 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJRDB-Pose3D: A Multi-person 3D Human Pose and Shape Estimation Dataset for Robotics
Feb 03, 2026Real-world scenes are inherently crowded. Hence, estimating 3D poses of all nearby humans, tracking their movements over time, and understanding their activities within social and environmental contexts are essential for many applications, such as autonomous driving, robot perception, robot navigation, and human-robot interaction. However, most existing 3D human pose estimation datasets primarily focus on single-person scenes or are collected in controlled laboratory environments, which restricts their relevance to real-world applications. To bridge this gap, we introduce JRDB-Pose3D, which captures multi-human indoor and outdoor environments from a mobile robotic platform. JRDB-Pose3D provides rich 3D human pose annotations for such complex and dynamic scenes, including SMPL-based pose annotations with consistent body-shape parameters and track IDs for each individual over time. JRDB-Pose3D contains, on average, 5-10 human poses per frame, with some scenes featuring up to 35 individuals simultaneously. The proposed dataset presents unique challenges, including frequent occlusions, truncated bodies, and out-of-frame body parts, which closely reflect real-world environments. Moreover, JRDB-Pose3D inherits all available annotations from the JRDB dataset, such as 2D pose, information about social grouping, activities, and interactions, full-scene semantic masks with consistent human- and object-level tracking, and detailed annotations for each individual, such as age, gender, and race, making it a holistic dataset for a wide range of downstream perception and human-centric understanding tasks.
TFS-NeRF: Template-Free NeRF for Semantic 3D Reconstruction of Dynamic Scene
Sep 26, 2024



Despite advancements in Neural Implicit models for 3D surface reconstruction, handling dynamic environments with arbitrary rigid, non-rigid, or deformable entities remains challenging. Many template-based methods are entity-specific, focusing on humans, while generic reconstruction methods adaptable to such dynamic scenes often require additional inputs like depth or optical flow or rely on pre-trained image features for reasonable outcomes. These methods typically use latent codes to capture frame-by-frame deformations. In contrast, some template-free methods bypass these requirements and adopt traditional LBS (Linear Blend Skinning) weights for a detailed representation of deformable object motions, although they involve complex optimizations leading to lengthy training times. To this end, as a remedy, this paper introduces TFS-NeRF, a template-free 3D semantic NeRF for dynamic scenes captured from sparse or single-view RGB videos, featuring interactions among various entities and more time-efficient than other LBS-based approaches. Our framework uses an Invertible Neural Network (INN) for LBS prediction, simplifying the training process. By disentangling the motions of multiple entities and optimizing per-entity skinning weights, our method efficiently generates accurate, semantically separable geometries. Extensive experiments demonstrate that our approach produces high-quality reconstructions of both deformable and non-deformable objects in complex interactions, with improved training efficiency compared to existing methods.
A Fusion of Variational Distribution Priors and Saliency Map Replay for Continual 3D Reconstruction
Aug 17, 2023



Single-image 3D reconstruction is a research challenge focused on predicting 3D object shapes from single-view images. This task requires significant data acquisition to predict both visible and occluded portions of the shape. Furthermore, learning-based methods face the difficulty of creating a comprehensive training dataset for all possible classes. To this end, we propose a continual learning-based 3D reconstruction method where our goal is to design a model using Variational Priors that can still reconstruct the previously seen classes reasonably even after training on new classes. Variational Priors represent abstract shapes and combat forgetting, whereas saliency maps preserve object attributes with less memory usage. This is vital due to resource constraints in storing extensive training data. Additionally, we introduce saliency map-based experience replay to capture global and distinct object features. Thorough experiments show competitive results compared to established methods, both quantitatively and qualitatively.
Physically Plausible 3D Human-Scene Reconstruction from Monocular RGB Image using an Adversarial Learning Approach
Jul 27, 2023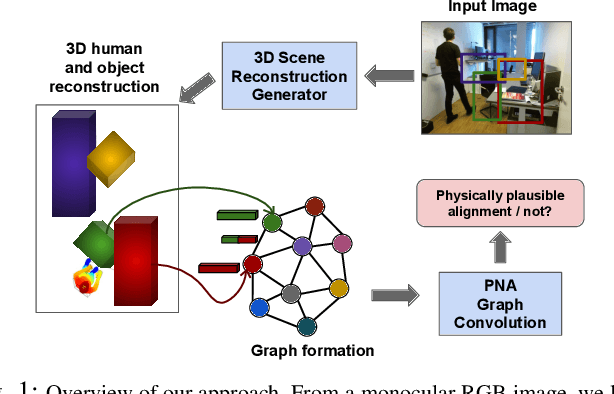
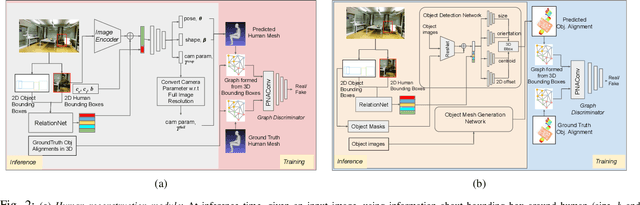

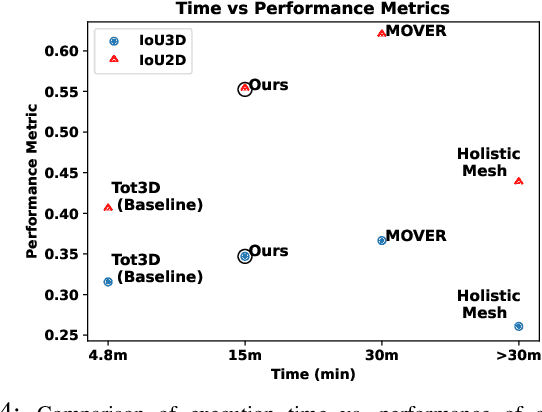
Holistic 3D human-scene reconstruction is a crucial and emerging research area in robot perception. A key challenge in holistic 3D human-scene reconstruction is to generate a physically plausible 3D scene from a single monocular RGB image. The existing research mainly proposes optimization-based approaches for reconstructing the scene from a sequence of RGB frames with explicitly defined physical laws and constraints between different scene elements (humans and objects). However, it is hard to explicitly define and model every physical law in every scenario. This paper proposes using an implicit feature representation of the scene elements to distinguish a physically plausible alignment of humans and objects from an implausible one. We propose using a graph-based holistic representation with an encoded physical representation of the scene to analyze the human-object and object-object interactions within the scene. Using this graphical representation, we adversarially train our model to learn the feasible alignments of the scene elements from the training data itself without explicitly defining the laws and constraints between them. Unlike the existing inference-time optimization-based approaches, we use this adversarially trained model to produce a per-frame 3D reconstruction of the scene that abides by the physical laws and constraints. Our learning-based method achieves comparable 3D reconstruction quality to existing optimization-based holistic human-scene reconstruction methods and does not need inference time optimization. This makes it better suited when compared to existing methods, for potential use in robotic applications, such as robot navigation, etc.
Emotion-Controllable Generalized Talking Face Generation
May 02, 2022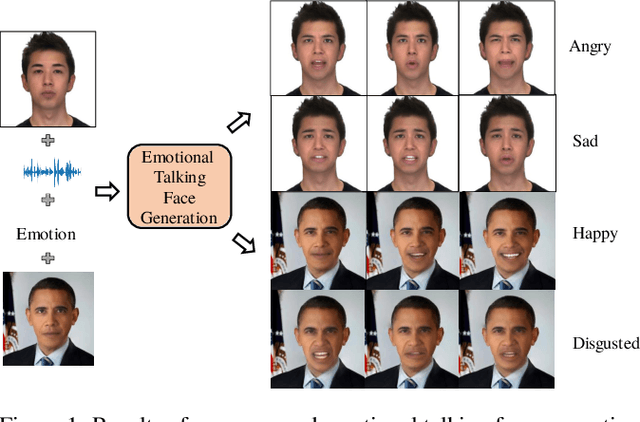



Despite the significant progress in recent years, very few of the AI-based talking face generation methods attempt to render natural emotions. Moreover, the scope of the methods is majorly limited to the characteristics of the training dataset, hence they fail to generalize to arbitrary unseen faces. In this paper, we propose a one-shot facial geometry-aware emotional talking face generation method that can generalize to arbitrary faces. We propose a graph convolutional neural network that uses speech content feature, along with an independent emotion input to generate emotion and speech-induced motion on facial geometry-aware landmark representation. This representation is further used in our optical flow-guided texture generation network for producing the texture. We propose a two-branch texture generation network, with motion and texture branches designed to consider the motion and texture content independently. Compared to the previous emotion talking face methods, our method can adapt to arbitrary faces captured in-the-wild by fine-tuning with only a single image of the target identity in neutral emotion.
Identity-Preserving Realistic Talking Face Generation
May 25, 2020

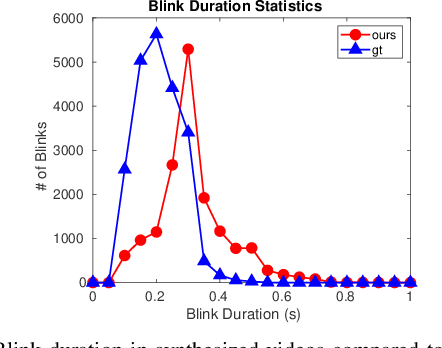
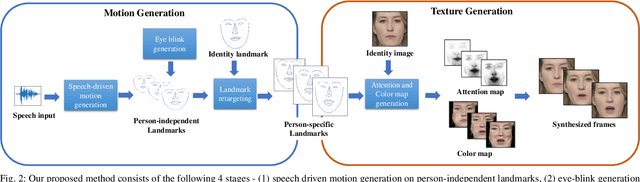
Speech-driven facial animation is useful for a variety of applications such as telepresence, chatbots, etc. The necessary attributes of having a realistic face animation are 1) audio-visual synchronization (2) identity preservation of the target individual (3) plausible mouth movements (4) presence of natural eye blinks. The existing methods mostly address the audio-visual lip synchronization, and few recent works have addressed the synthesis of natural eye blinks for overall video realism. In this paper, we propose a method for identity-preserving realistic facial animation from speech. We first generate person-independent facial landmarks from audio using DeepSpeech features for invariance to different voices, accents, etc. To add realism, we impose eye blinks on facial landmarks using unsupervised learning and retargets the person-independent landmarks to person-specific landmarks to preserve the identity-related facial structure which helps in the generation of plausible mouth shapes of the target identity. Finally, we use LSGAN to generate the facial texture from person-specific facial landmarks, using an attention mechanism that helps to preserve identity-related texture. An extensive comparison of our proposed method with the current state-of-the-art methods demonstrates a significant improvement in terms of lip synchronization accuracy, image reconstruction quality, sharpness, and identity-preservation. A user study also reveals improved realism of our animation results over the state-of-the-art methods. To the best of our knowledge, this is the first work in speech-driven 2D facial animation that simultaneously addresses all the above-mentioned attributes of a realistic speech-driven face animation.
Lifting 2d Human Pose to 3d : A Weakly Supervised Approach
May 03, 2019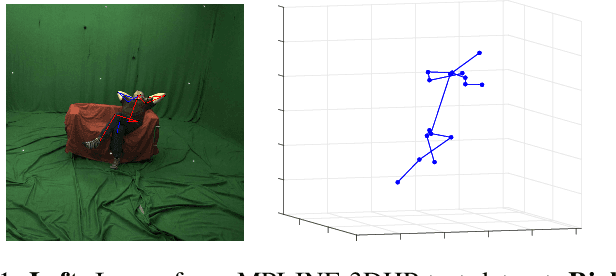
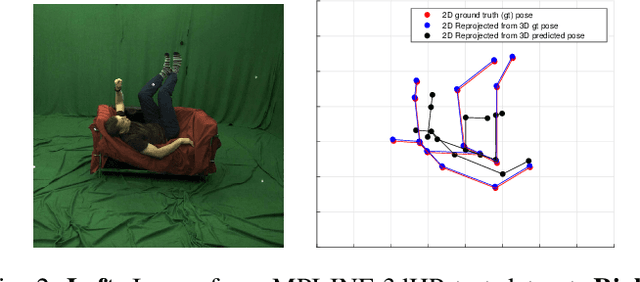
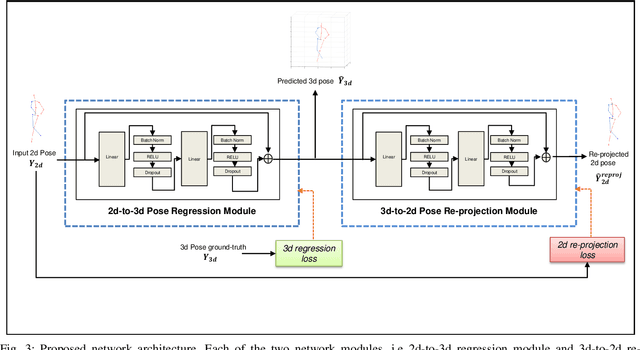
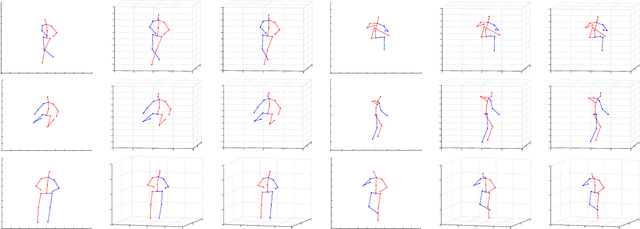
Estimating 3d human pose from monocular images is a challenging problem due to the variety and complexity of human poses and the inherent ambiguity in recovering depth from the single view. Recent deep learning based methods show promising results by using supervised learning on 3d pose annotated datasets. However, the lack of large-scale 3d annotated training data captured under in-the-wild settings makes the 3d pose estimation difficult for in-the-wild poses. Few approaches have utilized training images from both 3d and 2d pose datasets in a weakly-supervised manner for learning 3d poses in unconstrained settings. In this paper, we propose a method which can effectively predict 3d human pose from 2d pose using a deep neural network trained in a weakly-supervised manner on a combination of ground-truth 3d pose and ground-truth 2d pose. Our method uses re-projection error minimization as a constraint to predict the 3d locations of body joints, and this is crucial for training on data where the 3d ground-truth is not present. Since minimizing re-projection error alone may not guarantee an accurate 3d pose, we also use additional geometric constraints on skeleton pose to regularize the pose in 3d. We demonstrate the superior generalization ability of our method by cross-dataset validation on a challenging 3d benchmark dataset MPI-INF-3DHP containing in the wild 3d poses.