 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Training of Federated Learning via Second-Order Methods
May 29, 2025This paper explores second-order optimization methods in Federated Learning (FL), addressing the critical challenges of slow convergence and the excessive communication rounds required to achieve optimal performance from the global model. While existing surveys in FL primarily focus on challenges related to statistical and device label heterogeneity, as well as privacy and security concerns in first-order FL methods, less attention has been given to the issue of slow model training. This slow training often leads to the need for excessive communication rounds or increased communication costs, particularly when data across clients are highly heterogeneous. In this paper, we examine various FL methods that leverage second-order optimization to accelerate the training process. We provide a comprehensive categorization of state-of-the-art second-order FL methods and compare their performance based on convergence speed, computational cost, memory usage, transmission overhead, and generalization of the global model. Our findings show the potential of incorporating Hessian curvature through second-order optimization into FL and highlight key challenges, such as the efficient utilization of Hessian and its inverse in FL. This work lays the groundwork for future research aimed at developing scalable and efficient federated optimization methods for improving the training of the global model in FL.
Minimizing Energy Costs in Deep Learning Model Training: The Gaussian Sampling Approach
Jun 11, 2024



Computing the loss gradient via backpropagation consumes considerable energy during deep learning (DL) model training. In this paper, we propose a novel approach to efficiently compute DL models' gradients to mitigate the substantial energy overhead associated with backpropagation. Exploiting the over-parameterized nature of DL models and the smoothness of their loss landscapes, we propose a method called {\em GradSamp} for sampling gradient updates from a Gaussian distribution. Specifically, we update model parameters at a given epoch (chosen periodically or randomly) by perturbing the parameters (element-wise) from the previous epoch with Gaussian ``noise''. The parameters of the Gaussian distribution are estimated using the error between the model parameter values from the two previous epochs. {\em GradSamp} not only streamlines gradient computation but also enables skipping entire epochs, thereby enhancing overall efficiency. We rigorously validate our hypothesis across a diverse set of standard and non-standard CNN and transformer-based models, spanning various computer vision tasks such as image classification, object detection, and image segmentation. Additionally, we explore its efficacy in out-of-distribution scenarios such as Domain Adaptation (DA), Domain Generalization (DG), and decentralized settings like Federated Learning (FL). Our experimental results affirm the effectiveness of {\em GradSamp} in achieving notable energy savings without compromising performance, underscoring its versatility and potential impact in practical DL applications.
Precision Guided Approach to Mitigate Data Poisoning Attacks in Federated Learning
Apr 05, 2024



Federated Learning (FL) is a collaborative learning paradigm enabling participants to collectively train a shared machine learning model while preserving the privacy of their sensitive data. Nevertheless, the inherent decentralized and data-opaque characteristics of FL render its susceptibility to data poisoning attacks. These attacks introduce malformed or malicious inputs during local model training, subsequently influencing the global model and resulting in erroneous predictions. Current FL defense strategies against data poisoning attacks either involve a trade-off between accuracy and robustness or necessitate the presence of a uniformly distributed root dataset at the server. To overcome these limitations, we present FedZZ, which harnesses a zone-based deviating update (ZBDU) mechanism to effectively counter data poisoning attacks in FL. Further, we introduce a precision-guided methodology that actively characterizes these client clusters (zones), which in turn aids in recognizing and discarding malicious updates at the server. Our evaluation of FedZZ across two widely recognized datasets: CIFAR10 and EMNIST, demonstrate its efficacy in mitigating data poisoning attacks, surpassing the performance of prevailing state-of-the-art methodologies in both single and multi-client attack scenarios and varying attack volumes. Notably, FedZZ also functions as a robust client selection strategy, even in highly non-IID and attack-free scenarios. Moreover, in the face of escalating poisoning rates, the model accuracy attained by FedZZ displays superior resilience compared to existing techniques. For instance, when confronted with a 50% presence of malicious clients, FedZZ sustains an accuracy of 67.43%, while the accuracy of the second-best solution, FL-Defender, diminishes to 43.36%.
ACLNet: An Attention and Clustering-based Cloud Segmentation Network
Jul 13, 2022
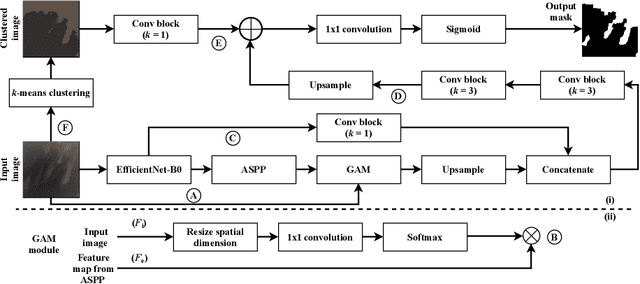
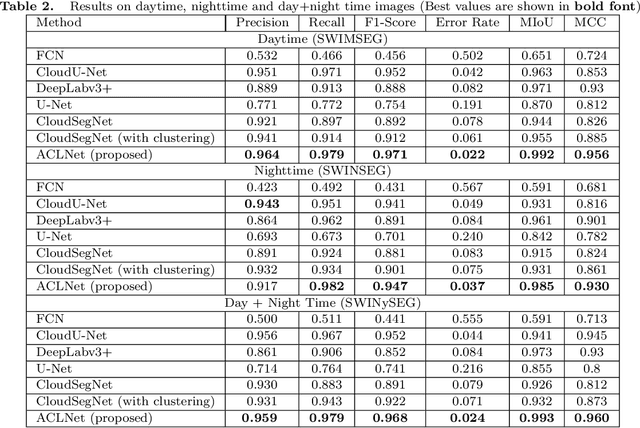

We propose a novel deep learning model named ACLNet, for cloud segmentation from ground images. ACLNet uses both deep neural network and machine learning (ML) algorithm to extract complementary features. Specifically, it uses EfficientNet-B0 as the backbone, "`a trous spatial pyramid pooling" (ASPP) to learn at multiple receptive fields, and "global attention module" (GAM) to extract finegrained details from the image. ACLNet also uses k-means clustering to extract cloud boundaries more precisely. ACLNet is effective for both daytime and nighttime images. It provides lower error rate, higher recall and higher F1-score than state-of-art cloud segmentation models. The source-code of ACLNet is available here: https://github.com/ckmvigil/ACLNet.
* 11 pages, 3 figures, 5 tables, Published in remote sensing letters
WaferSegClassNet -- A Light-weight Network for Classification and Segmentation of Semiconductor Wafer Defects
Jul 03, 2022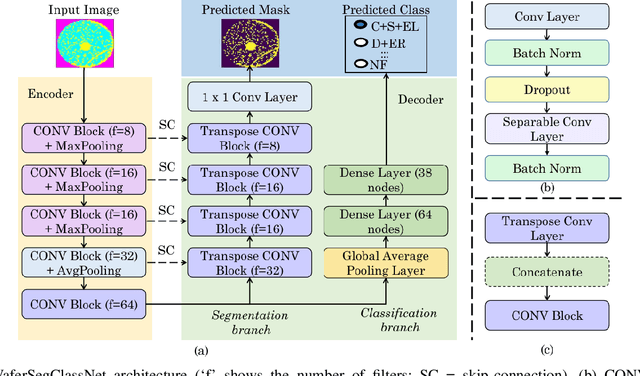
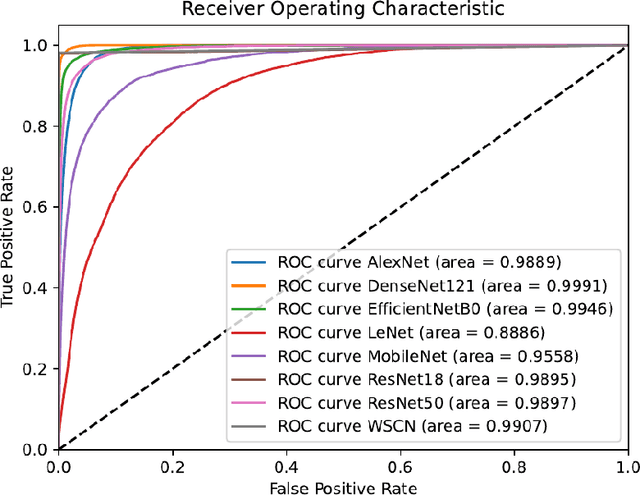

As the integration density and design intricacy of semiconductor wafers increase, the magnitude and complexity of defects in them are also on the rise. Since the manual inspection of wafer defects is costly, an automated artificial intelligence (AI) based computer-vision approach is highly desired. The previous works on defect analysis have several limitations, such as low accuracy and the need for separate models for classification and segmentation. For analyzing mixed-type defects, some previous works require separately training one model for each defect type, which is non-scalable. In this paper, we present WaferSegClassNet (WSCN), a novel network based on encoder-decoder architecture. WSCN performs simultaneous classification and segmentation of both single and mixed-type wafer defects. WSCN uses a "shared encoder" for classification, and segmentation, which allows training WSCN end-to-end. We use N-pair contrastive loss to first pretrain the encoder and then use BCE-Dice loss for segmentation, and categorical cross-entropy loss for classification. Use of N-pair contrastive loss helps in better embedding representation in the latent dimension of wafer maps. WSCN has a model size of only 0.51MB and performs only 0.2M FLOPS. Thus, it is much lighter than other state-of-the-art models. Also, it requires only 150 epochs for convergence, compared to 4,000 epochs needed by a previous work. We evaluate our model on the MixedWM38 dataset, which has 38,015 images. WSCN achieves an average classification accuracy of 98.2% and a dice coefficient of 0.9999. We are the first to show segmentation results on the MixedWM38 dataset. The source code can be obtained from https://github.com/ckmvigil/WaferSegClassNet.
* 11 pages, 2 figures, 7 tables, Published in Computers in Industry
Monte Carlo DropBlock for Modelling Uncertainty in Object Detection
Aug 08, 2021
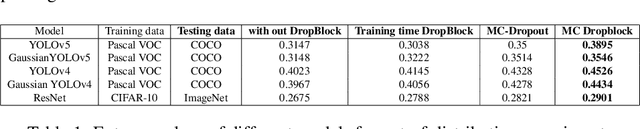
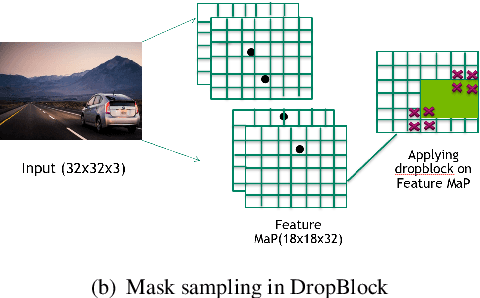
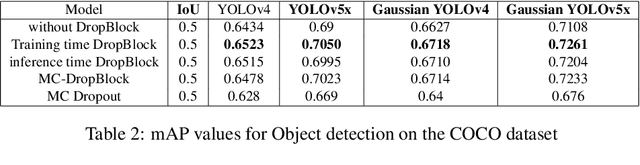
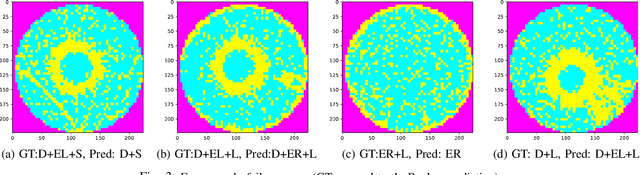
With the advancements made in deep learning, computer vision problems like object detection and segmentation have seen a great improvement in performance. However, in many real-world applications such as autonomous driving vehicles, the risk associated with incorrect predictions of objects is very high. Standard deep learning models for object detection such as YOLO models are often overconfident in their predictions and do not take into account the uncertainty in predictions on out-of-distribution data. In this work, we propose an efficient and effective approach to model uncertainty in object detection and segmentation tasks using Monte-Carlo DropBlock (MC-DropBlock) based inference. The proposed approach applies drop-block during training time and test time on the convolutional layer of the deep learning models such as YOLO. We show that this leads to a Bayesian convolutional neural network capable of capturing the epistemic uncertainty in the model. Additionally, we capture the aleatoric uncertainty using a Gaussian likelihood. We demonstrate the effectiveness of the proposed approach on modeling uncertainty in object detection and segmentation tasks using out-of-distribution experiments. Experimental results show that MC-DropBlock improves the generalization, calibration, and uncertainty modeling capabilities of YOLO models in object detection and segmentation.
Black-box Adversarial Attacks in Autonomous Vehicle Technology
Jan 15, 2021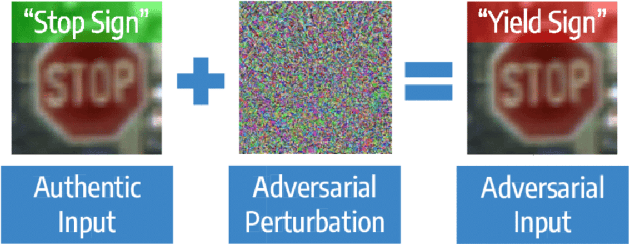
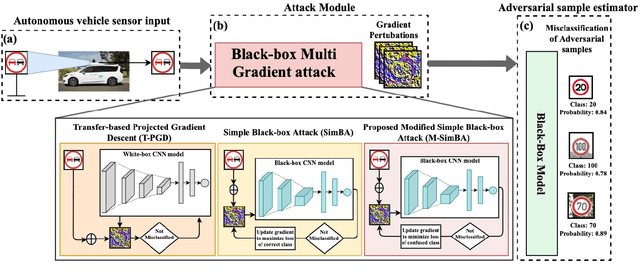
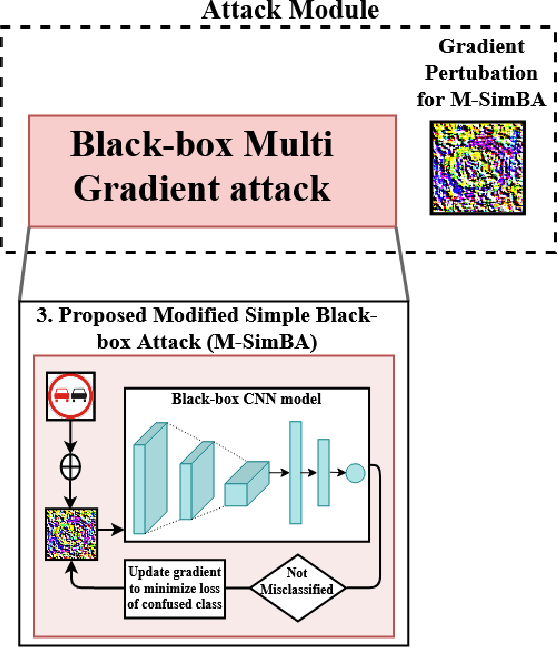
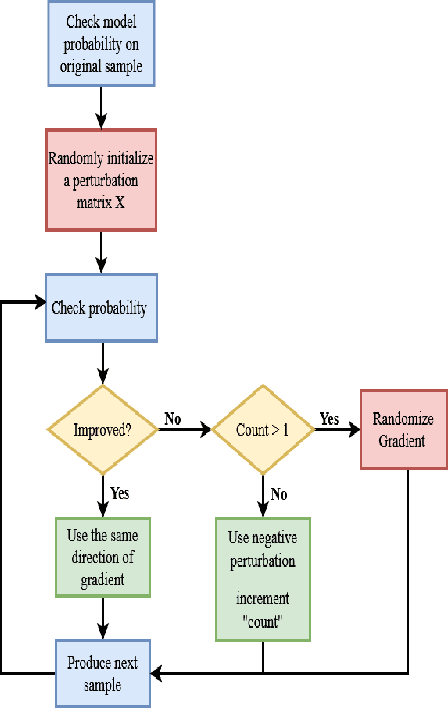
Despite the high quality performance of the deep neural network in real-world applications, they are susceptible to minor perturbations of adversarial attacks. This is mostly undetectable to human vision. The impact of such attacks has become extremely detrimental in autonomous vehicles with real-time "safety" concerns. The black-box adversarial attacks cause drastic misclassification in critical scene elements such as road signs and traffic lights leading the autonomous vehicle to crash into other vehicles or pedestrians. In this paper, we propose a novel query-based attack method called Modified Simple black-box attack (M-SimBA) to overcome the use of a white-box source in transfer based attack method. Also, the issue of late convergence in a Simple black-box attack (SimBA) is addressed by minimizing the loss of the most confused class which is the incorrect class predicted by the model with the highest probability, instead of trying to maximize the loss of the correct class. We evaluate the performance of the proposed approach to the German Traffic Sign Recognition Benchmark (GTSRB) dataset. We show that the proposed model outperforms the existing models like Transfer-based projected gradient descent (T-PGD), SimBA in terms of convergence time, flattening the distribution of confused class probability, and producing adversarial samples with least confidence on the true class.