 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable, Tokenization-Free Diffusion Model Architectures with Efficient Initial Convolution and Fixed-Size Reusable Structures for On-Device Image Generation
Nov 09, 2024



Vision Transformers and U-Net architectures have been widely adopted in the implementation of Diffusion Models. However, each architecture presents specific challenges while realizing them on-device. Vision Transformers require positional embedding to maintain correspondence between the tokens processed by the transformer, although they offer the advantage of using fixed-size, reusable repetitive blocks following tokenization. The U-Net architecture lacks these attributes, as it utilizes variable-sized intermediate blocks for down-convolution and up-convolution in the noise estimation backbone for the diffusion process. To address these issues, we propose an architecture that utilizes a fixed-size, reusable transformer block as a core structure, making it more suitable for hardware implementation. Our architecture is characterized by low complexity, token-free design, absence of positional embeddings, uniformity, and scalability, making it highly suitable for deployment on mobile and resource-constrained devices. The proposed model exhibit competitive and consistent performance across both unconditional and conditional image generation tasks. The model achieved a state-of-the-art FID score of 1.6 on unconditional image generation with the CelebA.
Deep No-reference Tone Mapped Image Quality Assessment
Feb 08, 2020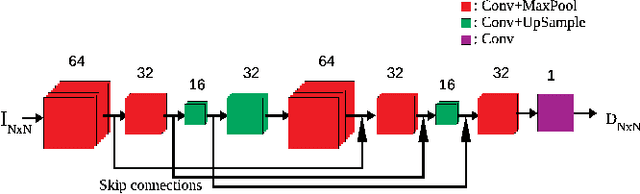
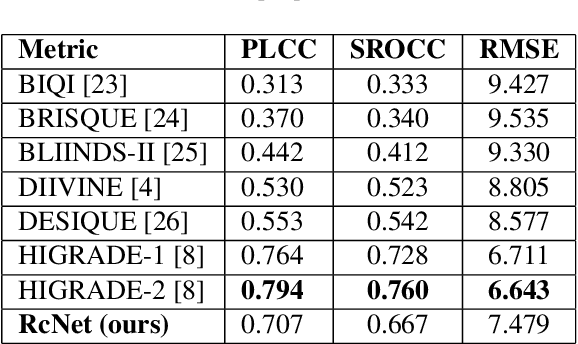

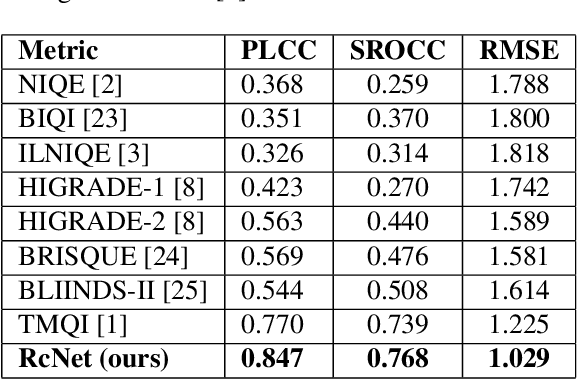
The process of rendering high dynamic range (HDR) images to be viewed on conventional displays is called tone mapping. However, tone mapping introduces distortions in the final image which may lead to visual displeasure. To quantify these distortions, we introduce a novel no-reference quality assessment technique for these tone mapped images. This technique is composed of two stages. In the first stage, we employ a convolutional neural network (CNN) to generate quality aware maps (also known as distortion maps) from tone mapped images by training it with the ground truth distortion maps. In the second stage, we model the normalized image and distortion maps using an Asymmetric Generalized Gaussian Distribution (AGGD). The parameters of the AGGD model are then used to estimate the quality score using support vector regression (SVR). We show that the proposed technique delivers competitive performance relative to the state-of-the-art techniques. The novelty of this work is its ability to visualize various distortions as quality maps (distortion maps), especially in the no-reference setting, and to use these maps as features to estimate the quality score of tone mapped images.