 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGolden Touchstone: A Comprehensive Bilingual Benchmark for Evaluating Financial Large Language Models
Nov 09, 2024



As large language models become increasingly prevalent in the financial sector, there is a pressing need for a standardized method to comprehensively assess their performance. However, existing finance benchmarks often suffer from limited language and task coverage, as well as challenges such as low-quality datasets and inadequate adaptability for LLM evaluation. To address these limitations, we propose "Golden Touchstone", the first comprehensive bilingual benchmark for financial LLMs, which incorporates representative datasets from both Chinese and English across eight core financial NLP tasks. Developed from extensive open source data collection and industry-specific demands, this benchmark includes a variety of financial tasks aimed at thoroughly assessing models' language understanding and generation capabilities. Through comparative analysis of major models on the benchmark, such as GPT-4o Llama3, FinGPT and FinMA, we reveal their strengths and limitations in processing complex financial information. Additionally, we open-sourced Touchstone-GPT, a financial LLM trained through continual pre-training and financial instruction tuning, which demonstrates strong performance on the bilingual benchmark but still has limitations in specific tasks.This research not only provides the financial large language models with a practical evaluation tool but also guides the development and optimization of future research. The source code for Golden Touchstone and model weight of Touchstone-GPT have been made publicly available at \url{https://github.com/IDEA-FinAI/Golden-Touchstone}, contributing to the ongoing evolution of FinLLMs and fostering further research in this critical area.
AVR: Attention based Salient Visual Relationship Detection
Mar 16, 2020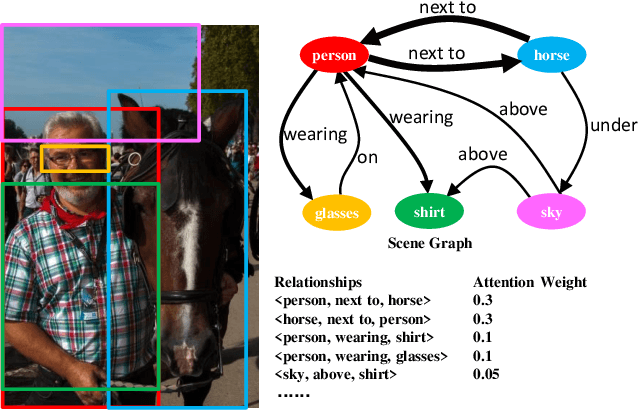
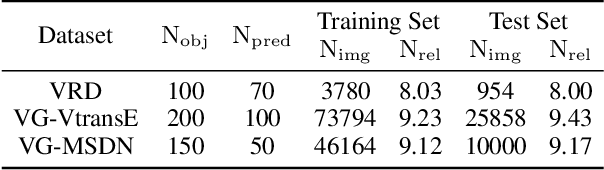
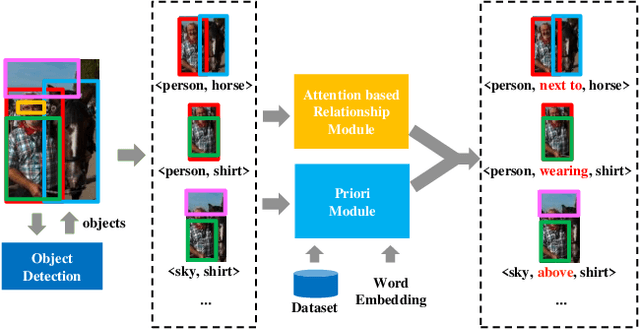
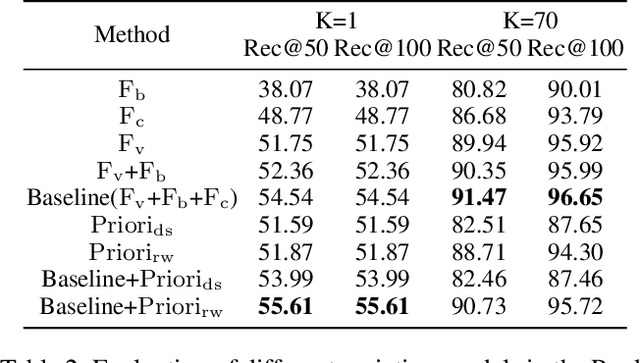
Visual relationship detection aims to locate objects in images and recognize the relationships between objects. Traditional methods treat all observed relationships in an image equally, which causes a relatively poor performance in the detection tasks on complex images with abundant visual objects and various relationships. To address this problem, we propose an attention based model, namely AVR, to achieve salient visual relationships based on both local and global context of the relationships. Specifically, AVR recognizes relationships and measures the attention on the relationships in the local context of an input image by fusing the visual features, semantic and spatial information of the relationships. AVR then applies the attention to assign important relationships with larger salient weights for effective information filtering. Furthermore, AVR is integrated with the priori knowledge in the global context of image datasets to improve the precision of relationship prediction, where the context is modeled as a heterogeneous graph to measure the priori probability of relationships based on the random walk algorithm. Comprehensive experiments are conducted to demonstrate the effectiveness of AVR in several real-world image datasets, and the results show that AVR outperforms state-of-the-art visual relationship detection methods significantly by up to $87.5\%$ in terms of recall.