 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest of Both Worlds: Multimodal Reasoning and Generation via Unified Discrete Flow Matching
Feb 12, 2026We propose UniDFlow, a unified discrete flow-matching framework for multimodal understanding, generation, and editing. It decouples understanding and generation via task-specific low-rank adapters, avoiding objective interference and representation entanglement, while a novel reference-based multimodal preference alignment optimizes relative outcomes under identical conditioning, improving faithfulness and controllability without large-scale retraining. UniDFlpw achieves SOTA performance across eight benchmarks and exhibits strong zero-shot generalization to tasks including inpainting, in-context image generation, reference-based editing, and compositional generation, despite no explicit task-specific training.
ViCTr: Vital Consistency Transfer for Pathology Aware Image Synthesis
May 08, 2025Synthesizing medical images remains challenging due to limited annotated pathological data, modality domain gaps, and the complexity of representing diffuse pathologies such as liver cirrhosis. Existing methods often struggle to maintain anatomical fidelity while accurately modeling pathological features, frequently relying on priors derived from natural images or inefficient multi-step sampling. In this work, we introduce ViCTr (Vital Consistency Transfer), a novel two-stage framework that combines a rectified flow trajectory with a Tweedie-corrected diffusion process to achieve high-fidelity, pathology-aware image synthesis. First, we pretrain ViCTr on the ATLAS-8k dataset using Elastic Weight Consolidation (EWC) to preserve critical anatomical structures. We then fine-tune the model adversarially with Low-Rank Adaptation (LoRA) modules for precise control over pathology severity. By reformulating Tweedie's formula within a linear trajectory framework, ViCTr supports one-step sampling, reducing inference from 50 steps to just 4, without sacrificing anatomical realism. We evaluate ViCTr on BTCV (CT), AMOS (MRI), and CirrMRI600+ (cirrhosis) datasets. Results demonstrate state-of-the-art performance, achieving a Medical Frechet Inception Distance (MFID) of 17.01 for cirrhosis synthesis 28% lower than existing approaches and improving nnUNet segmentation by +3.8% mDSC when used for data augmentation. Radiologist reviews indicate that ViCTr-generated liver cirrhosis MRIs are clinically indistinguishable from real scans. To our knowledge, ViCTr is the first method to provide fine-grained, pathology-aware MRI synthesis with graded severity control, closing a critical gap in AI-driven medical imaging research.
Dressing the Imagination: A Dataset for AI-Powered Translation of Text into Fashion Outfits and A Novel KAN Adapter for Enhanced Feature Adaptation
Nov 21, 2024



Specialized datasets that capture the fashion industry's rich language and styling elements can boost progress in AI-driven fashion design. We present FLORA (Fashion Language Outfit Representation for Apparel Generation), the first comprehensive dataset containing 4,330 curated pairs of fashion outfits and corresponding textual descriptions. Each description utilizes industry-specific terminology and jargon commonly used by professional fashion designers, providing precise and detailed insights into the outfits. Hence, the dataset captures the delicate features and subtle stylistic elements necessary to create high-fidelity fashion designs. We demonstrate that fine-tuning generative models on the FLORA dataset significantly enhances their capability to generate accurate and stylistically rich images from textual descriptions of fashion sketches. FLORA will catalyze the creation of advanced AI models capable of comprehending and producing subtle, stylistically rich fashion designs. It will also help fashion designers and end-users to bring their ideas to life. As a second orthogonal contribution, we introduce KAN Adapters, which leverage Kolmogorov-Arnold Networks (KAN) as adaptive modules. They serve as replacements for traditional MLP-based LoRA adapters. With learnable spline-based activations, KAN Adapters excel in modeling complex, non-linear relationships, achieving superior fidelity, faster convergence and semantic alignment. Extensive experiments and ablation studies on our proposed FLORA dataset validate the superiority of KAN Adapters over LoRA adapters. To foster further research and collaboration, we will open-source both the FLORA and our implementation code.
D2Styler: Advancing Arbitrary Style Transfer with Discrete Diffusion Methods
Aug 07, 2024



In image processing, one of the most challenging tasks is to render an image's semantic meaning using a variety of artistic approaches. Existing techniques for arbitrary style transfer (AST) frequently experience mode-collapse, over-stylization, or under-stylization due to a disparity between the style and content images. We propose a novel framework called D$^2$Styler (Discrete Diffusion Styler) that leverages the discrete representational capability of VQ-GANs and the advantages of discrete diffusion, including stable training and avoidance of mode collapse. Our method uses Adaptive Instance Normalization (AdaIN) features as a context guide for the reverse diffusion process. This makes it easy to move features from the style image to the content image without bias. The proposed method substantially enhances the visual quality of style-transferred images, allowing the combination of content and style in a visually appealing manner. We take style images from the WikiArt dataset and content images from the COCO dataset. Experimental results demonstrate that D$^2$Styler produces high-quality style-transferred images and outperforms twelve existing methods on nearly all the metrics. The qualitative results and ablation studies provide further insights into the efficacy of our technique. The code is available at https://github.com/Onkarsus13/D2Styler.
TPFNet: A Novel Text In-painting Transformer for Text Removal
Oct 27, 2022
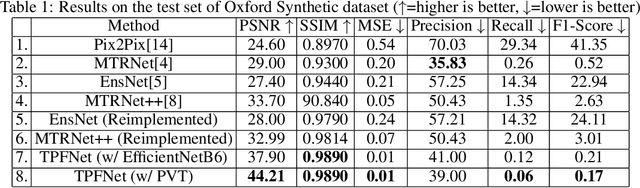

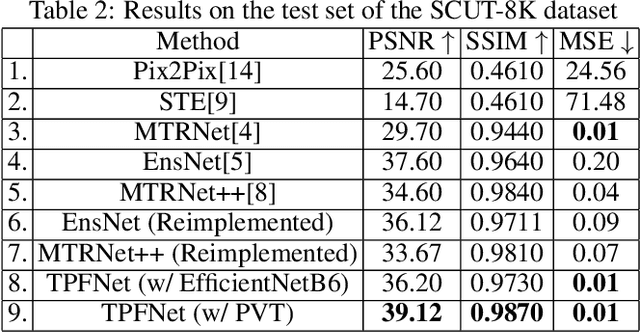
Text erasure from an image is helpful for various tasks such as image editing and privacy preservation. In this paper, we present TPFNet, a novel one-stage (end-toend) network for text removal from images. Our network has two parts: feature synthesis and image generation. Since noise can be more effectively removed from low-resolution images, part 1 operates on low-resolution images. The output of part 1 is a low-resolution text-free image. Part 2 uses the features learned in part 1 to predict a high-resolution text-free image. In part 1, we use "pyramidal vision transformer" (PVT) as the encoder. Further, we use a novel multi-headed decoder that generates a high-pass filtered image and a segmentation map, in addition to a text-free image. The segmentation branch helps locate the text precisely, and the high-pass branch helps in learning the image structure. To precisely locate the text, TPFNet employs an adversarial loss that is conditional on the segmentation map rather than the input image. On Oxford, SCUT, and SCUT-EnsText datasets, our network outperforms recently proposed networks on nearly all the metrics. For example, on SCUT-EnsText dataset, TPFNet has a PSNR (higher is better) of 39.0 and text-detection precision (lower is better) of 21.1, compared to the best previous technique, which has a PSNR of 32.3 and precision of 53.2. The source code can be obtained from https://github.com/CandleLabAI/TPFNet
ACLNet: An Attention and Clustering-based Cloud Segmentation Network
Jul 13, 2022
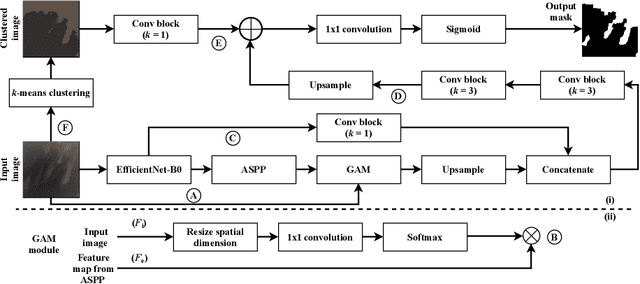
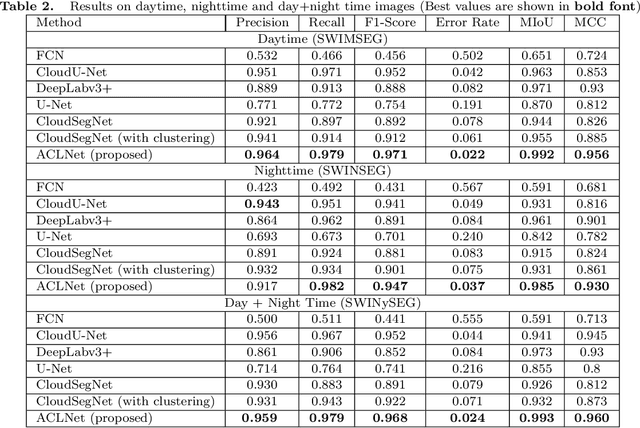

We propose a novel deep learning model named ACLNet, for cloud segmentation from ground images. ACLNet uses both deep neural network and machine learning (ML) algorithm to extract complementary features. Specifically, it uses EfficientNet-B0 as the backbone, "`a trous spatial pyramid pooling" (ASPP) to learn at multiple receptive fields, and "global attention module" (GAM) to extract finegrained details from the image. ACLNet also uses k-means clustering to extract cloud boundaries more precisely. ACLNet is effective for both daytime and nighttime images. It provides lower error rate, higher recall and higher F1-score than state-of-art cloud segmentation models. The source-code of ACLNet is available here: https://github.com/ckmvigil/ACLNet.
* 11 pages, 3 figures, 5 tables, Published in remote sensing letters