quantitative investment, similar to the impact of benchmark platforms in computer vision and natural language processing.
From Deep Learning to LLMs: A survey of AI in Quantitative Investment
Mar 27, 2025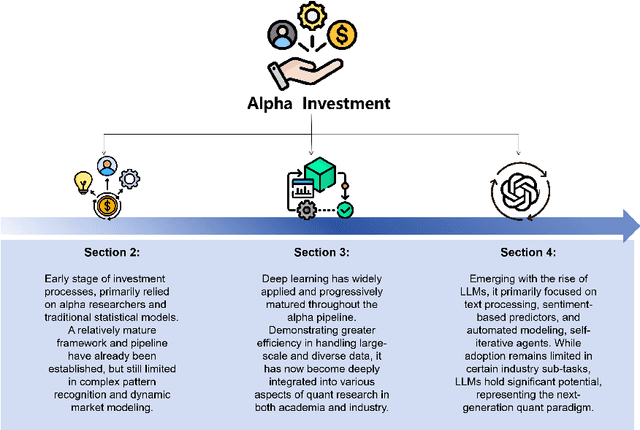
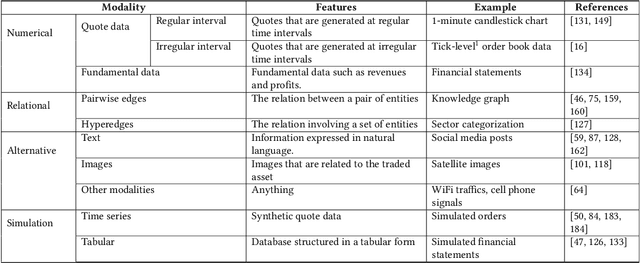
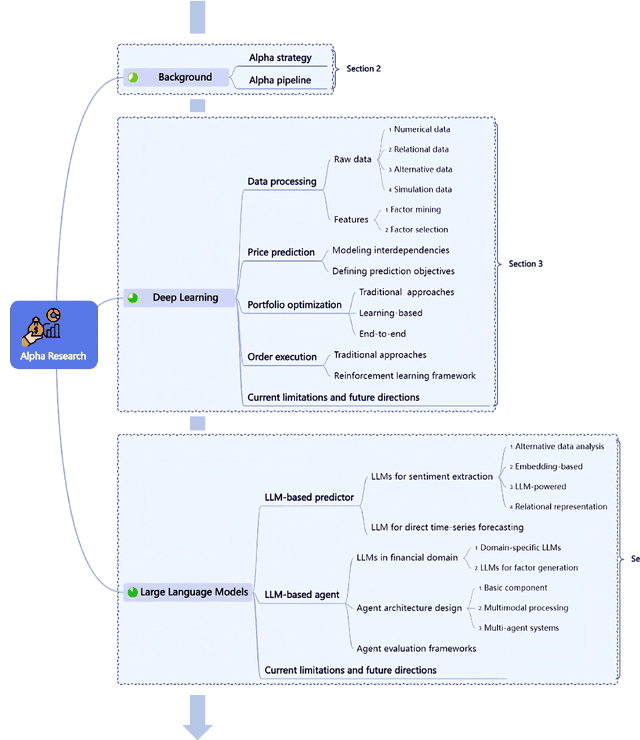
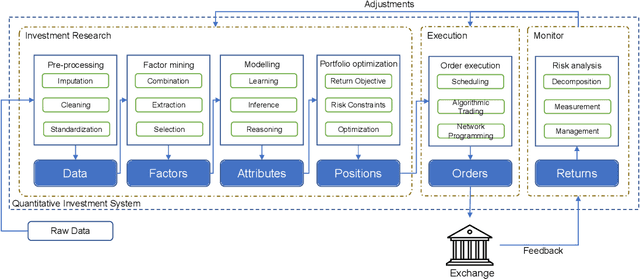
Quantitative investment (quant) is an emerging, technology-driven approach in asset management, increasingy shaped by advancements in artificial intelligence. Recent advances in deep learning and large language models (LLMs) for quant finance have improved predictive modeling and enabled agent-based automation, suggesting a potential paradigm shift in this field. In this survey, taking alpha strategy as a representative example, we explore how AI contributes to the quantitative investment pipeline. We first examine the early stage of quant research, centered on human-crafted features and traditional statistical models with an established alpha pipeline. We then discuss the rise of deep learning, which enabled scalable modeling across the entire pipeline from data processing to order execution. Building on this, we highlight the emerging role of LLMs in extending AI beyond prediction, empowering autonomous agents to process unstructured data, generate alphas, and support self-iterative workflows.
Guided Learning: Lubricating End-to-End Modeling for Multi-stage Decision-making
Nov 15, 2024


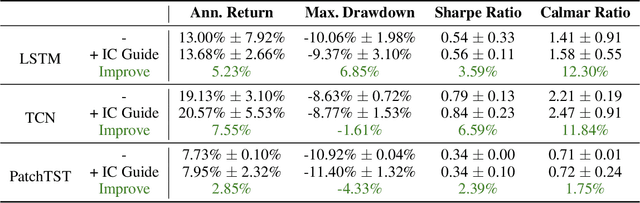
Multi-stage decision-making is crucial in various real-world artificial intelligence applications, including recommendation systems, autonomous driving, and quantitative investment systems. In quantitative investment, for example, the process typically involves several sequential stages such as factor mining, alpha prediction, portfolio optimization, and sometimes order execution. While state-of-the-art end-to-end modeling aims to unify these stages into a single global framework, it faces significant challenges: (1) training such a unified neural network consisting of multiple stages between initial inputs and final outputs often leads to suboptimal solutions, or even collapse, and (2) many decision-making scenarios are not easily reducible to standard prediction problems. To overcome these challenges, we propose Guided Learning, a novel methodological framework designed to enhance end-to-end learning in multi-stage decision-making. We introduce the concept of a ``guide'', a function that induces the training of intermediate neural network layers towards some phased goals, directing gradients away from suboptimal collapse. For decision scenarios lacking explicit supervisory labels, we incorporate a utility function that quantifies the ``reward'' of the throughout decision. Additionally, we explore the connections between Guided Learning and classic machine learning paradigms such as supervised, unsupervised, semi-supervised, multi-task, and reinforcement learning. Experiments on quantitative investment strategy building demonstrate that guided learning significantly outperforms both traditional stage-wise approaches and existing end-to-end methods.
Golden Touchstone: A Comprehensive Bilingual Benchmark for Evaluating Financial Large Language Models
Nov 09, 2024



As large language models become increasingly prevalent in the financial sector, there is a pressing need for a standardized method to comprehensively assess their performance. However, existing finance benchmarks often suffer from limited language and task coverage, as well as challenges such as low-quality datasets and inadequate adaptability for LLM evaluation. To address these limitations, we propose "Golden Touchstone", the first comprehensive bilingual benchmark for financial LLMs, which incorporates representative datasets from both Chinese and English across eight core financial NLP tasks. Developed from extensive open source data collection and industry-specific demands, this benchmark includes a variety of financial tasks aimed at thoroughly assessing models' language understanding and generation capabilities. Through comparative analysis of major models on the benchmark, such as GPT-4o Llama3, FinGPT and FinMA, we reveal their strengths and limitations in processing complex financial information. Additionally, we open-sourced Touchstone-GPT, a financial LLM trained through continual pre-training and financial instruction tuning, which demonstrates strong performance on the bilingual benchmark but still has limitations in specific tasks.This research not only provides the financial large language models with a practical evaluation tool but also guides the development and optimization of future research. The source code for Golden Touchstone and model weight of Touchstone-GPT have been made publicly available at \url{https://github.com/IDEA-FinAI/Golden-Touchstone}, contributing to the ongoing evolution of FinLLMs and fostering further research in this critical area.
Alpha-GPT 2.0: Human-in-the-Loop AI for Quantitative Investment
Feb 15, 2024

Recently, we introduced a new paradigm for alpha mining in the realm of quantitative investment, developing a new interactive alpha mining system framework, Alpha-GPT. This system is centered on iterative Human-AI interaction based on large language models, introducing a Human-in-the-Loop approach to alpha discovery. In this paper, we present the next-generation Alpha-GPT 2.0 \footnote{Draft. Work in progress}, a quantitative investment framework that further encompasses crucial modeling and analysis phases in quantitative investment. This framework emphasizes the iterative, interactive research between humans and AI, embodying a Human-in-the-Loop strategy throughout the entire quantitative investment pipeline. By assimilating the insights of human researchers into the systematic alpha research process, we effectively leverage the Human-in-the-Loop approach, enhancing the efficiency and precision of quantitative investment research.
QuantAgent: Seeking Holy Grail in Trading by Self-Improving Large Language Model
Feb 06, 2024Autonomous agents based on Large Language Models (LLMs) that devise plans and tackle real-world challenges have gained prominence.However, tailoring these agents for specialized domains like quantitative investment remains a formidable task. The core challenge involves efficiently building and integrating a domain-specific knowledge base for the agent's learning process. This paper introduces a principled framework to address this challenge, comprising a two-layer loop.In the inner loop, the agent refines its responses by drawing from its knowledge base, while in the outer loop, these responses are tested in real-world scenarios to automatically enhance the knowledge base with new insights.We demonstrate that our approach enables the agent to progressively approximate optimal behavior with provable efficiency.Furthermore, we instantiate this framework through an autonomous agent for mining trading signals named QuantAgent. Empirical results showcase QuantAgent's capability in uncovering viable financial signals and enhancing the accuracy of financial forecasts.
A Principled Framework for Knowledge-enhanced Large Language Model
Nov 18, 2023
Large Language Models (LLMs) are versatile, yet they often falter in tasks requiring deep and reliable reasoning due to issues like hallucinations, limiting their applicability in critical scenarios. This paper introduces a rigorously designed framework for creating LLMs that effectively anchor knowledge and employ a closed-loop reasoning process, enhancing their capability for in-depth analysis. We dissect the framework to illustrate the contribution of each component to the LLMs' performance, offering a theoretical assurance of improved reasoning under well-defined assumptions.
On the Evolution of Knowledge Graphs: A Survey and Perspective
Oct 10, 2023



Knowledge graphs (KGs) are structured representations of diversified knowledge. They are widely used in various intelligent applications. In this article, we provide a comprehensive survey on the evolution of various types of knowledge graphs (i.e., static KGs, dynamic KGs, temporal KGs, and event KGs) and techniques for knowledge extraction and reasoning. Furthermore, we introduce the practical applications of different types of KGs, including a case study in financial analysis. Finally, we propose our perspective on the future directions of knowledge engineering, including the potential of combining the power of knowledge graphs and large language models (LLMs), and the evolution of knowledge extraction, reasoning, and representation.