 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDressing the Imagination: A Dataset for AI-Powered Translation of Text into Fashion Outfits and A Novel KAN Adapter for Enhanced Feature Adaptation
Nov 21, 2024



Specialized datasets that capture the fashion industry's rich language and styling elements can boost progress in AI-driven fashion design. We present FLORA (Fashion Language Outfit Representation for Apparel Generation), the first comprehensive dataset containing 4,330 curated pairs of fashion outfits and corresponding textual descriptions. Each description utilizes industry-specific terminology and jargon commonly used by professional fashion designers, providing precise and detailed insights into the outfits. Hence, the dataset captures the delicate features and subtle stylistic elements necessary to create high-fidelity fashion designs. We demonstrate that fine-tuning generative models on the FLORA dataset significantly enhances their capability to generate accurate and stylistically rich images from textual descriptions of fashion sketches. FLORA will catalyze the creation of advanced AI models capable of comprehending and producing subtle, stylistically rich fashion designs. It will also help fashion designers and end-users to bring their ideas to life. As a second orthogonal contribution, we introduce KAN Adapters, which leverage Kolmogorov-Arnold Networks (KAN) as adaptive modules. They serve as replacements for traditional MLP-based LoRA adapters. With learnable spline-based activations, KAN Adapters excel in modeling complex, non-linear relationships, achieving superior fidelity, faster convergence and semantic alignment. Extensive experiments and ablation studies on our proposed FLORA dataset validate the superiority of KAN Adapters over LoRA adapters. To foster further research and collaboration, we will open-source both the FLORA and our implementation code.
MotionAura: Generating High-Quality and Motion Consistent Videos using Discrete Diffusion
Oct 10, 2024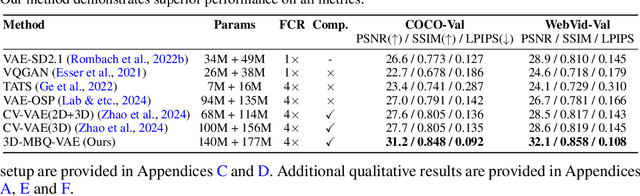
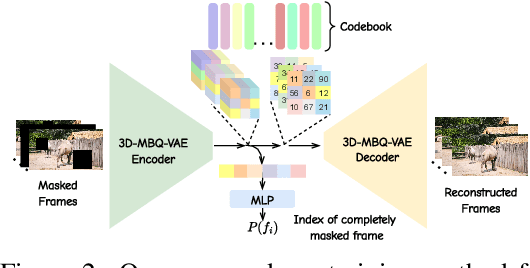
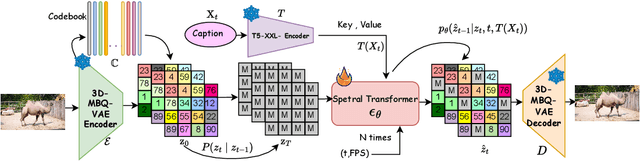
The spatio-temporal complexity of video data presents significant challenges in tasks such as compression, generation, and inpainting. We present four key contributions to address the challenges of spatiotemporal video processing. First, we introduce the 3D Mobile Inverted Vector-Quantization Variational Autoencoder (3D-MBQ-VAE), which combines Variational Autoencoders (VAEs) with masked token modeling to enhance spatiotemporal video compression. The model achieves superior temporal consistency and state-of-the-art (SOTA) reconstruction quality by employing a novel training strategy with full frame masking. Second, we present MotionAura, a text-to-video generation framework that utilizes vector-quantized diffusion models to discretize the latent space and capture complex motion dynamics, producing temporally coherent videos aligned with text prompts. Third, we propose a spectral transformer-based denoising network that processes video data in the frequency domain using the Fourier Transform. This method effectively captures global context and long-range dependencies for high-quality video generation and denoising. Lastly, we introduce a downstream task of Sketch Guided Video Inpainting. This task leverages Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning. Our models achieve SOTA performance on a range of benchmarks. Our work offers robust frameworks for spatiotemporal modeling and user-driven video content manipulation. We will release the code, datasets, and models in open-source.