 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPSULE: Control-Theoretic Action Perturbations for Safe Uncertainty-Aware Reinforcement Learning
Apr 26, 2026Ensuring safe exploration in high-dimensional systems with unknown dynamics remains a significant challenge. Existing safe reinforcement learning methods often provide safety guarantees only in expectation, which can still lead to safety violations. Control-theoretic approaches, in contrast, offer hard constraint-based safety guarantees but typically assume access to known system dynamics or require accurate estimation of control-affine models. In this paper, we propose a safe reinforcement learning framework that learns a probabilistic control-affine dynamics model in an offline setting. The learned model is leveraged to explicitly construct control barrier functions (CBFs) that incorporate model uncertainty to provide conservative safety constraints. These CBF constraints are enforced through an online constraint-based action correction mechanism, enabling safe exploration without overly restricting task performance. Empirical evaluations on nonlinear, complex continuous-control benchmarks demonstrate that our approach achieves returns comparable to those of existing baselines while significantly reducing safety violations.
Suppressing Pink Elephants with Direct Principle Feedback
Feb 13, 2024Existing methods for controlling language models, such as RLHF and Constitutional AI, involve determining which LLM behaviors are desirable and training them into a language model. However, in many cases, it is desirable for LLMs to be controllable at inference time, so that they can be used in multiple contexts with diverse needs. We illustrate this with the Pink Elephant Problem: instructing an LLM to avoid discussing a certain entity (a ``Pink Elephant''), and instead discuss a preferred entity (``Grey Elephant''). We apply a novel simplification of Constitutional AI, Direct Principle Feedback, which skips the ranking of responses and uses DPO directly on critiques and revisions. Our results show that after DPF fine-tuning on our synthetic Pink Elephants dataset, our 13B fine-tuned LLaMA 2 model significantly outperforms Llama-2-13B-Chat and a prompted baseline, and performs as well as GPT-4 in on our curated test set assessing the Pink Elephant Problem.
OPT-R: Exploring the Role of Explanations in Finetuning and Prompting for Reasoning Skills of Large Language Models
May 19, 2023In this paper, we conduct a thorough investigation into the reasoning capabilities of Large Language Models (LLMs), focusing specifically on the Open Pretrained Transformers (OPT) models as a representative of such models. Our study entails finetuning three different sizes of OPT on a carefully curated reasoning corpus, resulting in two sets of finetuned models: OPT-R, finetuned without explanations, and OPT-RE, finetuned with explanations. We then evaluate all models on 57 out-of-domain tasks drawn from the SUPER-NATURALINSTRUCTIONS benchmark, covering 26 distinct reasoning skills, utilizing three prompting techniques. Through a comprehensive grid of 27 configurations and 6,156 test evaluations, we investigate the dimensions of finetuning, prompting, and scale to understand the role of explanations on different reasoning skills. Our findings reveal that having explanations in the fewshot exemplar has no significant impact on the model's performance when the model is finetuned, while positively affecting the non-finetuned counterpart. Moreover, we observe a slight yet consistent increase in classification accuracy as we incorporate explanations during prompting and finetuning, respectively. Finally, we offer insights on which skills benefit the most from incorporating explanations during finetuning and prompting, such as Numerical (+20.4%) and Analogical (+13.9%) reasoning, as well as skills that exhibit negligible or negative effects.
Uniform Masking Prevails in Vision-Language Pretraining
Dec 10, 2022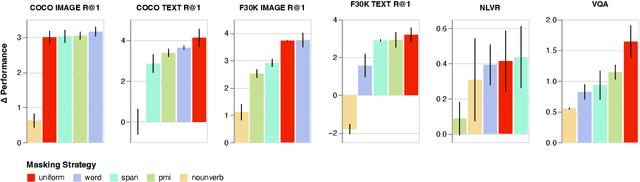


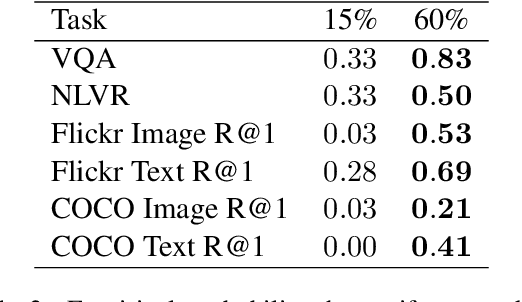
Masked Language Modeling (MLM) has proven to be an essential component of Vision-Language (VL) pretraining. To implement MLM, the researcher must make two design choices: the masking strategy, which determines which tokens to mask, and the masking rate, which determines how many tokens to mask. Previous work has focused primarily on the masking strategy while setting the masking rate at a default of 15\%. In this paper, we show that increasing this masking rate improves downstream performance while simultaneously reducing performance gap among different masking strategies, rendering the uniform masking strategy competitive to other more complex ones. Surprisingly, we also discover that increasing the masking rate leads to gains in Image-Text Matching (ITM) tasks, suggesting that the role of MLM goes beyond language modeling in VL pretraining.
CHAI: A CHatbot AI for Task-Oriented Dialogue with Offline Reinforcement Learning
Apr 18, 2022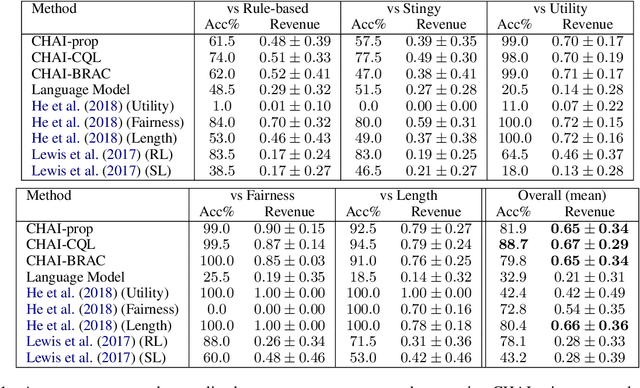


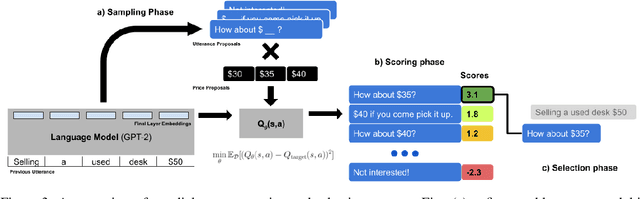
Conventionally, generation of natural language for dialogue agents may be viewed as a statistical learning problem: determine the patterns in human-provided data and generate appropriate responses with similar statistical properties. However, dialogue can also be regarded as a goal directed process, where speakers attempt to accomplish a specific task. Reinforcement learning (RL) algorithms are designed specifically for solving such goal-directed problems, but the most direct way to apply RL -- through trial-and-error learning in human conversations, -- is costly. In this paper, we study how offline reinforcement learning can instead be used to train dialogue agents entirely using static datasets collected from human speakers. Our experiments show that recently developed offline RL methods can be combined with language models to yield realistic dialogue agents that better accomplish task goals.
Continual Learning of Control Primitives: Skill Discovery via Reset-Games
Nov 10, 2020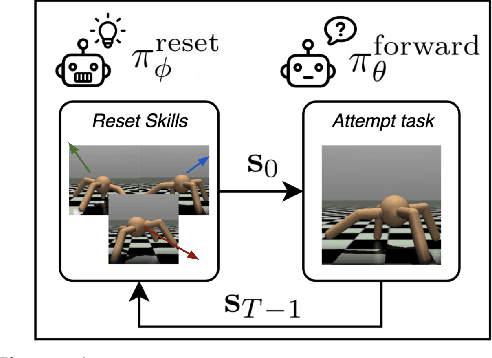
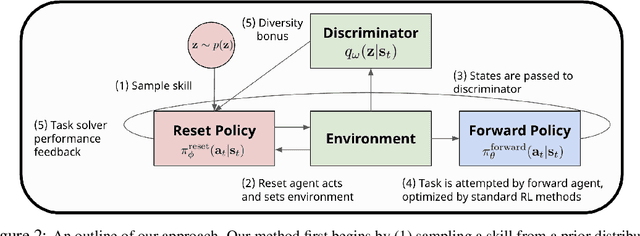

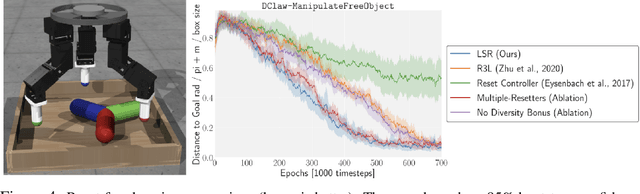
Reinforcement learning has the potential to automate the acquisition of behavior in complex settings, but in order for it to be successfully deployed, a number of practical challenges must be addressed. First, in real world settings, when an agent attempts a task and fails, the environment must somehow "reset" so that the agent can attempt the task again. While easy in simulation, this could require considerable human effort in the real world, especially if the number of trials is very large. Second, real world learning often involves complex, temporally extended behavior that is often difficult to acquire with random exploration. While these two problems may at first appear unrelated, in this work, we show how a single method can allow an agent to acquire skills with minimal supervision while removing the need for resets. We do this by exploiting the insight that the need to "reset" an agent to a broad set of initial states for a learning task provides a natural setting to learn a diverse set of "reset-skills". We propose a general-sum game formulation that balances the objectives of resetting and learning skills, and demonstrate that this approach improves performance on reset-free tasks, and additionally show that the skills we obtain can be used to significantly accelerate downstream learning.
Fast Online "Next Best Offers" using Deep Learning
May 31, 2019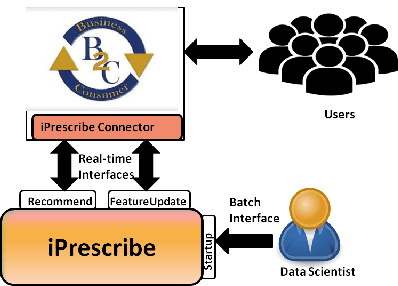
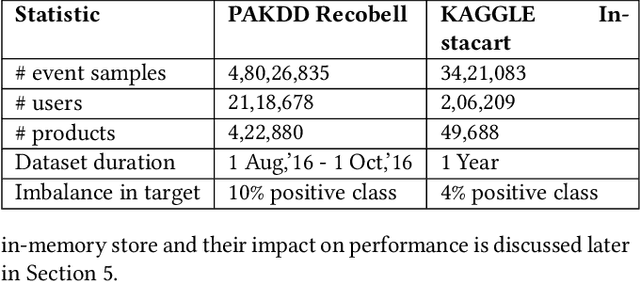
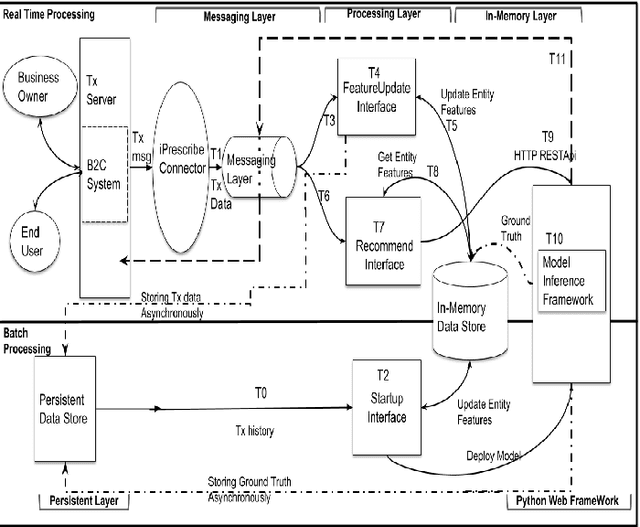
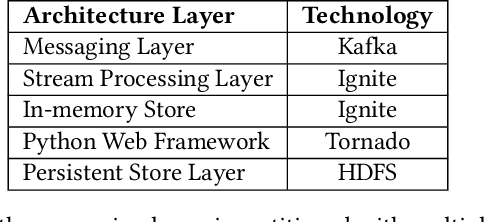
In this paper, we present iPrescribe, a scalable low-latency architecture for recommending 'next-best-offers' in an online setting. The paper presents the design of iPrescribe and compares its performance for implementations using different real-time streaming technology stacks. iPrescribe uses an ensemble of deep learning and machine learning algorithms for prediction. We describe the scalable real-time streaming technology stack and optimized machine-learning implementations to achieve a 90th percentile recommendation latency of 38 milliseconds. Optimizations include a novel mechanism to deploy recurrent Long Short Term Memory (LSTM) deep learning networks efficiently.