 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically Plausible 3D Human-Scene Reconstruction from Monocular RGB Image using an Adversarial Learning Approach
Paper and Code
Jul 27, 2023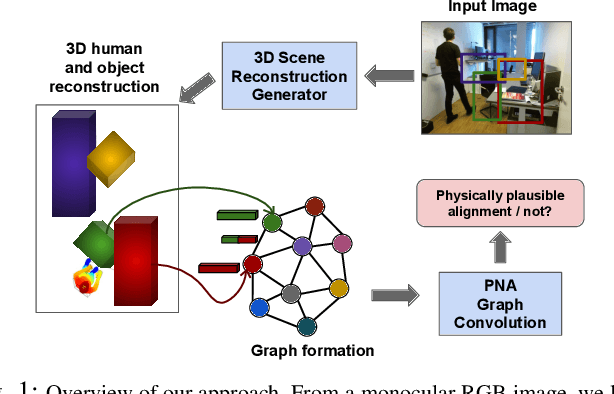
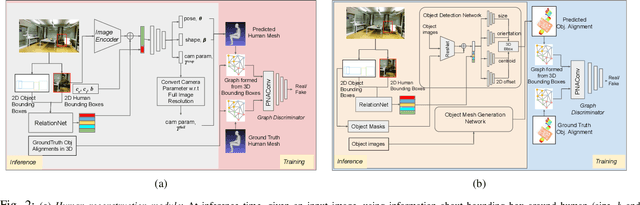

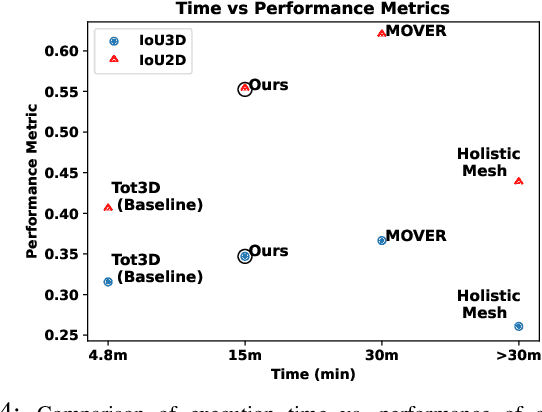
Holistic 3D human-scene reconstruction is a crucial and emerging research area in robot perception. A key challenge in holistic 3D human-scene reconstruction is to generate a physically plausible 3D scene from a single monocular RGB image. The existing research mainly proposes optimization-based approaches for reconstructing the scene from a sequence of RGB frames with explicitly defined physical laws and constraints between different scene elements (humans and objects). However, it is hard to explicitly define and model every physical law in every scenario. This paper proposes using an implicit feature representation of the scene elements to distinguish a physically plausible alignment of humans and objects from an implausible one. We propose using a graph-based holistic representation with an encoded physical representation of the scene to analyze the human-object and object-object interactions within the scene. Using this graphical representation, we adversarially train our model to learn the feasible alignments of the scene elements from the training data itself without explicitly defining the laws and constraints between them. Unlike the existing inference-time optimization-based approaches, we use this adversarially trained model to produce a per-frame 3D reconstruction of the scene that abides by the physical laws and constraints. Our learning-based method achieves comparable 3D reconstruction quality to existing optimization-based holistic human-scene reconstruction methods and does not need inference time optimization. This makes it better suited when compared to existing methods, for potential use in robotic applications, such as robot navigation, etc.