 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Controllable Generalized Talking Face Generation
May 02, 2022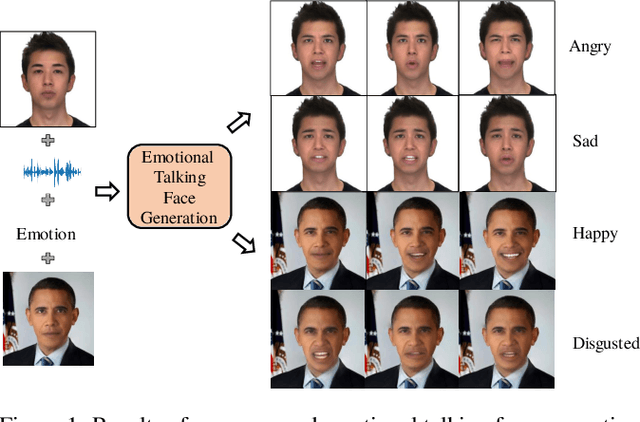



Despite the significant progress in recent years, very few of the AI-based talking face generation methods attempt to render natural emotions. Moreover, the scope of the methods is majorly limited to the characteristics of the training dataset, hence they fail to generalize to arbitrary unseen faces. In this paper, we propose a one-shot facial geometry-aware emotional talking face generation method that can generalize to arbitrary faces. We propose a graph convolutional neural network that uses speech content feature, along with an independent emotion input to generate emotion and speech-induced motion on facial geometry-aware landmark representation. This representation is further used in our optical flow-guided texture generation network for producing the texture. We propose a two-branch texture generation network, with motion and texture branches designed to consider the motion and texture content independently. Compared to the previous emotion talking face methods, our method can adapt to arbitrary faces captured in-the-wild by fine-tuning with only a single image of the target identity in neutral emotion.
Identity-Preserving Realistic Talking Face Generation
May 25, 2020

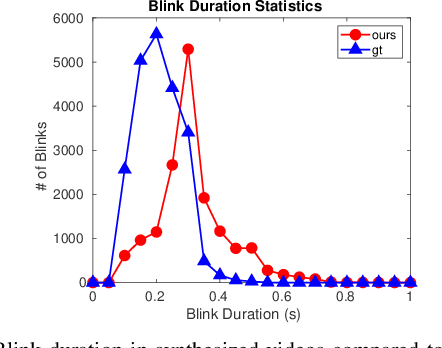
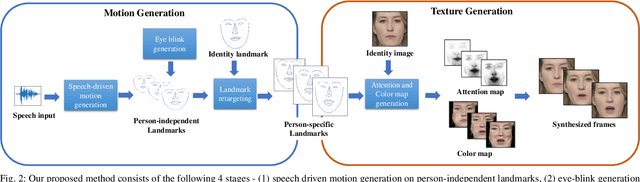
Speech-driven facial animation is useful for a variety of applications such as telepresence, chatbots, etc. The necessary attributes of having a realistic face animation are 1) audio-visual synchronization (2) identity preservation of the target individual (3) plausible mouth movements (4) presence of natural eye blinks. The existing methods mostly address the audio-visual lip synchronization, and few recent works have addressed the synthesis of natural eye blinks for overall video realism. In this paper, we propose a method for identity-preserving realistic facial animation from speech. We first generate person-independent facial landmarks from audio using DeepSpeech features for invariance to different voices, accents, etc. To add realism, we impose eye blinks on facial landmarks using unsupervised learning and retargets the person-independent landmarks to person-specific landmarks to preserve the identity-related facial structure which helps in the generation of plausible mouth shapes of the target identity. Finally, we use LSGAN to generate the facial texture from person-specific facial landmarks, using an attention mechanism that helps to preserve identity-related texture. An extensive comparison of our proposed method with the current state-of-the-art methods demonstrates a significant improvement in terms of lip synchronization accuracy, image reconstruction quality, sharpness, and identity-preservation. A user study also reveals improved realism of our animation results over the state-of-the-art methods. To the best of our knowledge, this is the first work in speech-driven 2D facial animation that simultaneously addresses all the above-mentioned attributes of a realistic speech-driven face animation.
Lifting 2d Human Pose to 3d : A Weakly Supervised Approach
May 03, 2019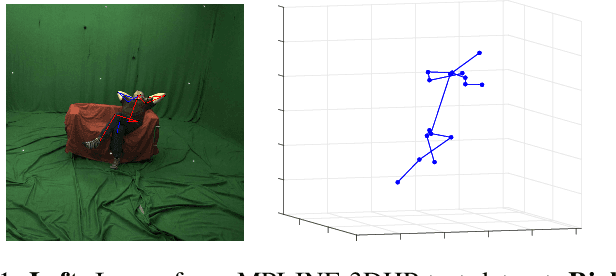
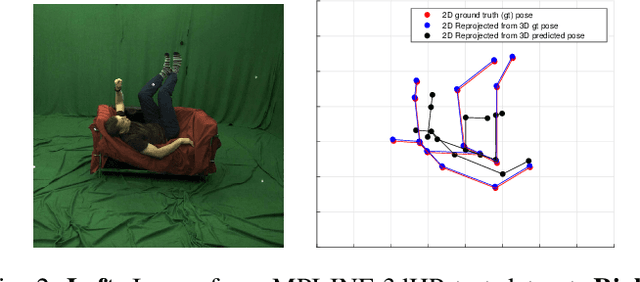
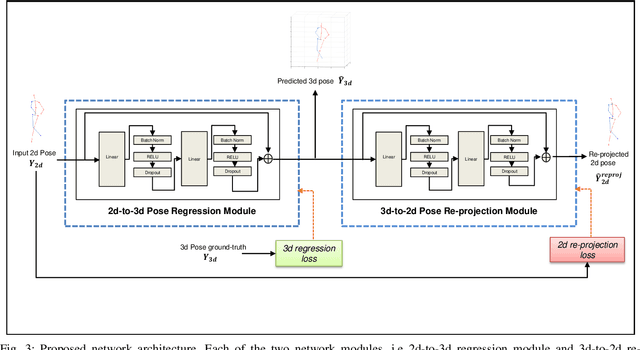
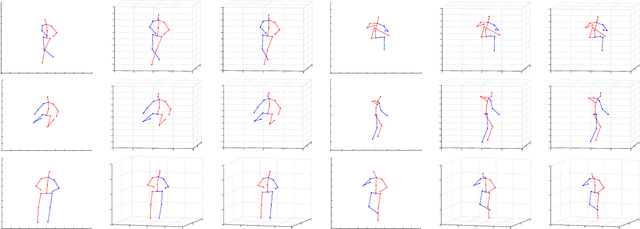
Estimating 3d human pose from monocular images is a challenging problem due to the variety and complexity of human poses and the inherent ambiguity in recovering depth from the single view. Recent deep learning based methods show promising results by using supervised learning on 3d pose annotated datasets. However, the lack of large-scale 3d annotated training data captured under in-the-wild settings makes the 3d pose estimation difficult for in-the-wild poses. Few approaches have utilized training images from both 3d and 2d pose datasets in a weakly-supervised manner for learning 3d poses in unconstrained settings. In this paper, we propose a method which can effectively predict 3d human pose from 2d pose using a deep neural network trained in a weakly-supervised manner on a combination of ground-truth 3d pose and ground-truth 2d pose. Our method uses re-projection error minimization as a constraint to predict the 3d locations of body joints, and this is crucial for training on data where the 3d ground-truth is not present. Since minimizing re-projection error alone may not guarantee an accurate 3d pose, we also use additional geometric constraints on skeleton pose to regularize the pose in 3d. We demonstrate the superior generalization ability of our method by cross-dataset validation on a challenging 3d benchmark dataset MPI-INF-3DHP containing in the wild 3d poses.