 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Context-Driven Neural Acoustic Modeling for High-Fidelity RIR Generation
Sep 18, 2025Realistic sound simulation plays a critical role in many applications. A key element in sound simulation is the room impulse response (RIR), which characterizes how sound propagates from a source to a listener within a given space. Recent studies have applied neural implicit methods to learn RIR using context information collected from the environment, such as scene images. However, these approaches do not effectively leverage explicit geometric information from the environment. To further exploit the potential of neural implicit models with direct geometric features, we present Mesh-infused Neural Acoustic Field (MiNAF), which queries a rough room mesh at given locations and extracts distance distributions as an explicit representation of local context. Our approach demonstrates that incorporating explicit local geometric features can better guide the neural network in generating more accurate RIR predictions. Through comparisons with conventional and state-of-the-art baseline methods, we show that MiNAF performs competitively across various evaluation metrics. Furthermore, we verify the robustness of MiNAF in datasets with limited training samples, demonstrating an advance in high-fidelity sound simulation.
Rethinking End-to-End 2D to 3D Scene Segmentation in Gaussian Splatting
Mar 18, 2025Lifting multi-view 2D instance segmentation to a radiance field has proven to be effective to enhance 3D understanding. Existing methods rely on direct matching for end-to-end lifting, yielding inferior results; or employ a two-stage solution constrained by complex pre- or post-processing. In this work, we design a new end-to-end object-aware lifting approach, named Unified-Lift that provides accurate 3D segmentation based on the 3D Gaussian representation. To start, we augment each Gaussian point with an additional Gaussian-level feature learned using a contrastive loss to encode instance information. Importantly, we introduce a learnable object-level codebook to account for individual objects in the scene for an explicit object-level understanding and associate the encoded object-level features with the Gaussian-level point features for segmentation predictions. While promising, achieving effective codebook learning is non-trivial and a naive solution leads to degraded performance. Therefore, we formulate the association learning module and the noisy label filtering module for effective and robust codebook learning. We conduct experiments on three benchmarks: LERF-Masked, Replica, and Messy Rooms datasets. Both qualitative and quantitative results manifest that our Unified-Lift clearly outperforms existing methods in terms of segmentation quality and time efficiency. The code is publicly available at \href{https://github.com/Runsong123/Unified-Lift}{https://github.com/Runsong123/Unified-Lift}.
PCGS: Progressive Compression of 3D Gaussian Splatting
Mar 11, 2025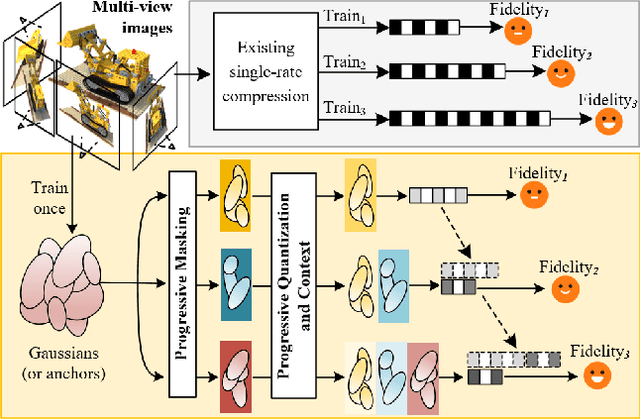
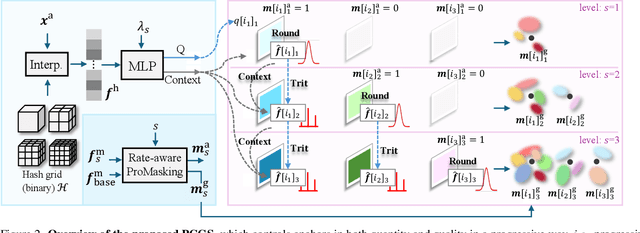
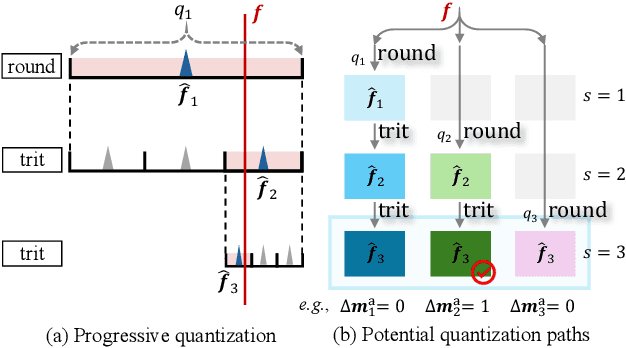
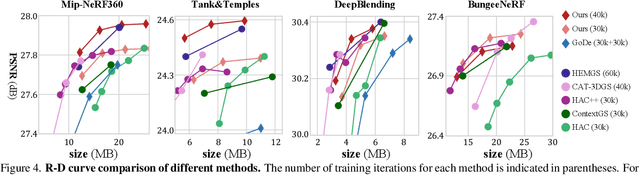
3D Gaussian Splatting (3DGS) achieves impressive rendering fidelity and speed for novel view synthesis. However, its substantial data size poses a significant challenge for practical applications. While many compression techniques have been proposed, they fail to efficiently utilize existing bitstreams in on-demand applications due to their lack of progressivity, leading to a waste of resource. To address this issue, we propose PCGS (Progressive Compression of 3D Gaussian Splatting), which adaptively controls both the quantity and quality of Gaussians (or anchors) to enable effective progressivity for on-demand applications. Specifically, for quantity, we introduce a progressive masking strategy that incrementally incorporates new anchors while refining existing ones to enhance fidelity. For quality, we propose a progressive quantization approach that gradually reduces quantization step sizes to achieve finer modeling of Gaussian attributes. Furthermore, to compact the incremental bitstreams, we leverage existing quantization results to refine probability prediction, improving entropy coding efficiency across progressive levels. Overall, PCGS achieves progressivity while maintaining compression performance comparable to SoTA non-progressive methods. Code available at: github.com/YihangChen-ee/PCGS.
HAC++: Towards 100X Compression of 3D Gaussian Splatting
Jan 21, 2025



3D Gaussian Splatting (3DGS) has emerged as a promising framework for novel view synthesis, boasting rapid rendering speed with high fidelity. However, the substantial Gaussians and their associated attributes necessitate effective compression techniques. Nevertheless, the sparse and unorganized nature of the point cloud of Gaussians (or anchors in our paper) presents challenges for compression. To achieve a compact size, we propose HAC++, which leverages the relationships between unorganized anchors and a structured hash grid, utilizing their mutual information for context modeling. Additionally, HAC++ captures intra-anchor contextual relationships to further enhance compression performance. To facilitate entropy coding, we utilize Gaussian distributions to precisely estimate the probability of each quantized attribute, where an adaptive quantization module is proposed to enable high-precision quantization of these attributes for improved fidelity restoration. Moreover, we incorporate an adaptive masking strategy to eliminate invalid Gaussians and anchors. Overall, HAC++ achieves a remarkable size reduction of over 100X compared to vanilla 3DGS when averaged on all datasets, while simultaneously improving fidelity. It also delivers more than 20X size reduction compared to Scaffold-GS. Our code is available at https://github.com/YihangChen-ee/HAC-plus.
F3D-Gaus: Feed-forward 3D-aware Generation on ImageNet with Cycle-Consistent Gaussian Splatting
Jan 12, 2025



This paper tackles the problem of generalizable 3D-aware generation from monocular datasets, e.g., ImageNet. The key challenge of this task is learning a robust 3D-aware representation without multi-view or dynamic data, while ensuring consistent texture and geometry across different viewpoints. Although some baseline methods are capable of 3D-aware generation, the quality of the generated images still lags behind state-of-the-art 2D generation approaches, which excel in producing high-quality, detailed images. To address this severe limitation, we propose a novel feed-forward pipeline based on pixel-aligned Gaussian Splatting, coined as F3D-Gaus, which can produce more realistic and reliable 3D renderings from monocular inputs. In addition, we introduce a self-supervised cycle-consistent constraint to enforce cross-view consistency in the learned 3D representation. This training strategy naturally allows aggregation of multiple aligned Gaussian primitives and significantly alleviates the interpolation limitations inherent in single-view pixel-aligned Gaussian Splatting. Furthermore, we incorporate video model priors to perform geometry-aware refinement, enhancing the generation of fine details in wide-viewpoint scenarios and improving the model's capability to capture intricate 3D textures. Extensive experiments demonstrate that our approach not only achieves high-quality, multi-view consistent 3D-aware generation from monocular datasets, but also significantly improves training and inference efficiency.
PanSplat: 4K Panorama Synthesis with Feed-Forward Gaussian Splatting
Dec 16, 2024With the advent of portable 360{\deg} cameras, panorama has gained significant attention in applications like virtual reality (VR), virtual tours, robotics, and autonomous driving. As a result, wide-baseline panorama view synthesis has emerged as a vital task, where high resolution, fast inference, and memory efficiency are essential. Nevertheless, existing methods are typically constrained to lower resolutions (512 $\times$ 1024) due to demanding memory and computational requirements. In this paper, we present PanSplat, a generalizable, feed-forward approach that efficiently supports resolution up to 4K (2048 $\times$ 4096). Our approach features a tailored spherical 3D Gaussian pyramid with a Fibonacci lattice arrangement, enhancing image quality while reducing information redundancy. To accommodate the demands of high resolution, we propose a pipeline that integrates a hierarchical spherical cost volume and Gaussian heads with local operations, enabling two-step deferred backpropagation for memory-efficient training on a single A100 GPU. Experiments demonstrate that PanSplat achieves state-of-the-art results with superior efficiency and image quality across both synthetic and real-world datasets. Code will be available at \url{https://github.com/chengzhag/PanSplat}.
Normal-GS: 3D Gaussian Splatting with Normal-Involved Rendering
Oct 27, 2024



Rendering and reconstruction are long-standing topics in computer vision and graphics. Achieving both high rendering quality and accurate geometry is a challenge. Recent advancements in 3D Gaussian Splatting (3DGS) have enabled high-fidelity novel view synthesis at real-time speeds. However, the noisy and discrete nature of 3D Gaussian primitives hinders accurate surface estimation. Previous attempts to regularize 3D Gaussian normals often degrade rendering quality due to the fundamental disconnect between normal vectors and the rendering pipeline in 3DGS-based methods. Therefore, we introduce Normal-GS, a novel approach that integrates normal vectors into the 3DGS rendering pipeline. The core idea is to model the interaction between normals and incident lighting using the physically-based rendering equation. Our approach re-parameterizes surface colors as the product of normals and a designed Integrated Directional Illumination Vector (IDIV). To optimize memory usage and simplify optimization, we employ an anchor-based 3DGS to implicitly encode locally-shared IDIVs. Additionally, Normal-GS leverages optimized normals and Integrated Directional Encoding (IDE) to accurately model specular effects, enhancing both rendering quality and surface normal precision. Extensive experiments demonstrate that Normal-GS achieves near state-of-the-art visual quality while obtaining accurate surface normals and preserving real-time rendering performance.
PCF-Lift: Panoptic Lifting by Probabilistic Contrastive Fusion
Oct 14, 2024Panoptic lifting is an effective technique to address the 3D panoptic segmentation task by unprojecting 2D panoptic segmentations from multi-views to 3D scene. However, the quality of its results largely depends on the 2D segmentations, which could be noisy and error-prone, so its performance often drops significantly for complex scenes. In this work, we design a new pipeline coined PCF-Lift based on our Probabilis-tic Contrastive Fusion (PCF) to learn and embed probabilistic features throughout our pipeline to actively consider inaccurate segmentations and inconsistent instance IDs. Technical-wise, we first model the probabilistic feature embeddings through multivariate Gaussian distributions. To fuse the probabilistic features, we incorporate the probability product kernel into the contrastive loss formulation and design a cross-view constraint to enhance the feature consistency across different views. For the inference, we introduce a new probabilistic clustering method to effectively associate prototype features with the underlying 3D object instances for the generation of consistent panoptic segmentation results. Further, we provide a theoretical analysis to justify the superiority of the proposed probabilistic solution. By conducting extensive experiments, our PCF-lift not only significantly outperforms the state-of-the-art methods on widely used benchmarks including the ScanNet dataset and the challenging Messy Room dataset (4.4% improvement of scene-level PQ), but also demonstrates strong robustness when incorporating various 2D segmentation models or different levels of hand-crafted noise.
Fast Feedforward 3D Gaussian Splatting Compression
Oct 10, 2024



With 3D Gaussian Splatting (3DGS) advancing real-time and high-fidelity rendering for novel view synthesis, storage requirements pose challenges for their widespread adoption. Although various compression techniques have been proposed, previous art suffers from a common limitation: for any existing 3DGS, per-scene optimization is needed to achieve compression, making the compression sluggish and slow. To address this issue, we introduce Fast Compression of 3D Gaussian Splatting (FCGS), an optimization-free model that can compress 3DGS representations rapidly in a single feed-forward pass, which significantly reduces compression time from minutes to seconds. To enhance compression efficiency, we propose a multi-path entropy module that assigns Gaussian attributes to different entropy constraint paths for balance between size and fidelity. We also carefully design both inter- and intra-Gaussian context models to remove redundancies among the unstructured Gaussian blobs. Overall, FCGS achieves a compression ratio of over 20X while maintaining fidelity, surpassing most per-scene SOTA optimization-based methods. Our code is available at: https://github.com/YihangChen-ee/FCGS.
TFS-NeRF: Template-Free NeRF for Semantic 3D Reconstruction of Dynamic Scene
Sep 26, 2024



Despite advancements in Neural Implicit models for 3D surface reconstruction, handling dynamic environments with arbitrary rigid, non-rigid, or deformable entities remains challenging. Many template-based methods are entity-specific, focusing on humans, while generic reconstruction methods adaptable to such dynamic scenes often require additional inputs like depth or optical flow or rely on pre-trained image features for reasonable outcomes. These methods typically use latent codes to capture frame-by-frame deformations. In contrast, some template-free methods bypass these requirements and adopt traditional LBS (Linear Blend Skinning) weights for a detailed representation of deformable object motions, although they involve complex optimizations leading to lengthy training times. To this end, as a remedy, this paper introduces TFS-NeRF, a template-free 3D semantic NeRF for dynamic scenes captured from sparse or single-view RGB videos, featuring interactions among various entities and more time-efficient than other LBS-based approaches. Our framework uses an Invertible Neural Network (INN) for LBS prediction, simplifying the training process. By disentangling the motions of multiple entities and optimizing per-entity skinning weights, our method efficiently generates accurate, semantically separable geometries. Extensive experiments demonstrate that our approach produces high-quality reconstructions of both deformable and non-deformable objects in complex interactions, with improved training efficiency compared to existing methods.