 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKCoEvo: A Knowledge Graph Augmented Framework for Evolutionary Code Generation
Mar 08, 2026Code evolution is inevitable in modern software development. Changes to third-party APIs frequently break existing code and complicate maintenance, posing practical challenges for developers. While large language models (LLMs) have shown promise in code generation, they struggle to reason without a structured representation of these evolving relationships, often leading them to produce outdated APIs or invalid outputs. In this work, we propose a knowledge graph-augmented framework that decomposes the migration task into two synergistic stages: evolution path retrieval and path-informed code generation. Our approach constructs static and dynamic API graphs to model intra-version structures and cross-version transitions, enabling structured reasoning over API evolution. Both modules are trained with synthetic supervision automatically derived from real-world API diffs, ensuring scalability and minimal human effort. Extensive experiments across single-package and multi-package benchmarks demonstrate that our framework significantly improves migration accuracy, controllability, and execution success over standard LLM baselines. The source code and datasets are available at: https://github.com/kangjz1203/KCoEvo.
Scaling Reinforcement Learning for Content Moderation with Large Language Models
Dec 23, 2025
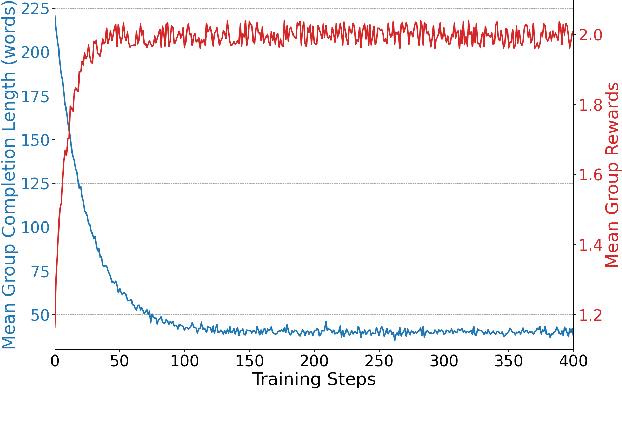
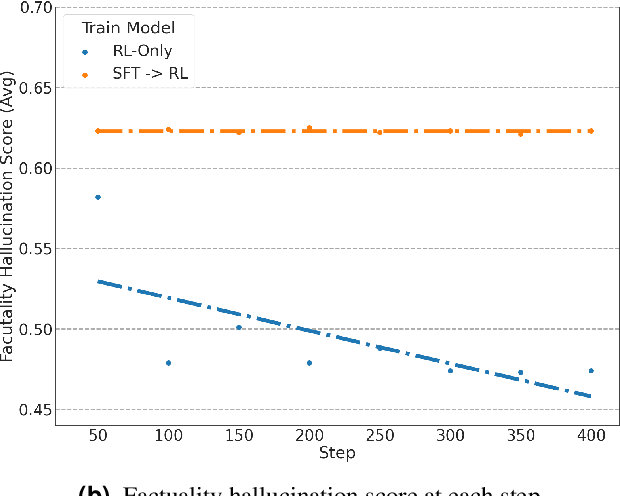
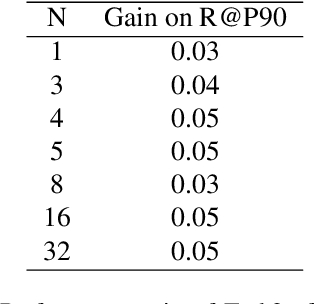
Content moderation at scale remains one of the most pressing challenges in today's digital ecosystem, where billions of user- and AI-generated artifacts must be continuously evaluated for policy violations. Although recent advances in large language models (LLMs) have demonstrated strong potential for policy-grounded moderation, the practical challenges of training these systems to achieve expert-level accuracy in real-world settings remain largely unexplored, particularly in regimes characterized by label sparsity, evolving policy definitions, and the need for nuanced reasoning beyond shallow pattern matching. In this work, we present a comprehensive empirical investigation of scaling reinforcement learning (RL) for content classification, systematically evaluating multiple RL training recipes and reward-shaping strategies-including verifiable rewards and LLM-as-judge frameworks-to transform general-purpose language models into specialized, policy-aligned classifiers across three real-world content moderation tasks. Our findings provide actionable insights for industrial-scale moderation systems, demonstrating that RL exhibits sigmoid-like scaling behavior in which performance improves smoothly with increased training data, rollouts, and optimization steps before gradually saturating. Moreover, we show that RL substantially improves performance on tasks requiring complex policy-grounded reasoning while achieving up to 100x higher data efficiency than supervised fine-tuning, making it particularly effective in domains where expert annotations are scarce or costly.
StatEval: A Comprehensive Benchmark for Large Language Models in Statistics
Oct 10, 2025Large language models (LLMs) have demonstrated remarkable advances in mathematical and logical reasoning, yet statistics, as a distinct and integrative discipline, remains underexplored in benchmarking efforts. To address this gap, we introduce \textbf{StatEval}, the first comprehensive benchmark dedicated to statistics, spanning both breadth and depth across difficulty levels. StatEval consists of 13,817 foundational problems covering undergraduate and graduate curricula, together with 2374 research-level proof tasks extracted from leading journals. To construct the benchmark, we design a scalable multi-agent pipeline with human-in-the-loop validation that automates large-scale problem extraction, rewriting, and quality control, while ensuring academic rigor. We further propose a robust evaluation framework tailored to both computational and proof-based tasks, enabling fine-grained assessment of reasoning ability. Experimental results reveal that while closed-source models such as GPT5-mini achieve below 57\% on research-level problems, with open-source models performing significantly lower. These findings highlight the unique challenges of statistical reasoning and the limitations of current LLMs. We expect StatEval to serve as a rigorous benchmark for advancing statistical intelligence in large language models. All data and code are available on our web platform: https://stateval.github.io/.
Hierarchical Image Matching for UAV Absolute Visual Localization via Semantic and Structural Constraints
Jun 11, 2025

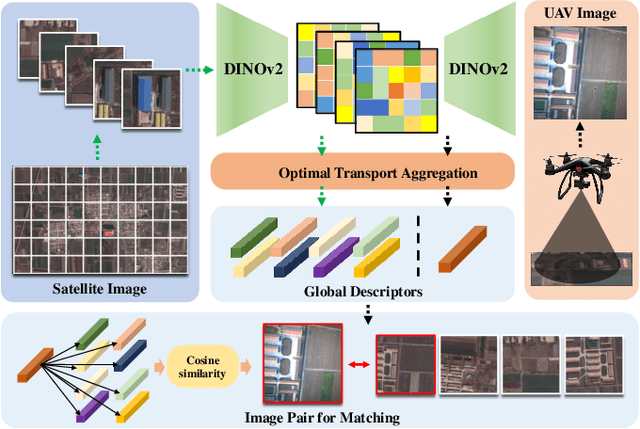

Absolute localization, aiming to determine an agent's location with respect to a global reference, is crucial for unmanned aerial vehicles (UAVs) in various applications, but it becomes challenging when global navigation satellite system (GNSS) signals are unavailable. Vision-based absolute localization methods, which locate the current view of the UAV in a reference satellite map to estimate its position, have become popular in GNSS-denied scenarios. However, existing methods mostly rely on traditional and low-level image matching, suffering from difficulties due to significant differences introduced by cross-source discrepancies and temporal variations. To overcome these limitations, in this paper, we introduce a hierarchical cross-source image matching method designed for UAV absolute localization, which integrates a semantic-aware and structure-constrained coarse matching module with a lightweight fine-grained matching module. Specifically, in the coarse matching module, semantic features derived from a vision foundation model first establish region-level correspondences under semantic and structural constraints. Then, the fine-grained matching module is applied to extract fine features and establish pixel-level correspondences. Building upon this, a UAV absolute visual localization pipeline is constructed without any reliance on relative localization techniques, mainly by employing an image retrieval module before the proposed hierarchical image matching modules. Experimental evaluations on public benchmark datasets and a newly introduced CS-UAV dataset demonstrate superior accuracy and robustness of the proposed method under various challenging conditions, confirming its effectiveness.
Estimating quantum relative entropies on quantum computers
Jan 13, 2025



Quantum relative entropy, a quantum generalization of the well-known Kullback-Leibler divergence, serves as a fundamental measure of the distinguishability between quantum states and plays a pivotal role in quantum information science. Despite its importance, efficiently estimating quantum relative entropy between two quantum states on quantum computers remains a significant challenge. In this work, we propose the first quantum algorithm for estimating quantum relative entropy and Petz R\'{e}nyi divergence from two unknown quantum states on quantum computers, addressing open problems highlighted in [Phys. Rev. A 109, 032431 (2024)] and [IEEE Trans. Inf. Theory 70, 5653-5680 (2024)]. This is achieved by combining quadrature approximations of relative entropies, the variational representation of quantum f-divergences, and a new technique for parameterizing Hermitian polynomial operators to estimate their traces with quantum states. Notably, the circuit size of our algorithm is at most 2n+1 with n being the number of qubits in the quantum states and it is directly applicable to distributed scenarios, where quantum states to be compared are hosted on cross-platform quantum computers. We validate our algorithm through numerical simulations, laying the groundwork for its future deployment on quantum hardware devices.
Quantum Langevin Dynamics for Optimization
Nov 27, 2023We initiate the study of utilizing Quantum Langevin Dynamics (QLD) to solve optimization problems, particularly those non-convex objective functions that present substantial obstacles for traditional gradient descent algorithms. Specifically, we examine the dynamics of a system coupled with an infinite heat bath. This interaction induces both random quantum noise and a deterministic damping effect to the system, which nudge the system towards a steady state that hovers near the global minimum of objective functions. We theoretically prove the convergence of QLD in convex landscapes, demonstrating that the average energy of the system can approach zero in the low temperature limit with an exponential decay rate correlated with the evolution time. Numerically, we first show the energy dissipation capability of QLD by retracing its origins to spontaneous emission. Furthermore, we conduct detailed discussion of the impact of each parameter. Finally, based on the observations when comparing QLD with classical Fokker-Plank-Smoluchowski equation, we propose a time-dependent QLD by making temperature and $\hbar$ time-dependent parameters, which can be theoretically proven to converge better than the time-independent case and also outperforms a series of state-of-the-art quantum and classical optimization algorithms in many non-convex landscapes.
Hyper-Decision Transformer for Efficient Online Policy Adaptation
Apr 17, 2023Decision Transformers (DT) have demonstrated strong performances in offline reinforcement learning settings, but quickly adapting to unseen novel tasks remains challenging. To address this challenge, we propose a new framework, called Hyper-Decision Transformer (HDT), that can generalize to novel tasks from a handful of demonstrations in a data- and parameter-efficient manner. To achieve such a goal, we propose to augment the base DT with an adaptation module, whose parameters are initialized by a hyper-network. When encountering unseen tasks, the hyper-network takes a handful of demonstrations as inputs and initializes the adaptation module accordingly. This initialization enables HDT to efficiently adapt to novel tasks by only fine-tuning the adaptation module. We validate HDT's generalization capability on object manipulation tasks. We find that with a single expert demonstration and fine-tuning only 0.5% of DT parameters, HDT adapts faster to unseen tasks than fine-tuning the whole DT model. Finally, we explore a more challenging setting where expert actions are not available, and we show that HDT outperforms state-of-the-art baselines in terms of task success rates by a large margin.
Uniform Masking Prevails in Vision-Language Pretraining
Dec 10, 2022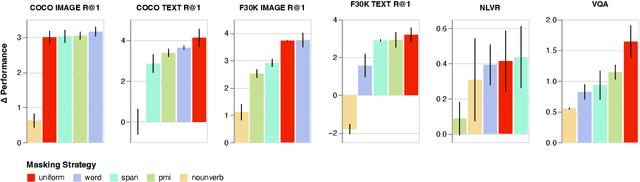


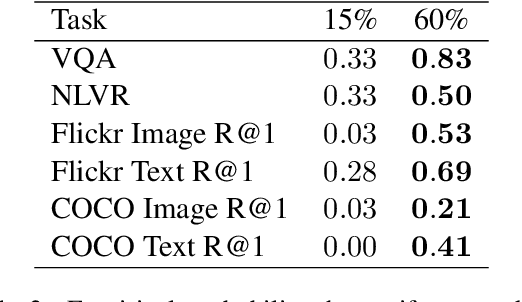
Masked Language Modeling (MLM) has proven to be an essential component of Vision-Language (VL) pretraining. To implement MLM, the researcher must make two design choices: the masking strategy, which determines which tokens to mask, and the masking rate, which determines how many tokens to mask. Previous work has focused primarily on the masking strategy while setting the masking rate at a default of 15\%. In this paper, we show that increasing this masking rate improves downstream performance while simultaneously reducing performance gap among different masking strategies, rendering the uniform masking strategy competitive to other more complex ones. Surprisingly, we also discover that increasing the masking rate leads to gains in Image-Text Matching (ITM) tasks, suggesting that the role of MLM goes beyond language modeling in VL pretraining.
Prompting Decision Transformer for Few-Shot Policy Generalization
Jun 27, 2022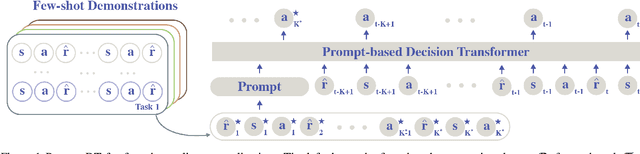
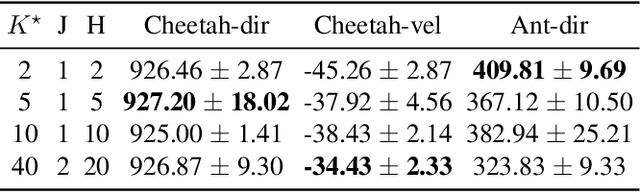
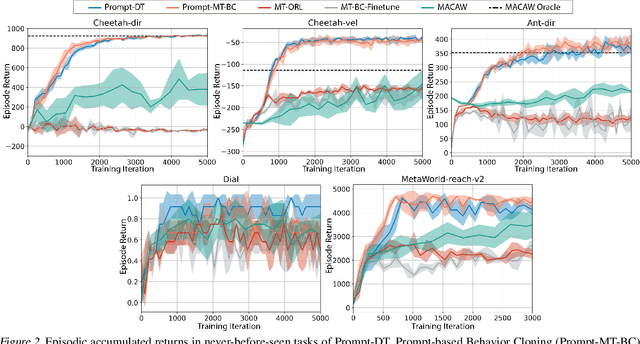
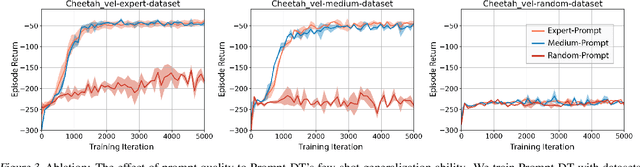
Humans can leverage prior experience and learn novel tasks from a handful of demonstrations. In contrast to offline meta-reinforcement learning, which aims to achieve quick adaptation through better algorithm design, we investigate the effect of architecture inductive bias on the few-shot learning capability. We propose a Prompt-based Decision Transformer (Prompt-DT), which leverages the sequential modeling ability of the Transformer architecture and the prompt framework to achieve few-shot adaptation in offline RL. We design the trajectory prompt, which contains segments of the few-shot demonstrations, and encodes task-specific information to guide policy generation. Our experiments in five MuJoCo control benchmarks show that Prompt-DT is a strong few-shot learner without any extra finetuning on unseen target tasks. Prompt-DT outperforms its variants and strong meta offline RL baselines by a large margin with a trajectory prompt containing only a few timesteps. Prompt-DT is also robust to prompt length changes and can generalize to out-of-distribution (OOD) environments.
Expressiveness and Learnability: A Unifying View for Evaluating Self-Supervised Learning
Jun 02, 2022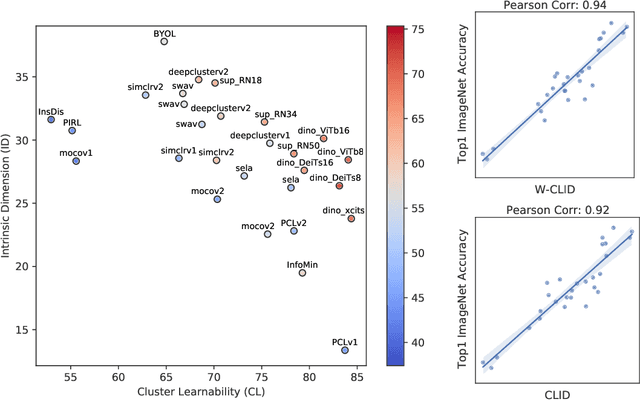
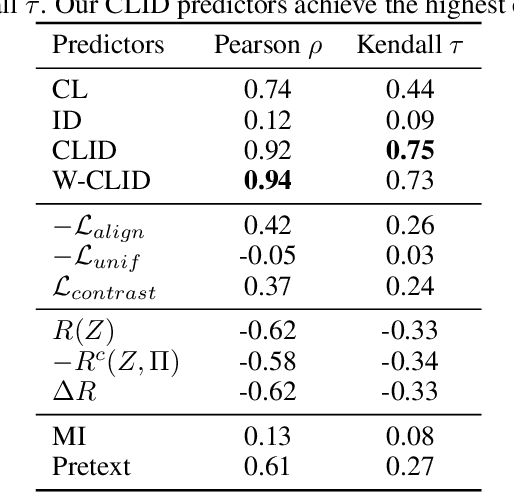
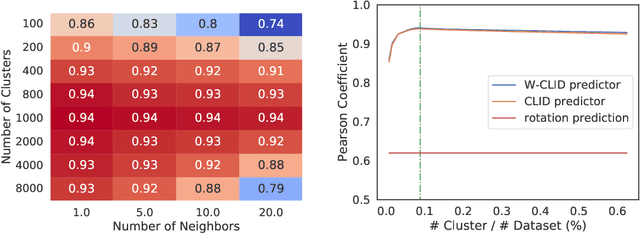
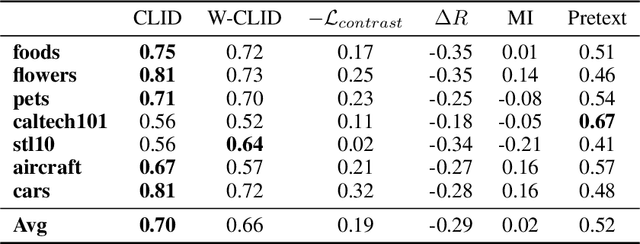
We propose a unifying view to analyze the representation quality of self-supervised learning (SSL) models without access to supervised labels, while being agnostic to the architecture, learning algorithm or data manipulation used during training. We argue that representations can be evaluated through the lens of expressiveness and learnability. We propose to use the Intrinsic Dimension (ID) to assess expressiveness and introduce Cluster Learnability (CL) to assess learnability. CL is measured as the learning speed of a KNN classifier trained to predict labels obtained by clustering the representations with K-means. We thus combine CL and ID into a single predictor: CLID. Through a large-scale empirical study with a diverse family of SSL algorithms, we find that CLID better correlates with in-distribution model performance than other competing recent evaluation schemes. We also benchmark CLID on out-of-domain generalization, where CLID serves as a predictor of the transfer performance of SSL models on several classification tasks, yielding improvements with respect to the competing baselines.