 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL2GNet: Optimal Local-to-Global Representation of Anatomical Structures for Generalized Medical Image Segmentation
Feb 06, 2025



Continuous Latent Space (CLS) and Discrete Latent Space (DLS) models, like AttnUNet and VQUNet, have excelled in medical image segmentation. In contrast, Synergistic Continuous and Discrete Latent Space (CDLS) models show promise in handling fine and coarse-grained information. However, they struggle with modeling long-range dependencies. CLS or CDLS-based models, such as TransUNet or SynergyNet are adept at capturing long-range dependencies. Since they rely heavily on feature pooling or aggregation using self-attention, they may capture dependencies among redundant regions. This hinders comprehension of anatomical structure content, poses challenges in modeling intra-class and inter-class dependencies, increases false negatives and compromises generalization. Addressing these issues, we propose L2GNet, which learns global dependencies by relating discrete codes obtained from DLS using optimal transport and aligning codes on a trainable reference. L2GNet achieves discriminative on-the-fly representation learning without an additional weight matrix in self-attention models, making it computationally efficient for medical applications. Extensive experiments on multi-organ segmentation and cardiac datasets demonstrate L2GNet's superiority over state-of-the-art methods, including the CDLS method SynergyNet, offering an novel approach to enhance deep learning models' performance in medical image analysis.
MotionAura: Generating High-Quality and Motion Consistent Videos using Discrete Diffusion
Oct 10, 2024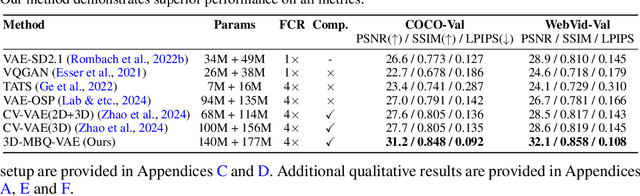
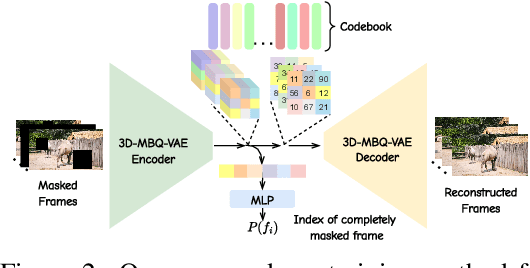
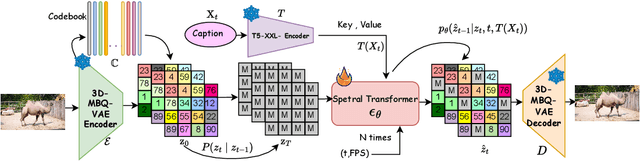
The spatio-temporal complexity of video data presents significant challenges in tasks such as compression, generation, and inpainting. We present four key contributions to address the challenges of spatiotemporal video processing. First, we introduce the 3D Mobile Inverted Vector-Quantization Variational Autoencoder (3D-MBQ-VAE), which combines Variational Autoencoders (VAEs) with masked token modeling to enhance spatiotemporal video compression. The model achieves superior temporal consistency and state-of-the-art (SOTA) reconstruction quality by employing a novel training strategy with full frame masking. Second, we present MotionAura, a text-to-video generation framework that utilizes vector-quantized diffusion models to discretize the latent space and capture complex motion dynamics, producing temporally coherent videos aligned with text prompts. Third, we propose a spectral transformer-based denoising network that processes video data in the frequency domain using the Fourier Transform. This method effectively captures global context and long-range dependencies for high-quality video generation and denoising. Lastly, we introduce a downstream task of Sketch Guided Video Inpainting. This task leverages Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning. Our models achieve SOTA performance on a range of benchmarks. Our work offers robust frameworks for spatiotemporal modeling and user-driven video content manipulation. We will release the code, datasets, and models in open-source.
Harmonized Spatial and Spectral Learning for Robust and Generalized Medical Image Segmentation
Jan 18, 2024



Deep learning has demonstrated remarkable achievements in medical image segmentation. However, prevailing deep learning models struggle with poor generalization due to (i) intra-class variations, where the same class appears differently in different samples, and (ii) inter-class independence, resulting in difficulties capturing intricate relationships between distinct objects, leading to higher false negative cases. This paper presents a novel approach that synergies spatial and spectral representations to enhance domain-generalized medical image segmentation. We introduce the innovative Spectral Correlation Coefficient objective to improve the model's capacity to capture middle-order features and contextual long-range dependencies. This objective complements traditional spatial objectives by incorporating valuable spectral information. Extensive experiments reveal that optimizing this objective with existing architectures like UNet and TransUNet significantly enhances generalization, interpretability, and noise robustness, producing more confident predictions. For instance, in cardiac segmentation, we observe a 0.81 pp and 1.63 pp (pp = percentage point) improvement in DSC over UNet and TransUNet, respectively. Our interpretability study demonstrates that, in most tasks, objectives optimized with UNet outperform even TransUNet by introducing global contextual information alongside local details. These findings underscore the versatility and effectiveness of our proposed method across diverse imaging modalities and medical domains.
TPFNet: A Novel Text In-painting Transformer for Text Removal
Oct 27, 2022
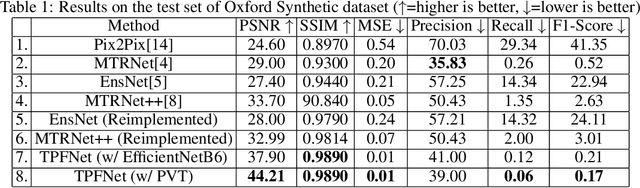

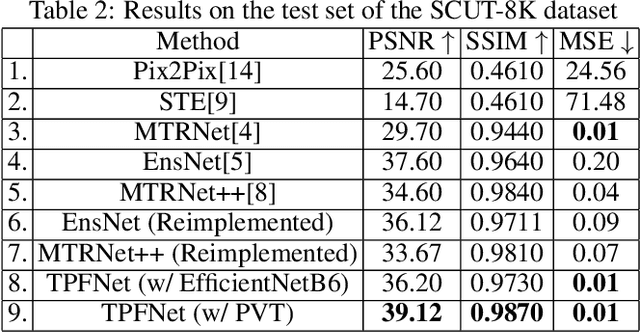
Text erasure from an image is helpful for various tasks such as image editing and privacy preservation. In this paper, we present TPFNet, a novel one-stage (end-toend) network for text removal from images. Our network has two parts: feature synthesis and image generation. Since noise can be more effectively removed from low-resolution images, part 1 operates on low-resolution images. The output of part 1 is a low-resolution text-free image. Part 2 uses the features learned in part 1 to predict a high-resolution text-free image. In part 1, we use "pyramidal vision transformer" (PVT) as the encoder. Further, we use a novel multi-headed decoder that generates a high-pass filtered image and a segmentation map, in addition to a text-free image. The segmentation branch helps locate the text precisely, and the high-pass branch helps in learning the image structure. To precisely locate the text, TPFNet employs an adversarial loss that is conditional on the segmentation map rather than the input image. On Oxford, SCUT, and SCUT-EnsText datasets, our network outperforms recently proposed networks on nearly all the metrics. For example, on SCUT-EnsText dataset, TPFNet has a PSNR (higher is better) of 39.0 and text-detection precision (lower is better) of 21.1, compared to the best previous technique, which has a PSNR of 32.3 and precision of 53.2. The source code can be obtained from https://github.com/CandleLabAI/TPFNet
Accelerating Gradient-based Meta Learner
Oct 27, 2021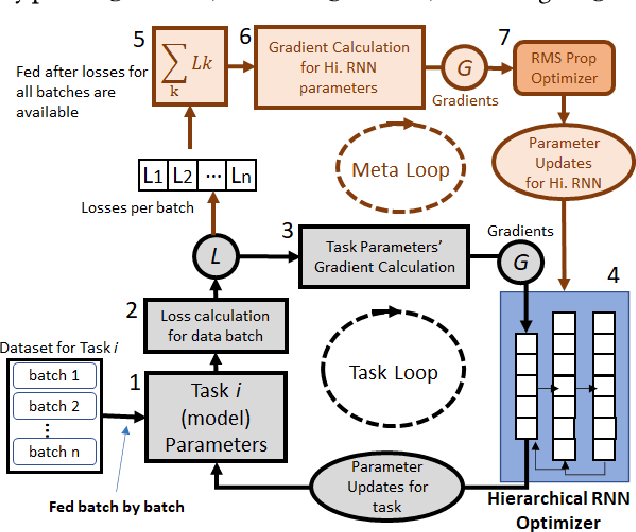

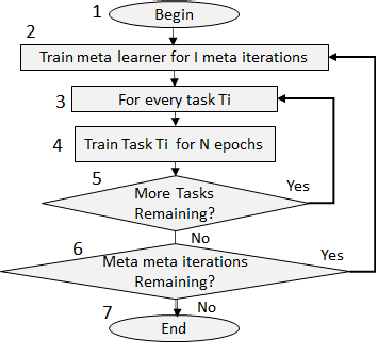
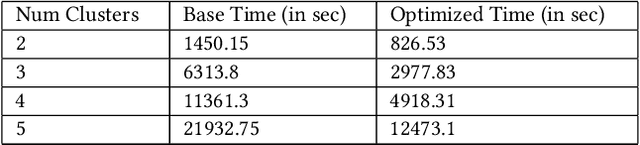
Meta Learning has been in focus in recent years due to the meta-learner model's ability to adapt well and generalize to new tasks, thus, reducing both the time and data requirements for learning. However, a major drawback of meta learner is that, to reach to a state from where learning new tasks becomes feasible with less data, it requires a large number of iterations and a lot of time. We address this issue by proposing various acceleration techniques to speed up meta learning algorithms such as MAML (Model Agnostic Meta Learning). We present 3.73X acceleration on a well known RNN optimizer based meta learner proposed in literature [11]. We introduce a novel method of training tasks in clusters, which not only accelerates the meta learning process but also improves model accuracy performance. Keywords: Meta learning, RNN optimizer, AGI, Performance optimization
Fast Online "Next Best Offers" using Deep Learning
May 31, 2019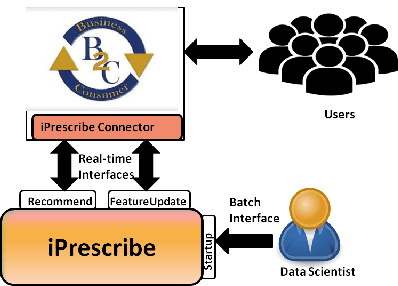
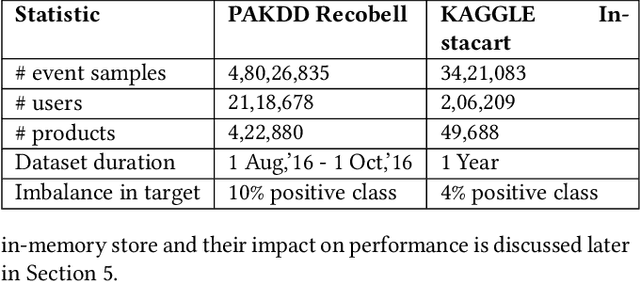
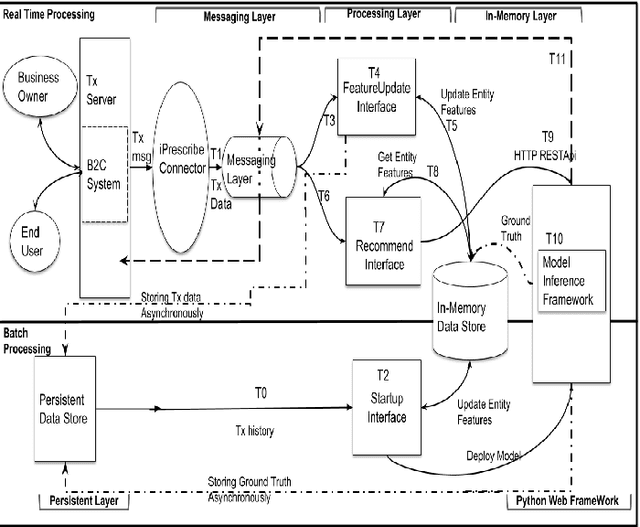
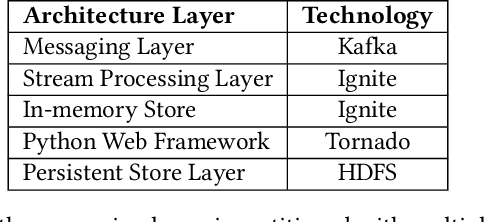
In this paper, we present iPrescribe, a scalable low-latency architecture for recommending 'next-best-offers' in an online setting. The paper presents the design of iPrescribe and compares its performance for implementations using different real-time streaming technology stacks. iPrescribe uses an ensemble of deep learning and machine learning algorithms for prediction. We describe the scalable real-time streaming technology stack and optimized machine-learning implementations to achieve a 90th percentile recommendation latency of 38 milliseconds. Optimizations include a novel mechanism to deploy recurrent Long Short Term Memory (LSTM) deep learning networks efficiently.
Polystore++: Accelerated Polystore System for Heterogeneous Workloads
May 24, 2019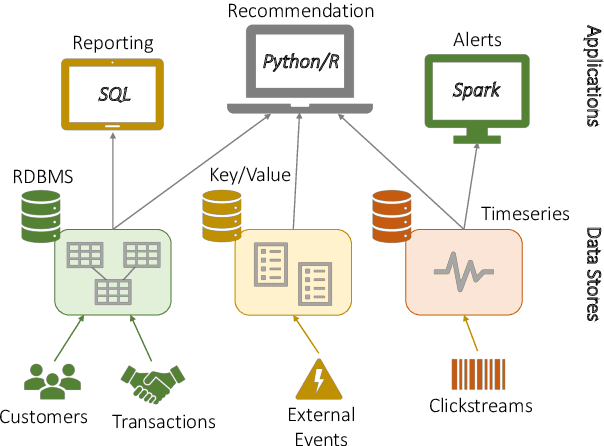
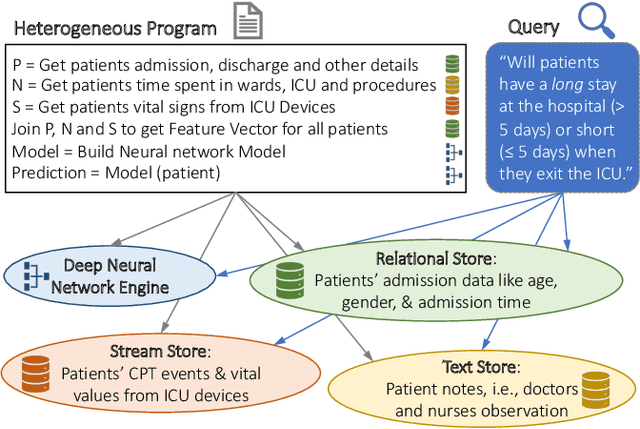
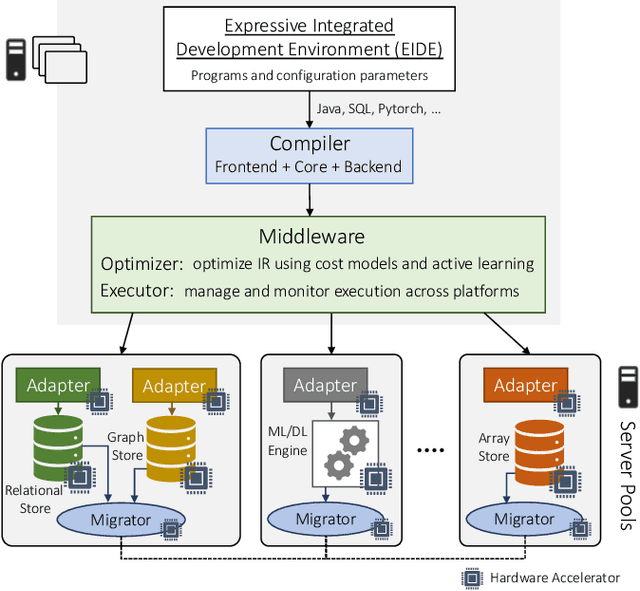
Modern real-time business analytic consist of heterogeneous workloads (e.g, database queries, graph processing, and machine learning). These analytic applications need programming environments that can capture all aspects of the constituent workloads (including data models they work on and movement of data across processing engines). Polystore systems suit such applications; however, these systems currently execute on CPUs and the slowdown of Moore's Law means they cannot meet the performance and efficiency requirements of modern workloads. We envision Polystore++, an architecture to accelerate existing polystore systems using hardware accelerators (e.g, FPGAs, CGRAs, and GPUs). Polystore++ systems can achieve high performance at low power by identifying and offloading components of a polystore system that are amenable to acceleration using specialized hardware. Building a Polystore++ system is challenging and introduces new research problems motivated by the use of hardware accelerators (e.g, optimizing and mapping query plans across heterogeneous computing units and exploiting hardware pipelining and parallelism to improve performance). In this paper, we discuss these challenges in detail and list possible approaches to address these problems.
* 11 pages, Accepted in ICDCS 2019