 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlying Base Stations for Offshore Wind Farm Monitoring and Control: Holistic Performance Evaluation and Optimization
Jul 10, 2025Ensuring reliable and low-latency communication in offshore wind farms is critical for efficient monitoring and control, yet remains challenging due to the harsh environment and lack of infrastructure. This paper investigates a flying base station (FBS) approach for wide-area monitoring and control in the UK Hornsea offshore wind farm project. By leveraging mobile, flexible FBS platforms in the remote and harsh offshore environment, the proposed system offers real-time connectivity for turbines without the need for deploying permanent infrastructure at the sea. We develop a detailed and practical end-to-end latency model accounting for five key factors: flight duration, connection establishment, turbine state information upload, computational delay, and control transmission, to provide a holistic perspective often missing in prior studies. Furthermore, we combine trajectory planning, beamforming, and resource allocation into a multi-objective optimization framework for the overall latency minimization, specifically designed for large-scale offshore wind farm deployments. Simulation results verify the effectiveness of our proposed method in minimizing latency and enhancing efficiency in FBS-assisted offshore monitoring across various power levels, while consistently outperforming baseline designs.
From Deep Learning to LLMs: A survey of AI in Quantitative Investment
Mar 27, 2025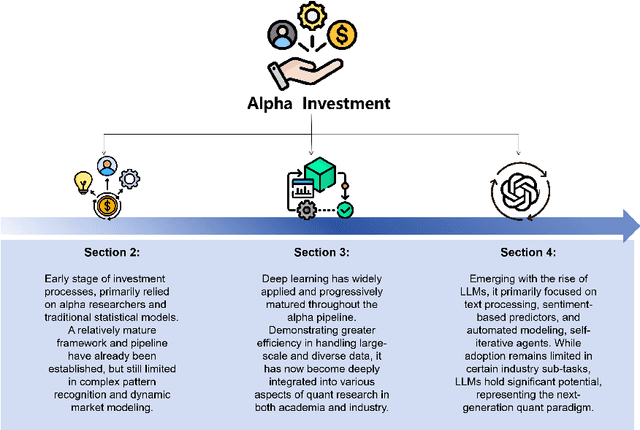
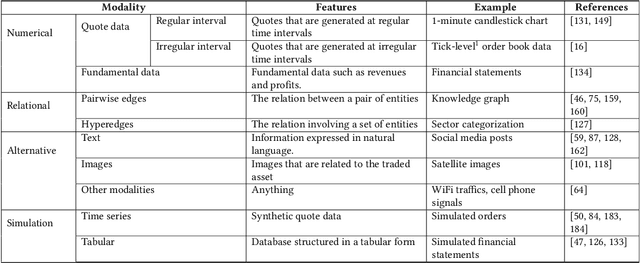
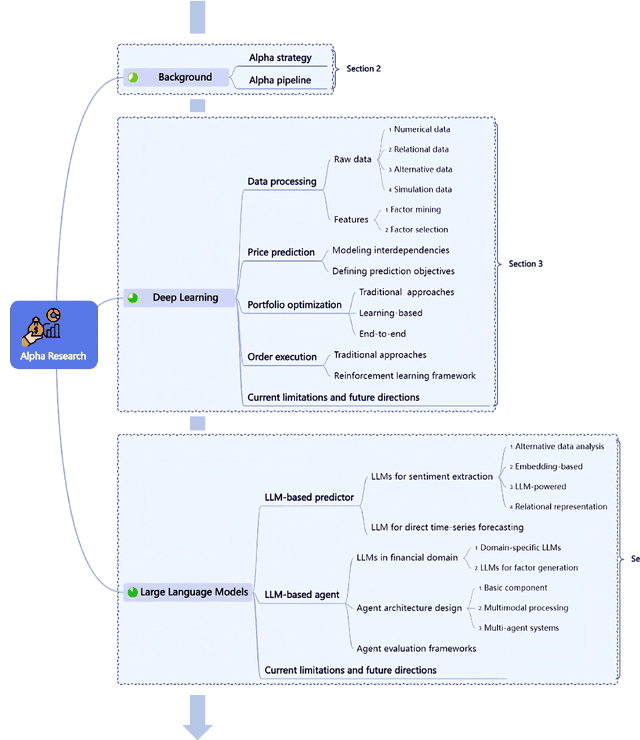
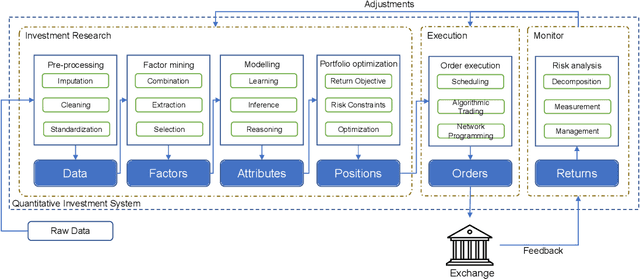
Quantitative investment (quant) is an emerging, technology-driven approach in asset management, increasingy shaped by advancements in artificial intelligence. Recent advances in deep learning and large language models (LLMs) for quant finance have improved predictive modeling and enabled agent-based automation, suggesting a potential paradigm shift in this field. In this survey, taking alpha strategy as a representative example, we explore how AI contributes to the quantitative investment pipeline. We first examine the early stage of quant research, centered on human-crafted features and traditional statistical models with an established alpha pipeline. We then discuss the rise of deep learning, which enabled scalable modeling across the entire pipeline from data processing to order execution. Building on this, we highlight the emerging role of LLMs in extending AI beyond prediction, empowering autonomous agents to process unstructured data, generate alphas, and support self-iterative workflows.
Building the Self-Improvement Loop: Error Detection and Correction in Goal-Oriented Semantic Communications
Nov 03, 2024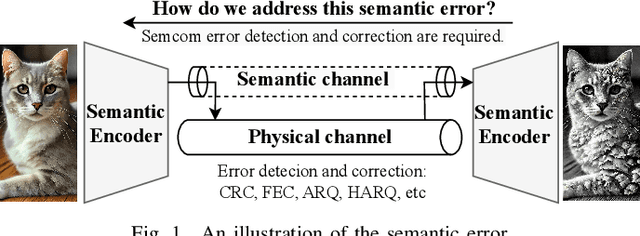
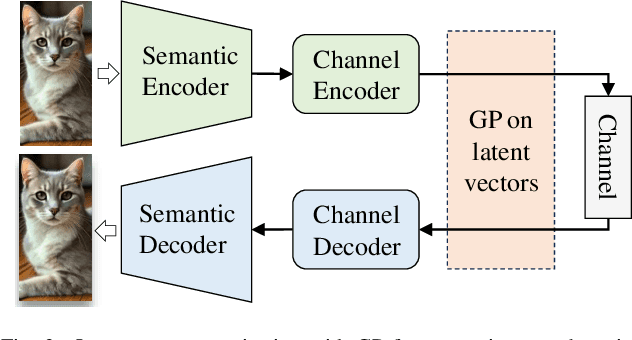
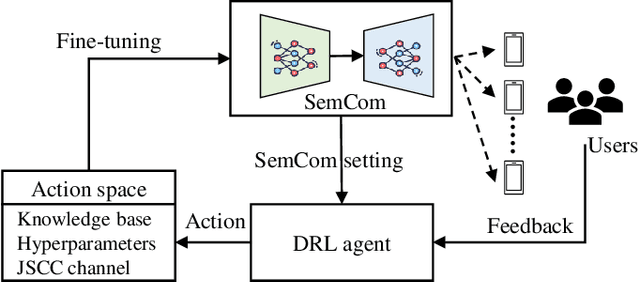
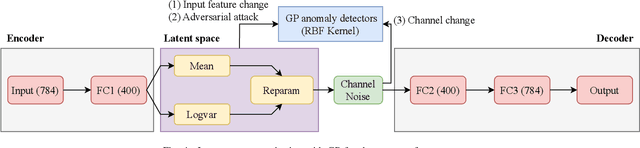
Error detection and correction are essential for ensuring robust and reliable operation in modern communication systems, particularly in complex transmission environments. However, discussions on these topics have largely been overlooked in semantic communication (SemCom), which focuses on transmitting meaning rather than symbols, leading to significant improvements in communication efficiency. Despite these advantages, semantic errors -- stemming from discrepancies between transmitted and received meanings -- present a major challenge to system reliability. This paper addresses this gap by proposing a comprehensive framework for detecting and correcting semantic errors in SemCom systems. We formally define semantic error, detection, and correction mechanisms, and identify key sources of semantic errors. To address these challenges, we develop a Gaussian process (GP)-based method for latent space monitoring to detect errors, alongside a human-in-the-loop reinforcement learning (HITL-RL) approach to optimize semantic model configurations using user feedback. Experimental results validate the effectiveness of the proposed methods in mitigating semantic errors under various conditions, including adversarial attacks, input feature changes, physical channel variations, and user preference shifts. This work lays the foundation for more reliable and adaptive SemCom systems with robust semantic error management techniques.
Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation
Mar 24, 2022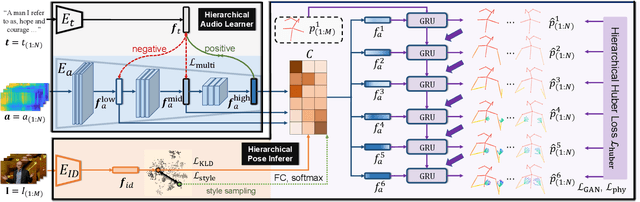
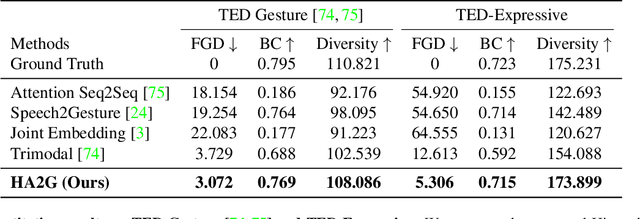
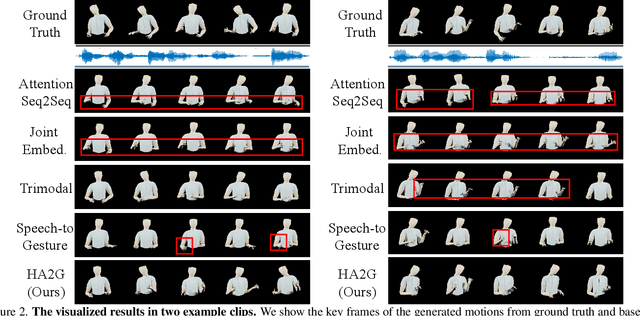

Generating speech-consistent body and gesture movements is a long-standing problem in virtual avatar creation. Previous studies often synthesize pose movement in a holistic manner, where poses of all joints are generated simultaneously. Such a straightforward pipeline fails to generate fine-grained co-speech gestures. One observation is that the hierarchical semantics in speech and the hierarchical structures of human gestures can be naturally described into multiple granularities and associated together. To fully utilize the rich connections between speech audio and human gestures, we propose a novel framework named Hierarchical Audio-to-Gesture (HA2G) for co-speech gesture generation. In HA2G, a Hierarchical Audio Learner extracts audio representations across semantic granularities. A Hierarchical Pose Inferer subsequently renders the entire human pose gradually in a hierarchical manner. To enhance the quality of synthesized gestures, we develop a contrastive learning strategy based on audio-text alignment for better audio representations. Extensive experiments and human evaluation demonstrate that the proposed method renders realistic co-speech gestures and outperforms previous methods in a clear margin. Project page: https://alvinliu0.github.io/projects/HA2G