 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Compositionality in Vision Transformers using Wavelet Representations
Dec 30, 2025While insights into the workings of the transformer model have largely emerged by analysing their behaviour on language tasks, this work investigates the representations learnt by the Vision Transformer (ViT) encoder through the lens of compositionality. We introduce a framework, analogous to prior work on measuring compositionality in representation learning, to test for compositionality in the ViT encoder. Crucial to drawing this analogy is the Discrete Wavelet Transform (DWT), which is a simple yet effective tool for obtaining input-dependent primitives in the vision setting. By examining the ability of composed representations to reproduce original image representations, we empirically test the extent to which compositionality is respected in the representation space. Our findings show that primitives from a one-level DWT decomposition produce encoder representations that approximately compose in latent space, offering a new perspective on how ViTs structure information.
Inpainting the Gaps: A Novel Framework for Evaluating Explanation Methods in Vision Transformers
Jun 17, 2024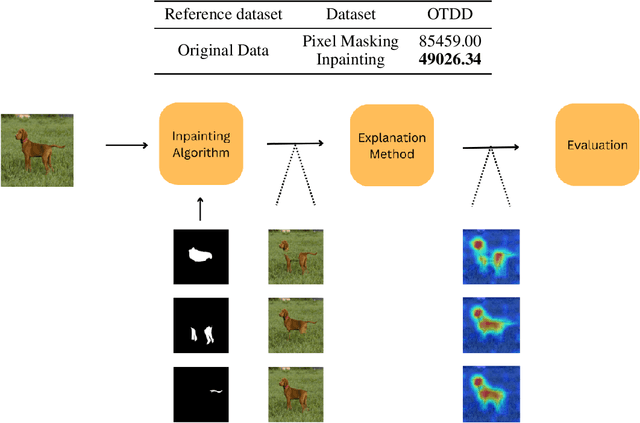
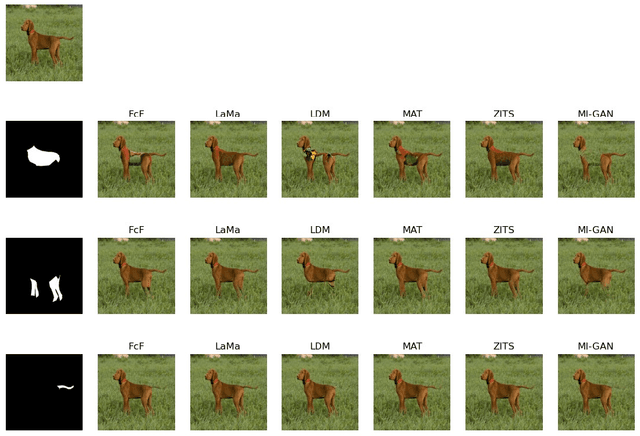
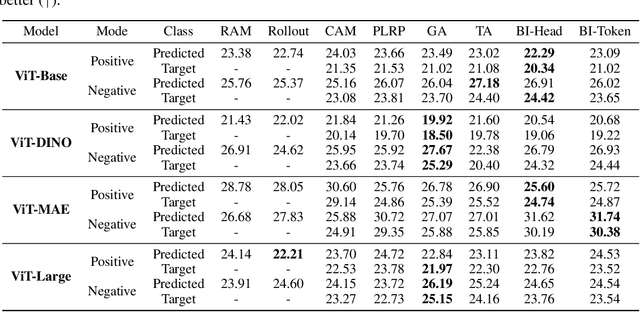

The perturbation test remains the go-to evaluation approach for explanation methods in computer vision. This evaluation method has a major drawback of test-time distribution shift due to pixel-masking that is not present in the training set. To overcome this drawback, we propose a novel evaluation framework called \textbf{Inpainting the Gaps (InG)}. Specifically, we propose inpainting parts that constitute partial or complete objects in an image. In this way, one can perform meaningful image perturbations with lower test-time distribution shifts, thereby improving the efficacy of the perturbation test. InG is applied to the PartImageNet dataset to evaluate the performance of popular explanation methods for three training strategies of the Vision Transformer (ViT). Based on this evaluation, we found Beyond Intuition and Generic Attribution to be the two most consistent explanation models. Further, and interestingly, the proposed framework results in higher and more consistent evaluation scores across all the ViT models considered in this work. To the best of our knowledge, InG is the first semi-synthetic framework for the evaluation of ViT explanation methods.
Minimizing Energy Costs in Deep Learning Model Training: The Gaussian Sampling Approach
Jun 11, 2024



Computing the loss gradient via backpropagation consumes considerable energy during deep learning (DL) model training. In this paper, we propose a novel approach to efficiently compute DL models' gradients to mitigate the substantial energy overhead associated with backpropagation. Exploiting the over-parameterized nature of DL models and the smoothness of their loss landscapes, we propose a method called {\em GradSamp} for sampling gradient updates from a Gaussian distribution. Specifically, we update model parameters at a given epoch (chosen periodically or randomly) by perturbing the parameters (element-wise) from the previous epoch with Gaussian ``noise''. The parameters of the Gaussian distribution are estimated using the error between the model parameter values from the two previous epochs. {\em GradSamp} not only streamlines gradient computation but also enables skipping entire epochs, thereby enhancing overall efficiency. We rigorously validate our hypothesis across a diverse set of standard and non-standard CNN and transformer-based models, spanning various computer vision tasks such as image classification, object detection, and image segmentation. Additionally, we explore its efficacy in out-of-distribution scenarios such as Domain Adaptation (DA), Domain Generalization (DG), and decentralized settings like Federated Learning (FL). Our experimental results affirm the effectiveness of {\em GradSamp} in achieving notable energy savings without compromising performance, underscoring its versatility and potential impact in practical DL applications.
Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark
Jan 03, 2022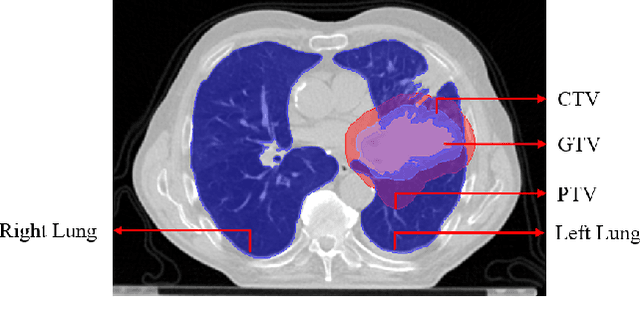
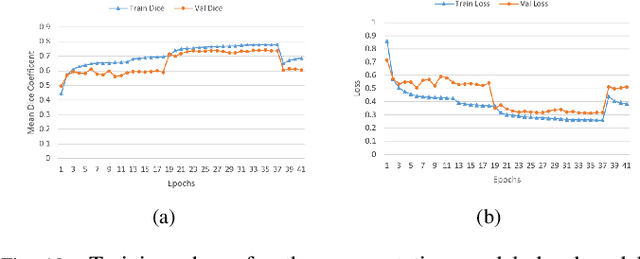
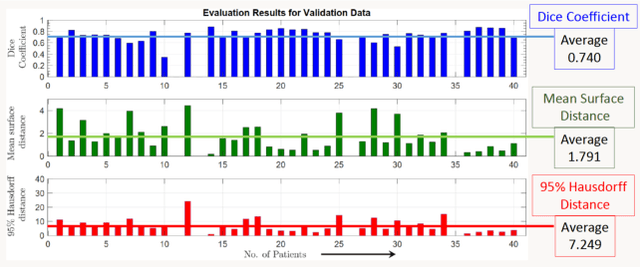
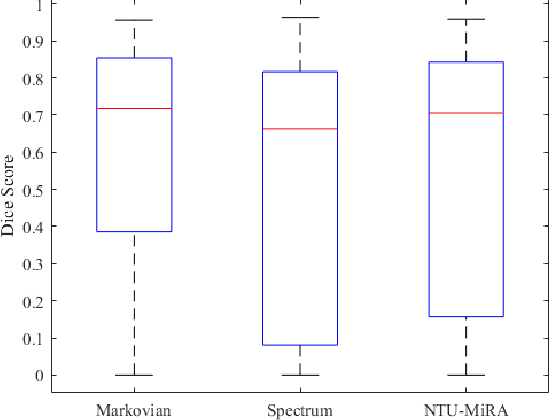
Lung cancer is one of the deadliest cancers, and in part its effective diagnosis and treatment depend on the accurate delineation of the tumor. Human-centered segmentation, which is currently the most common approach, is subject to inter-observer variability, and is also time-consuming, considering the fact that only experts are capable of providing annotations. Automatic and semi-automatic tumor segmentation methods have recently shown promising results. However, as different researchers have validated their algorithms using various datasets and performance metrics, reliably evaluating these methods is still an open challenge. The goal of the Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark created through 2018 IEEE Video and Image Processing (VIP) Cup competition, is to provide a unique dataset and pre-defined metrics, so that different researchers can develop and evaluate their methods in a unified fashion. The 2018 VIP Cup started with a global engagement from 42 countries to access the competition data. At the registration stage, there were 129 members clustered into 28 teams from 10 countries, out of which 9 teams made it to the final stage and 6 teams successfully completed all the required tasks. In a nutshell, all the algorithms proposed during the competition, are based on deep learning models combined with a false positive reduction technique. Methods developed by the three finalists show promising results in tumor segmentation, however, more effort should be put into reducing the false positive rate. This competition manuscript presents an overview of the VIP-Cup challenge, along with the proposed algorithms and results.
Perceptually Guided Adversarial Perturbations
Jun 24, 2021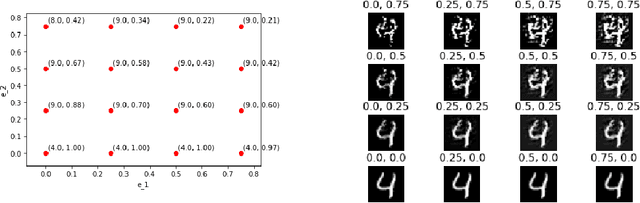

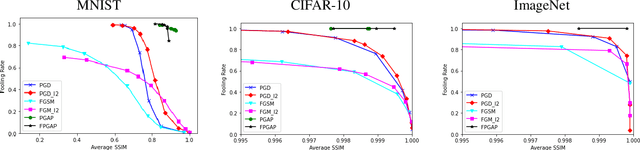

It is well known that carefully crafted imperceptible perturbations can cause state-of-the-art deep learning classification models to misclassify. Understanding and analyzing these adversarial perturbations play a crucial role in the design of robust convolutional neural networks. However, the reasons for the existence of adversarial perturbations and their mechanics are not well understood. In this work, we attempt to systematically answer the following question: do imperceptible adversarial perturbations focus on changing the regions of the image that are important for classification? Most current methods use $l_p$ distance to generate and characterize the imperceptibility of the adversarial perturbations. However, since $l_p$ distances only measure the pixel to pixel distances and do not consider the structure in the image, these methods do not provide a satisfactory answer to the above question. To address this issue, we propose a novel framework for generating adversarial perturbations by explicitly incorporating a ``perceptual quality ball" constraint in our formulation. Specifically, we pose the adversarial example generation problem as a tractable convex optimization problem, with constraints taken from a mathematically amenable variant of the popular SSIM index. We show that the perturbations generated by the proposed method result in a high fooling rate with minimal impact on perceptual quality compared to the norm bounded adversarial perturbations. Further, through SSIM maps, we show that the perceptually guided perturbations introduce changes specifically in the regions that contribute to classification decisions. We use networks trained on MNIST and CIFAR-10 datasets quantitative analysis, and MobileNetV2 trained on the ImageNet dataset for further qualitative analysis.
Deep No-reference Tone Mapped Image Quality Assessment
Feb 08, 2020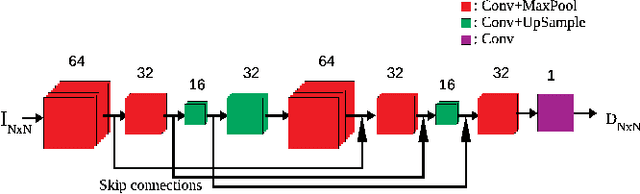
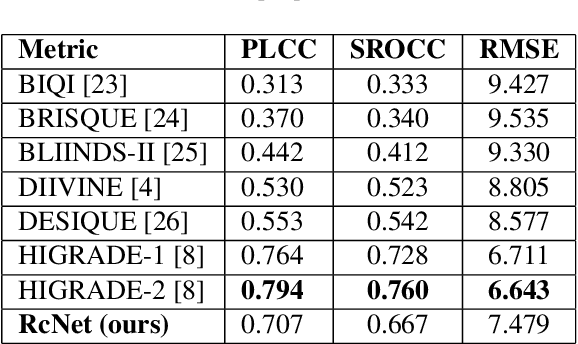

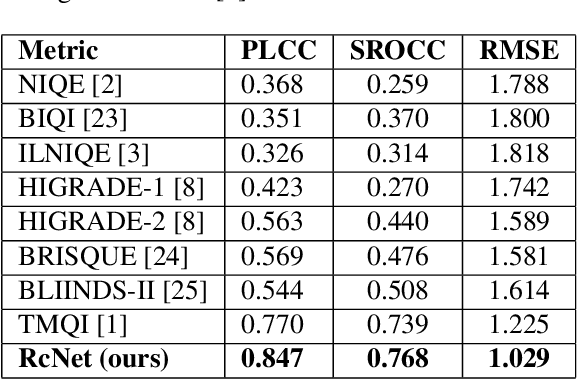
The process of rendering high dynamic range (HDR) images to be viewed on conventional displays is called tone mapping. However, tone mapping introduces distortions in the final image which may lead to visual displeasure. To quantify these distortions, we introduce a novel no-reference quality assessment technique for these tone mapped images. This technique is composed of two stages. In the first stage, we employ a convolutional neural network (CNN) to generate quality aware maps (also known as distortion maps) from tone mapped images by training it with the ground truth distortion maps. In the second stage, we model the normalized image and distortion maps using an Asymmetric Generalized Gaussian Distribution (AGGD). The parameters of the AGGD model are then used to estimate the quality score using support vector regression (SVR). We show that the proposed technique delivers competitive performance relative to the state-of-the-art techniques. The novelty of this work is its ability to visualize various distortions as quality maps (distortion maps), especially in the no-reference setting, and to use these maps as features to estimate the quality score of tone mapped images.
Quality Aware Generative Adversarial Networks
Nov 08, 2019
Generative Adversarial Networks (GANs) have become a very popular tool for implicitly learning high-dimensional probability distributions. Several improvements have been made to the original GAN formulation to address some of its shortcomings like mode collapse, convergence issues, entanglement, poor visual quality etc. While a significant effort has been directed towards improving the visual quality of images generated by GANs, it is rather surprising that objective image quality metrics have neither been employed as cost functions nor as regularizers in GAN objective functions. In this work, we show how a distance metric that is a variant of the Structural SIMilarity (SSIM) index (a popular full-reference image quality assessment algorithm), and a novel quality aware discriminator gradient penalty function that is inspired by the Natural Image Quality Evaluator (NIQE, a popular no-reference image quality assessment algorithm) can each be used as excellent regularizers for GAN objective functions. Specifically, we demonstrate state-of-the-art performance using the Wasserstein GAN gradient penalty (WGAN-GP) framework over CIFAR-10, STL10 and CelebA datasets.
Optical Character Recognition (OCR) for Telugu: Database, Algorithm and Application
Nov 20, 2017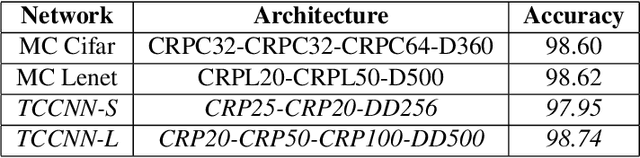
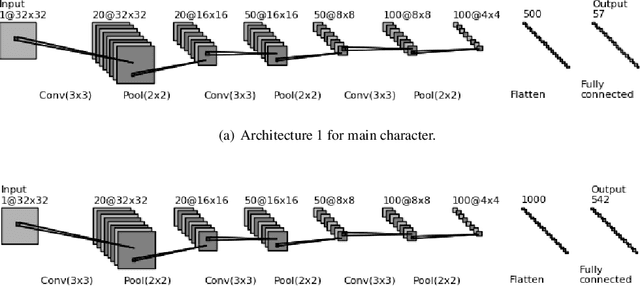
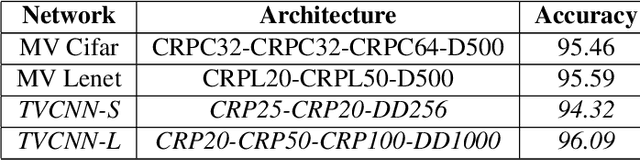
Telugu is a Dravidian language spoken by more than 80 million people worldwide. The optical character recognition (OCR) of the Telugu script has wide ranging applications including education, health-care, administration etc. The beautiful Telugu script however is very different from Germanic scripts like English and German. This makes the use of transfer learning of Germanic OCR solutions to Telugu a non-trivial task. To address the challenge of OCR for Telugu, we make three contributions in this work: (i) a database of Telugu characters, (ii) a deep learning based OCR algorithm, and (iii) a client server solution for the online deployment of the algorithm. For the benefit of the Telugu people and the research community, we will make our code freely available at https://gayamtrishal.github.io/OCR_Telugu.github.io/