 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2Styler: Advancing Arbitrary Style Transfer with Discrete Diffusion Methods
Aug 07, 2024



In image processing, one of the most challenging tasks is to render an image's semantic meaning using a variety of artistic approaches. Existing techniques for arbitrary style transfer (AST) frequently experience mode-collapse, over-stylization, or under-stylization due to a disparity between the style and content images. We propose a novel framework called D$^2$Styler (Discrete Diffusion Styler) that leverages the discrete representational capability of VQ-GANs and the advantages of discrete diffusion, including stable training and avoidance of mode collapse. Our method uses Adaptive Instance Normalization (AdaIN) features as a context guide for the reverse diffusion process. This makes it easy to move features from the style image to the content image without bias. The proposed method substantially enhances the visual quality of style-transferred images, allowing the combination of content and style in a visually appealing manner. We take style images from the WikiArt dataset and content images from the COCO dataset. Experimental results demonstrate that D$^2$Styler produces high-quality style-transferred images and outperforms twelve existing methods on nearly all the metrics. The qualitative results and ablation studies provide further insights into the efficacy of our technique. The code is available at https://github.com/Onkarsus13/D2Styler.
Adversarial synthesis based data-augmentation for code-switched spoken language identification
Jun 01, 2022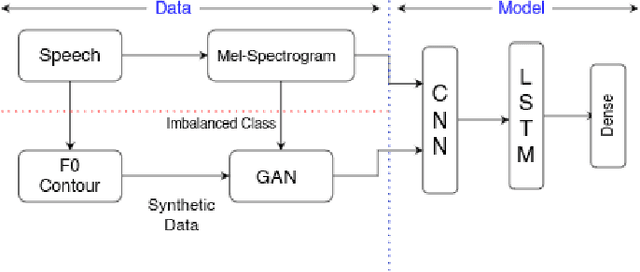
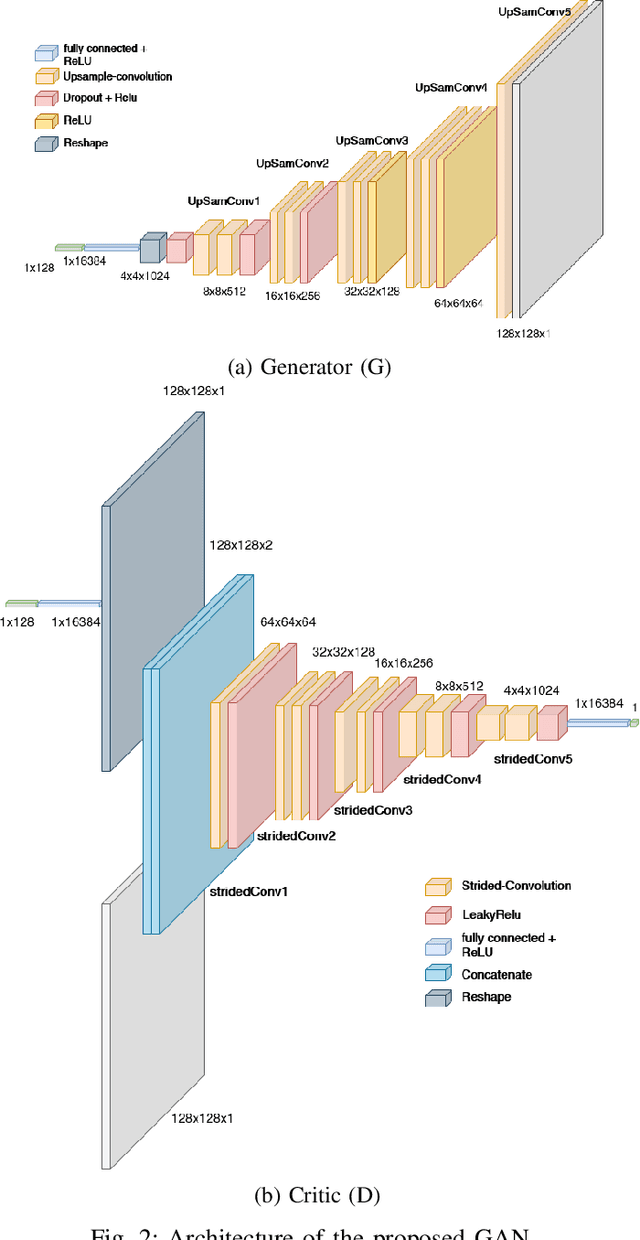
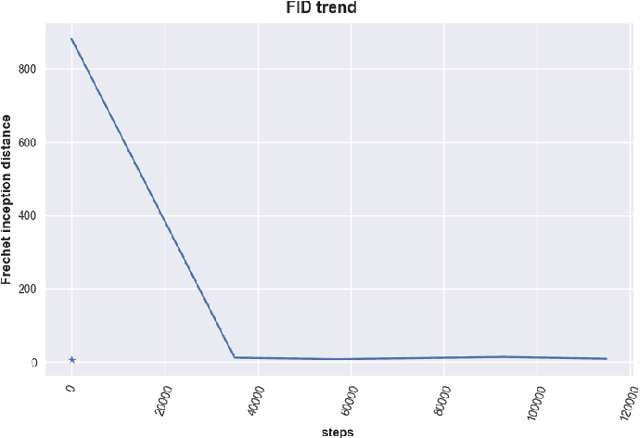
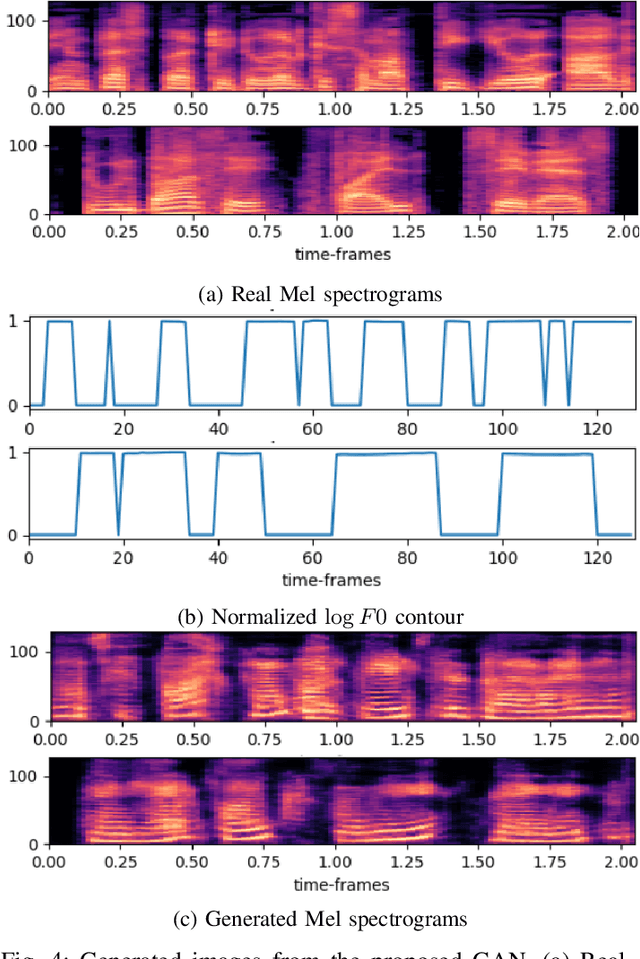
Spoken Language Identification (LID) is an important sub-task of Automatic Speech Recognition(ASR) that is used to classify the language(s) in an audio segment. Automatic LID plays an useful role in multilingual countries. In various countries, identifying a language becomes hard, due to the multilingual scenario where two or more than two languages are mixed together during conversation. Such phenomenon of speech is called as code-mixing or code-switching. This nature is followed not only in India but also in many Asian countries. Such code-mixed data is hard to find, which further reduces the capabilities of the spoken LID. Hence, this work primarily addresses this problem using data augmentation as a solution on the on the data scarcity of the code-switched class. This study focuses on Indic language code-mixed with English. Spoken LID is performed on Hindi, code-mixed with English. This research proposes Generative Adversarial Network (GAN) based data augmentation technique performed using Mel spectrograms for audio data. GANs have already been proven to be accurate in representing the real data distribution in the image domain. Proposed research exploits these capabilities of GANs in speech domains such as speech classification, automatic speech recognition, etc. GANs are trained to generate Mel spectrograms of the minority code-mixed class which are then used to augment data for the classifier. Utilizing GANs give an overall improvement on Unweighted Average Recall by an amount of 3.5% as compared to a Convolutional Recurrent Neural Network (CRNN) classifier used as the baseline reference.