 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevised Regularization for Efficient Continual Learning through Correlation-Based Parameter Update in Bayesian Neural Networks
Nov 21, 2024



We propose a Bayesian neural network-based continual learning algorithm using Variational Inference, aiming to overcome several drawbacks of existing methods. Specifically, in continual learning scenarios, storing network parameters at each step to retain knowledge poses challenges. This is compounded by the crucial need to mitigate catastrophic forgetting, particularly given the limited access to past datasets, which complicates maintaining correspondence between network parameters and datasets across all sessions. Current methods using Variational Inference with KL divergence risk catastrophic forgetting during uncertain node updates and coupled disruptions in certain nodes. To address these challenges, we propose the following strategies. To reduce the storage of the dense layer parameters, we propose a parameter distribution learning method that significantly reduces the storage requirements. In the continual learning framework employing variational inference, our study introduces a regularization term that specifically targets the dynamics and population of the mean and variance of the parameters. This term aims to retain the benefits of KL divergence while addressing related challenges. To ensure proper correspondence between network parameters and the data, our method introduces an importance-weighted Evidence Lower Bound term to capture data and parameter correlations. This enables storage of common and distinctive parameter hyperspace bases. The proposed method partitions the parameter space into common and distinctive subspaces, with conditions for effective backward and forward knowledge transfer, elucidating the network-parameter dataset correspondence. The experimental results demonstrate the effectiveness of our method across diverse datasets and various combinations of sequential datasets, yielding superior performance compared to existing approaches.
Scalable, Tokenization-Free Diffusion Model Architectures with Efficient Initial Convolution and Fixed-Size Reusable Structures for On-Device Image Generation
Nov 09, 2024



Vision Transformers and U-Net architectures have been widely adopted in the implementation of Diffusion Models. However, each architecture presents specific challenges while realizing them on-device. Vision Transformers require positional embedding to maintain correspondence between the tokens processed by the transformer, although they offer the advantage of using fixed-size, reusable repetitive blocks following tokenization. The U-Net architecture lacks these attributes, as it utilizes variable-sized intermediate blocks for down-convolution and up-convolution in the noise estimation backbone for the diffusion process. To address these issues, we propose an architecture that utilizes a fixed-size, reusable transformer block as a core structure, making it more suitable for hardware implementation. Our architecture is characterized by low complexity, token-free design, absence of positional embeddings, uniformity, and scalability, making it highly suitable for deployment on mobile and resource-constrained devices. The proposed model exhibit competitive and consistent performance across both unconditional and conditional image generation tasks. The model achieved a state-of-the-art FID score of 1.6 on unconditional image generation with the CelebA.
A Fusion of Variational Distribution Priors and Saliency Map Replay for Continual 3D Reconstruction
Aug 17, 2023



Single-image 3D reconstruction is a research challenge focused on predicting 3D object shapes from single-view images. This task requires significant data acquisition to predict both visible and occluded portions of the shape. Furthermore, learning-based methods face the difficulty of creating a comprehensive training dataset for all possible classes. To this end, we propose a continual learning-based 3D reconstruction method where our goal is to design a model using Variational Priors that can still reconstruct the previously seen classes reasonably even after training on new classes. Variational Priors represent abstract shapes and combat forgetting, whereas saliency maps preserve object attributes with less memory usage. This is vital due to resource constraints in storing extensive training data. Additionally, we introduce saliency map-based experience replay to capture global and distinct object features. Thorough experiments show competitive results compared to established methods, both quantitatively and qualitatively.
Prototypical quadruplet for few-shot class incremental learning
Nov 09, 2022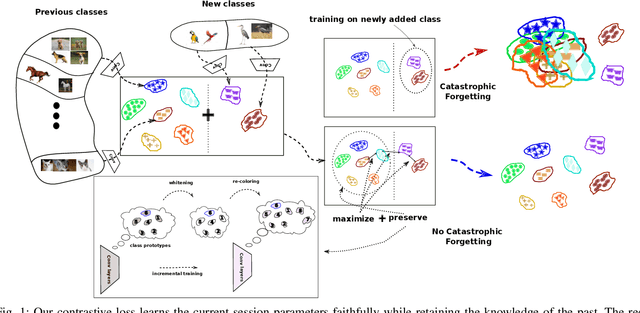
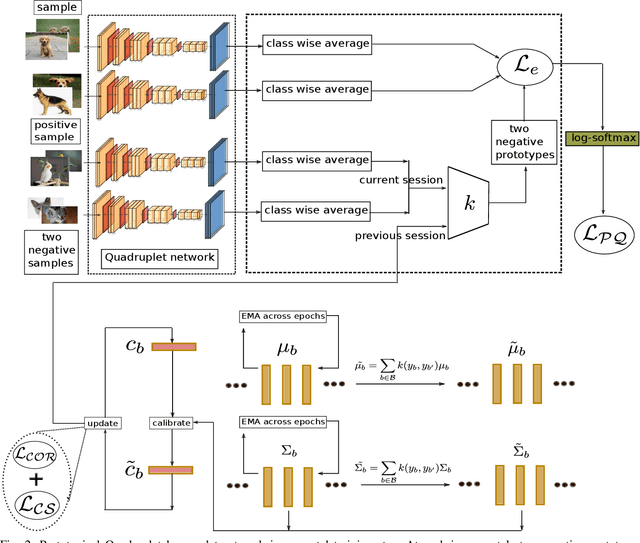
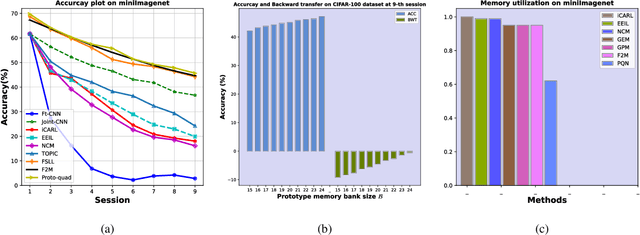
Many modern computer vision algorithms suffer from two major bottlenecks: scarcity of data and learning new tasks incrementally. While training the model with new batches of data the model looses it's ability to classify the previous data judiciously which is termed as catastrophic forgetting. Conventional methods have tried to mitigate catastrophic forgetting of the previously learned data while the training at the current session has been compromised. The state-of-the-art generative replay based approaches use complicated structures such as generative adversarial network (GAN) to deal with catastrophic forgetting. Additionally, training a GAN with few samples may lead to instability. In this work, we present a novel method to deal with these two major hurdles. Our method identifies a better embedding space with an improved contrasting loss to make classification more robust. Moreover, our approach is able to retain previously acquired knowledge in the embedding space even when trained with new classes. We update previous session class prototypes while training in such a way that it is able to represent the true class mean. This is of prime importance as our classification rule is based on the nearest class mean classification strategy. We have demonstrated our results by showing that the embedding space remains intact after training the model with new classes. We showed that our method preformed better than the existing state-of-the-art algorithms in terms of accuracy across different sessions.