 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest of Both Worlds: Multimodal Reasoning and Generation via Unified Discrete Flow Matching
Feb 12, 2026We propose UniDFlow, a unified discrete flow-matching framework for multimodal understanding, generation, and editing. It decouples understanding and generation via task-specific low-rank adapters, avoiding objective interference and representation entanglement, while a novel reference-based multimodal preference alignment optimizes relative outcomes under identical conditioning, improving faithfulness and controllability without large-scale retraining. UniDFlpw achieves SOTA performance across eight benchmarks and exhibits strong zero-shot generalization to tasks including inpainting, in-context image generation, reference-based editing, and compositional generation, despite no explicit task-specific training.
Historic Scripts to Modern Vision: A Novel Dataset and A VLM Framework for Transliteration of Modi Script to Devanagari
Mar 17, 2025In medieval India, the Marathi language was written using the Modi script. The texts written in Modi script include extensive knowledge about medieval sciences, medicines, land records and authentic evidence about Indian history. Around 40 million documents are in poor condition and have not yet been transliterated. Furthermore, only a few experts in this domain can transliterate this script into English or Devanagari. Most of the past research predominantly focuses on individual character recognition. A system that can transliterate Modi script documents to Devanagari script is needed. We propose the MoDeTrans dataset, comprising 2,043 images of Modi script documents accompanied by their corresponding textual transliterations in Devanagari. We further introduce MoScNet (\textbf{Mo}di \textbf{Sc}ript \textbf{Net}work), a novel Vision-Language Model (VLM) framework for transliterating Modi script images into Devanagari text. MoScNet leverages Knowledge Distillation, where a student model learns from a teacher model to enhance transliteration performance. The final student model of MoScNet has better performance than the teacher model while having 163$\times$ lower parameters. Our work is the first to perform direct transliteration from the handwritten Modi script to the Devanagari script. MoScNet also shows competitive results on the optical character recognition (OCR) task.
L2GNet: Optimal Local-to-Global Representation of Anatomical Structures for Generalized Medical Image Segmentation
Feb 06, 2025



Continuous Latent Space (CLS) and Discrete Latent Space (DLS) models, like AttnUNet and VQUNet, have excelled in medical image segmentation. In contrast, Synergistic Continuous and Discrete Latent Space (CDLS) models show promise in handling fine and coarse-grained information. However, they struggle with modeling long-range dependencies. CLS or CDLS-based models, such as TransUNet or SynergyNet are adept at capturing long-range dependencies. Since they rely heavily on feature pooling or aggregation using self-attention, they may capture dependencies among redundant regions. This hinders comprehension of anatomical structure content, poses challenges in modeling intra-class and inter-class dependencies, increases false negatives and compromises generalization. Addressing these issues, we propose L2GNet, which learns global dependencies by relating discrete codes obtained from DLS using optimal transport and aligning codes on a trainable reference. L2GNet achieves discriminative on-the-fly representation learning without an additional weight matrix in self-attention models, making it computationally efficient for medical applications. Extensive experiments on multi-organ segmentation and cardiac datasets demonstrate L2GNet's superiority over state-of-the-art methods, including the CDLS method SynergyNet, offering an novel approach to enhance deep learning models' performance in medical image analysis.
Dressing the Imagination: A Dataset for AI-Powered Translation of Text into Fashion Outfits and A Novel KAN Adapter for Enhanced Feature Adaptation
Nov 21, 2024



Specialized datasets that capture the fashion industry's rich language and styling elements can boost progress in AI-driven fashion design. We present FLORA (Fashion Language Outfit Representation for Apparel Generation), the first comprehensive dataset containing 4,330 curated pairs of fashion outfits and corresponding textual descriptions. Each description utilizes industry-specific terminology and jargon commonly used by professional fashion designers, providing precise and detailed insights into the outfits. Hence, the dataset captures the delicate features and subtle stylistic elements necessary to create high-fidelity fashion designs. We demonstrate that fine-tuning generative models on the FLORA dataset significantly enhances their capability to generate accurate and stylistically rich images from textual descriptions of fashion sketches. FLORA will catalyze the creation of advanced AI models capable of comprehending and producing subtle, stylistically rich fashion designs. It will also help fashion designers and end-users to bring their ideas to life. As a second orthogonal contribution, we introduce KAN Adapters, which leverage Kolmogorov-Arnold Networks (KAN) as adaptive modules. They serve as replacements for traditional MLP-based LoRA adapters. With learnable spline-based activations, KAN Adapters excel in modeling complex, non-linear relationships, achieving superior fidelity, faster convergence and semantic alignment. Extensive experiments and ablation studies on our proposed FLORA dataset validate the superiority of KAN Adapters over LoRA adapters. To foster further research and collaboration, we will open-source both the FLORA and our implementation code.
Comparison of Machine Learning Approaches for Classifying Spinodal Events
Oct 13, 2024



In this work, we compare the performance of deep learning models for classifying the spinodal dataset. We evaluate state-of-the-art models (MobileViT, NAT, EfficientNet, CNN), alongside several ensemble models (majority voting, AdaBoost). Additionally, we explore the dataset in a transformed color space. Our findings show that NAT and MobileViT outperform other models, achieving the highest metrics-accuracy, AUC, and F1 score on both training and testing data (NAT: 94.65, 0.98, 0.94; MobileViT: 94.20, 0.98, 0.94), surpassing the earlier CNN model (88.44, 0.95, 0.88). We also discuss failure cases for the top performing models.
MotionAura: Generating High-Quality and Motion Consistent Videos using Discrete Diffusion
Oct 10, 2024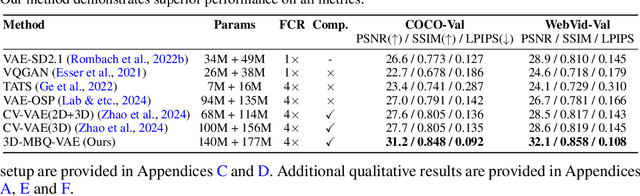
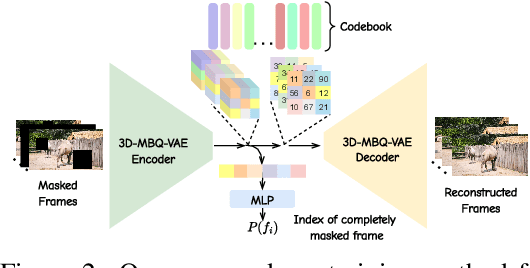
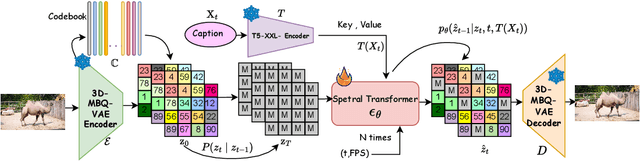
The spatio-temporal complexity of video data presents significant challenges in tasks such as compression, generation, and inpainting. We present four key contributions to address the challenges of spatiotemporal video processing. First, we introduce the 3D Mobile Inverted Vector-Quantization Variational Autoencoder (3D-MBQ-VAE), which combines Variational Autoencoders (VAEs) with masked token modeling to enhance spatiotemporal video compression. The model achieves superior temporal consistency and state-of-the-art (SOTA) reconstruction quality by employing a novel training strategy with full frame masking. Second, we present MotionAura, a text-to-video generation framework that utilizes vector-quantized diffusion models to discretize the latent space and capture complex motion dynamics, producing temporally coherent videos aligned with text prompts. Third, we propose a spectral transformer-based denoising network that processes video data in the frequency domain using the Fourier Transform. This method effectively captures global context and long-range dependencies for high-quality video generation and denoising. Lastly, we introduce a downstream task of Sketch Guided Video Inpainting. This task leverages Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning. Our models achieve SOTA performance on a range of benchmarks. Our work offers robust frameworks for spatiotemporal modeling and user-driven video content manipulation. We will release the code, datasets, and models in open-source.
Hybrid Quantum Neural Network based Indoor User Localization using Cloud Quantum Computing
Oct 01, 2024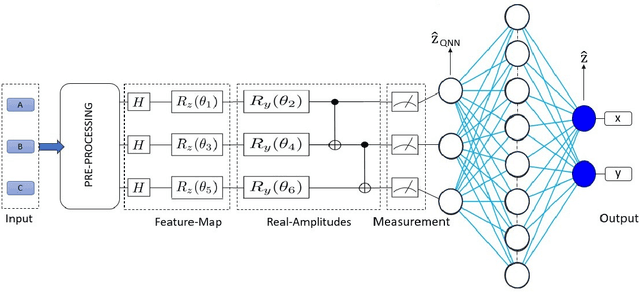
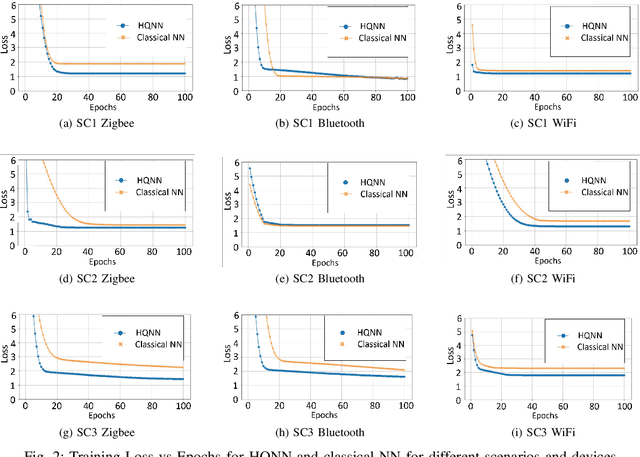
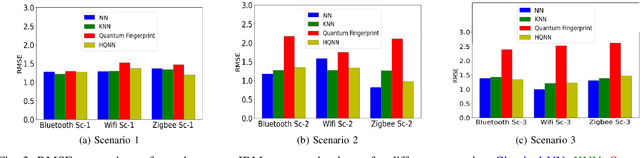
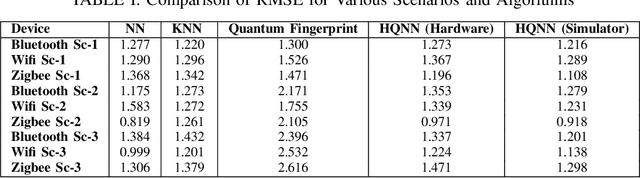
This paper proposes a hybrid quantum neural network (HQNN) for indoor user localization using received signal strength indicator (RSSI) values. We use publicly available RSSI datasets for indoor localization using WiFi, Bluetooth, and Zigbee to test the performance of the proposed HQNN. We also compare the performance of the HQNN with the recently proposed quantum fingerprinting-based user localization method. Our results show that the proposed HQNN performs better than the quantum fingerprinting algorithm since the HQNN has trainable parameters in the quantum circuits, whereas the quantum fingerprinting algorithm uses a fixed quantum circuit to calculate the similarity between the test data point and the fingerprint dataset. Unlike prior works, we also test the performance of the HQNN and quantum fingerprint algorithm on a real IBM quantum computer using cloud quantum computing services. Therefore, this paper examines the performance of the HQNN on noisy intermediate scale (NISQ) quantum devices using real-world RSSI localization datasets. The novelty of our approach lies in the use of simple feature maps and ansatz with fewer neurons, alongside testing on actual quantum hardware using real-world data, demonstrating practical applicability in real-world scenarios.
D2Styler: Advancing Arbitrary Style Transfer with Discrete Diffusion Methods
Aug 07, 2024



In image processing, one of the most challenging tasks is to render an image's semantic meaning using a variety of artistic approaches. Existing techniques for arbitrary style transfer (AST) frequently experience mode-collapse, over-stylization, or under-stylization due to a disparity between the style and content images. We propose a novel framework called D$^2$Styler (Discrete Diffusion Styler) that leverages the discrete representational capability of VQ-GANs and the advantages of discrete diffusion, including stable training and avoidance of mode collapse. Our method uses Adaptive Instance Normalization (AdaIN) features as a context guide for the reverse diffusion process. This makes it easy to move features from the style image to the content image without bias. The proposed method substantially enhances the visual quality of style-transferred images, allowing the combination of content and style in a visually appealing manner. We take style images from the WikiArt dataset and content images from the COCO dataset. Experimental results demonstrate that D$^2$Styler produces high-quality style-transferred images and outperforms twelve existing methods on nearly all the metrics. The qualitative results and ablation studies provide further insights into the efficacy of our technique. The code is available at https://github.com/Onkarsus13/D2Styler.
Harmonized Spatial and Spectral Learning for Robust and Generalized Medical Image Segmentation
Jan 18, 2024



Deep learning has demonstrated remarkable achievements in medical image segmentation. However, prevailing deep learning models struggle with poor generalization due to (i) intra-class variations, where the same class appears differently in different samples, and (ii) inter-class independence, resulting in difficulties capturing intricate relationships between distinct objects, leading to higher false negative cases. This paper presents a novel approach that synergies spatial and spectral representations to enhance domain-generalized medical image segmentation. We introduce the innovative Spectral Correlation Coefficient objective to improve the model's capacity to capture middle-order features and contextual long-range dependencies. This objective complements traditional spatial objectives by incorporating valuable spectral information. Extensive experiments reveal that optimizing this objective with existing architectures like UNet and TransUNet significantly enhances generalization, interpretability, and noise robustness, producing more confident predictions. For instance, in cardiac segmentation, we observe a 0.81 pp and 1.63 pp (pp = percentage point) improvement in DSC over UNet and TransUNet, respectively. Our interpretability study demonstrates that, in most tasks, objectives optimized with UNet outperform even TransUNet by introducing global contextual information alongside local details. These findings underscore the versatility and effectiveness of our proposed method across diverse imaging modalities and medical domains.
SPEEDNet: Salient Pyramidal Enhancement Encoder-Decoder Network for Colonoscopy Images
Dec 02, 2023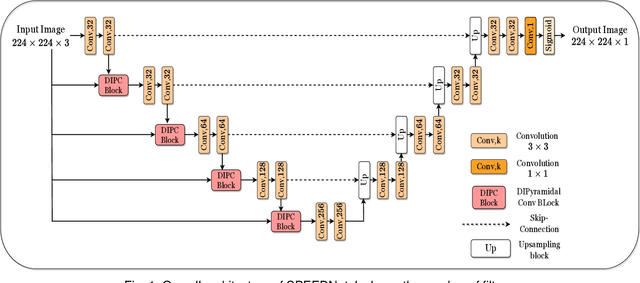
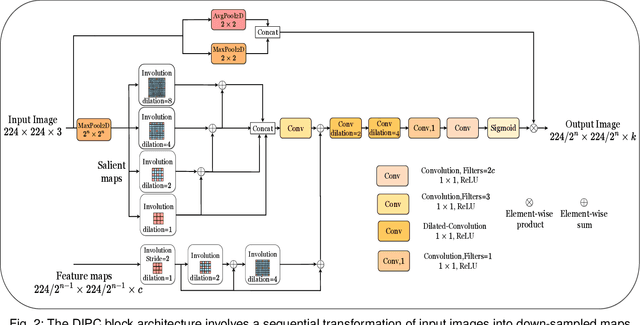

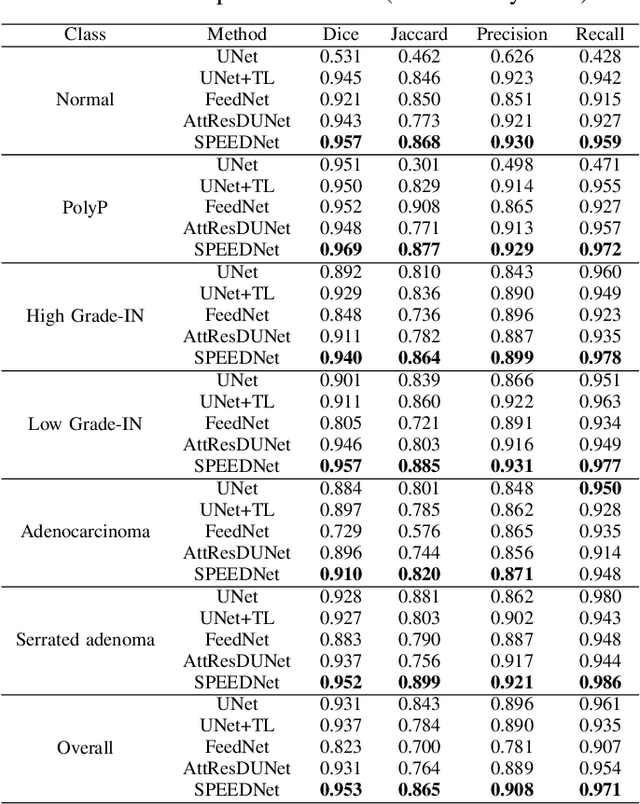
Accurate identification and precise delineation of regions of significance, such as tumors or lesions, is a pivotal goal in medical imaging analysis. This paper proposes SPEEDNet, a novel architecture for precisely segmenting lesions within colonoscopy images. SPEEDNet uses a novel block named Dilated-Involutional Pyramidal Convolution Fusion (DIPC). A DIPC block combines the dilated involution layers pairwise into a pyramidal structure to convert the feature maps into a compact space. This lowers the total number of parameters while improving the learning of representations across an optimal receptive field, thereby reducing the blurring effect. On the EBHISeg dataset, SPEEDNet outperforms three previous networks: UNet, FeedNet, and AttesResDUNet. Specifically, SPEEDNet attains an average dice score of 0.952 and a recall of 0.971. Qualitative results and ablation studies provide additional insights into the effectiveness of SPEEDNet. The model size of SPEEDNet is 9.81 MB, significantly smaller than that of UNet (22.84 MB), FeedNet(185.58 MB), and AttesResDUNet (140.09 MB).