 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifting 2d Human Pose to 3d : A Weakly Supervised Approach
Paper and Code
May 03, 2019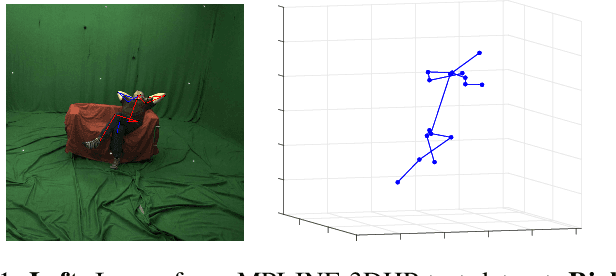
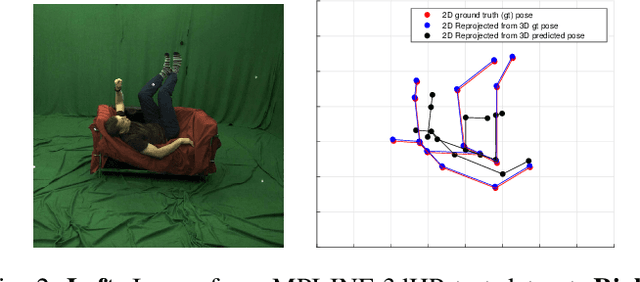
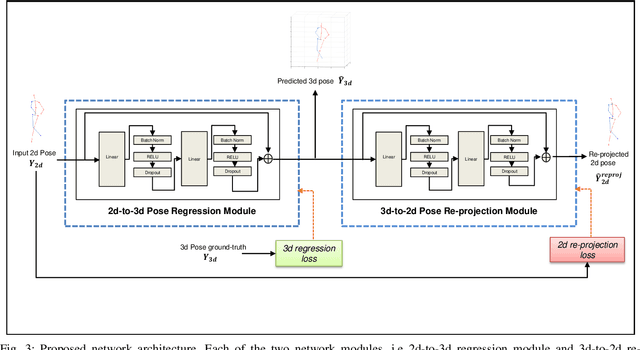
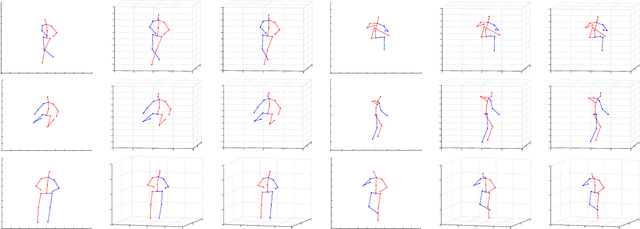
Estimating 3d human pose from monocular images is a challenging problem due to the variety and complexity of human poses and the inherent ambiguity in recovering depth from the single view. Recent deep learning based methods show promising results by using supervised learning on 3d pose annotated datasets. However, the lack of large-scale 3d annotated training data captured under in-the-wild settings makes the 3d pose estimation difficult for in-the-wild poses. Few approaches have utilized training images from both 3d and 2d pose datasets in a weakly-supervised manner for learning 3d poses in unconstrained settings. In this paper, we propose a method which can effectively predict 3d human pose from 2d pose using a deep neural network trained in a weakly-supervised manner on a combination of ground-truth 3d pose and ground-truth 2d pose. Our method uses re-projection error minimization as a constraint to predict the 3d locations of body joints, and this is crucial for training on data where the 3d ground-truth is not present. Since minimizing re-projection error alone may not guarantee an accurate 3d pose, we also use additional geometric constraints on skeleton pose to regularize the pose in 3d. We demonstrate the superior generalization ability of our method by cross-dataset validation on a challenging 3d benchmark dataset MPI-INF-3DHP containing in the wild 3d poses.