 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForget Sharpness: Perturbed Forgetting of Model Biases Within SAM Dynamics
Jun 10, 2024Despite attaining high empirical generalization, the sharpness of models trained with sharpness-aware minimization (SAM) do not always correlate with generalization error. Instead of viewing SAM as minimizing sharpness to improve generalization, our paper considers a new perspective based on SAM's training dynamics. We propose that perturbations in SAM perform perturbed forgetting, where they discard undesirable model biases to exhibit learning signals that generalize better. We relate our notion of forgetting to the information bottleneck principle, use it to explain observations like the better generalization of smaller perturbation batches, and show that perturbed forgetting can exhibit a stronger correlation with generalization than flatness. While standard SAM targets model biases exposed by the steepest ascent directions, we propose a new perturbation that targets biases exposed through the model's outputs. Our output bias forgetting perturbations outperform standard SAM, GSAM, and ASAM on ImageNet, robustness benchmarks, and transfer to CIFAR-{10,100}, while sometimes converging to sharper regions. Our results suggest that the benefits of SAM can be explained by alternative mechanistic principles that do not require flatness of the loss surface.
SPARO: Selective Attention for Robust and Compositional Transformer Encodings for Vision
Apr 24, 2024



Selective attention helps us focus on task-relevant aspects in the constant flood of our sensory input. This constraint in our perception allows us to robustly generalize under distractions and to new compositions of perceivable concepts. Transformers employ a similar notion of attention in their architecture, but representation learning models with transformer backbones like CLIP and DINO often fail to demonstrate robustness and compositionality. We highlight a missing architectural prior: unlike human perception, transformer encodings do not separately attend over individual concepts. In response, we propose SPARO, a read-out mechanism that partitions encodings into separately-attended slots, each produced by a single attention head. Using SPARO with CLIP imparts an inductive bias that the vision and text modalities are different views of a shared compositional world with the same corresponding concepts. Using SPARO, we demonstrate improvements on downstream recognition, robustness, retrieval, and compositionality benchmarks with CLIP (up to +14% for ImageNet, +4% for SugarCrepe), and on nearest neighbors and linear probe for ImageNet with DINO (+3% each). We also showcase a powerful ability to intervene and select individual SPARO concepts to further improve downstream task performance (up from +4% to +9% for SugarCrepe) and use this ability to study the robustness of SPARO's representation structure. Finally, we provide insights through ablation experiments and visualization of learned concepts.
On the Compositional Generalization Gap of In-Context Learning
Nov 15, 2022Pretrained large generative language models have shown great performance on many tasks, but exhibit low compositional generalization abilities. Scaling such models has been shown to improve their performance on various NLP tasks even just by conditioning them on a few examples to solve the task without any fine-tuning (also known as in-context learning). In this work, we look at the gap between the in-distribution (ID) and out-of-distribution (OOD) performance of such models in semantic parsing tasks with in-context learning. In the ID settings, the demonstrations are from the same split (test or train) that the model is being evaluated on, and in the OOD settings, they are from the other split. We look at how the relative generalization gap of in-context learning evolves as models are scaled up. We evaluate four model families, OPT, BLOOM, CodeGen and Codex on three semantic parsing datasets, CFQ, SCAN and GeoQuery with different number of exemplars, and observe a trend of decreasing relative generalization gap as models are scaled up.
Simplicial Embeddings in Self-Supervised Learning and Downstream Classification
Apr 01, 2022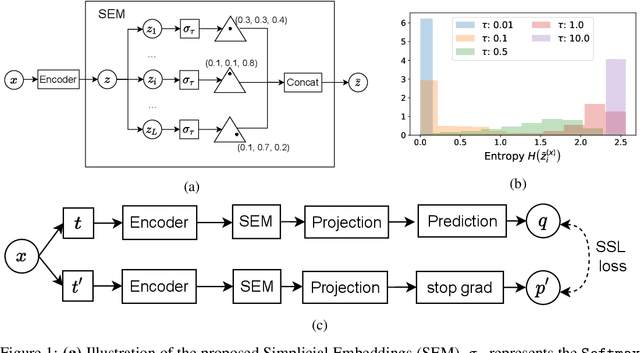

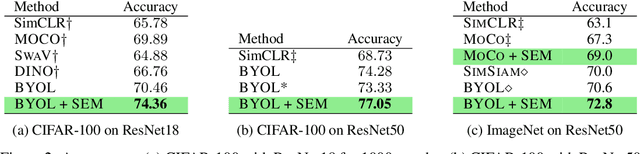
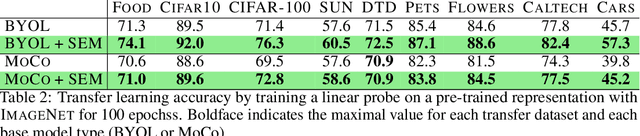
We introduce Simplicial Embeddings (SEMs) as a way to constrain the encoded representations of a self-supervised model to $L$ simplices of $V$ dimensions each using a Softmax operation. This procedure imposes a structure on the representations that reduce their expressivity for training downstream classifiers, which helps them generalize better. Specifically, we show that the temperature $\tau$ of the Softmax operation controls for the SEM representation's expressivity, allowing us to derive a tighter downstream classifier generalization bound than that for classifiers using unnormalized representations. We empirically demonstrate that SEMs considerably improve generalization on natural image datasets such as CIFAR-100 and ImageNet. Finally, we also present evidence of the emergence of semantically relevant features in SEMs, a pattern that is absent from baseline self-supervised models.
Fortuitous Forgetting in Connectionist Networks
Feb 01, 2022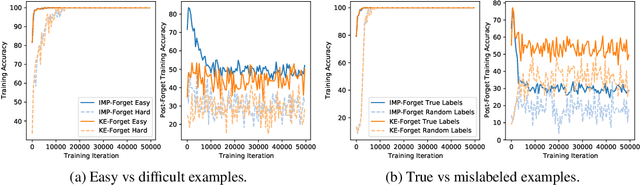
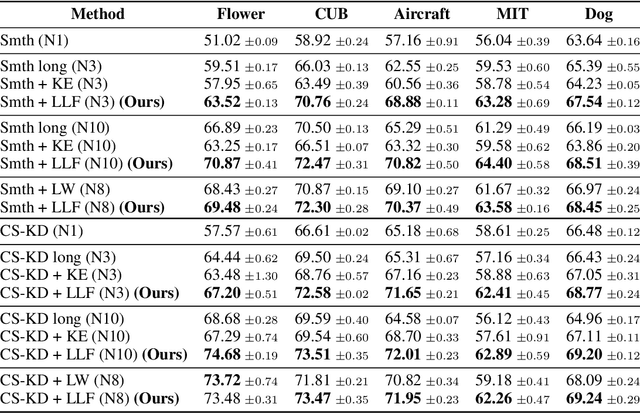
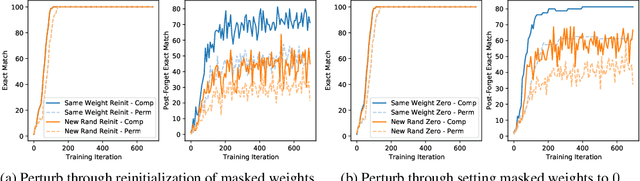
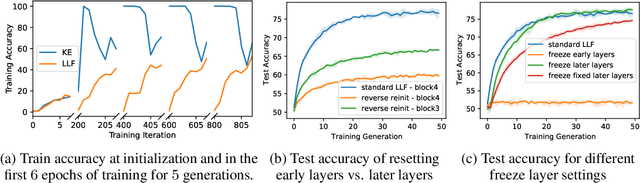
Forgetting is often seen as an unwanted characteristic in both human and machine learning. However, we propose that forgetting can in fact be favorable to learning. We introduce "forget-and-relearn" as a powerful paradigm for shaping the learning trajectories of artificial neural networks. In this process, the forgetting step selectively removes undesirable information from the model, and the relearning step reinforces features that are consistently useful under different conditions. The forget-and-relearn framework unifies many existing iterative training algorithms in the image classification and language emergence literature, and allows us to understand the success of these algorithms in terms of the disproportionate forgetting of undesirable information. We leverage this understanding to improve upon existing algorithms by designing more targeted forgetting operations. Insights from our analysis provide a coherent view on the dynamics of iterative training in neural networks and offer a clear path towards performance improvements.
* ICLR Camera Ready
Iterated learning for emergent systematicity in VQA
May 03, 2021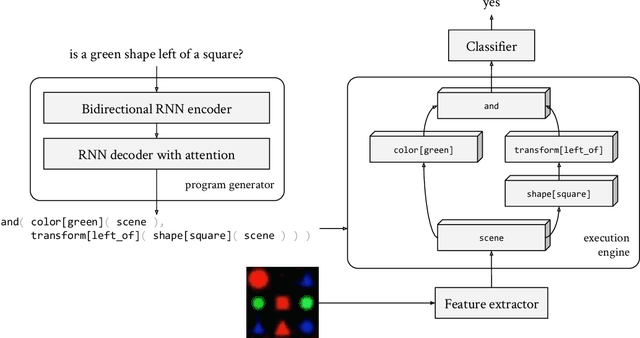
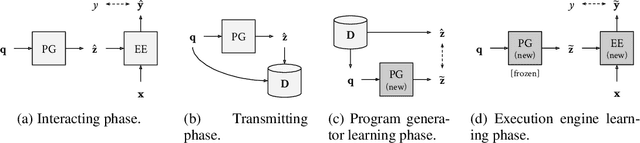
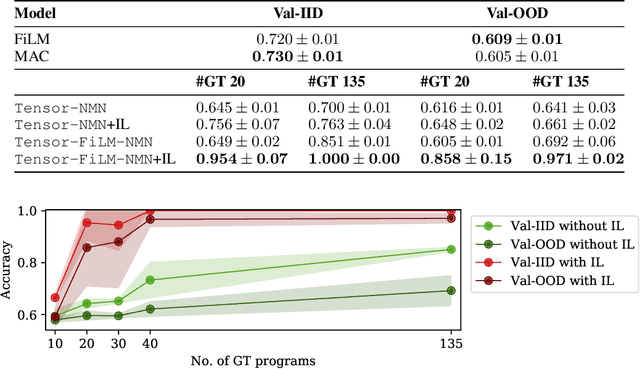

Although neural module networks have an architectural bias towards compositionality, they require gold standard layouts to generalize systematically in practice. When instead learning layouts and modules jointly, compositionality does not arise automatically and an explicit pressure is necessary for the emergence of layouts exhibiting the right structure. We propose to address this problem using iterated learning, a cognitive science theory of the emergence of compositional languages in nature that has primarily been applied to simple referential games in machine learning. Considering the layouts of module networks as samples from an emergent language, we use iterated learning to encourage the development of structure within this language. We show that the resulting layouts support systematic generalization in neural agents solving the more complex task of visual question-answering. Our regularized iterated learning method can outperform baselines without iterated learning on SHAPES-SyGeT (SHAPES Systematic Generalization Test), a new split of the SHAPES dataset we introduce to evaluate systematic generalization, and on CLOSURE, an extension of CLEVR also designed to test systematic generalization. We demonstrate superior performance in recovering ground-truth compositional program structure with limited supervision on both SHAPES-SyGeT and CLEVR.
GEAR: Geometry-Aware Rényi Information
Jun 19, 2019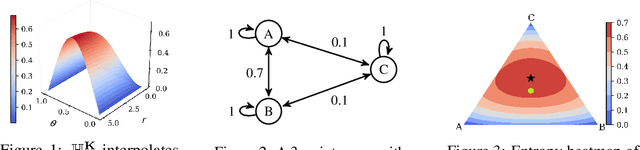


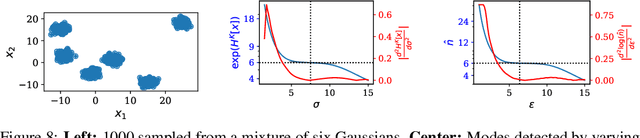
Shannon's seminal theory of information has been of paramount importance in the development of modern machine learning techniques. However, standard information measures deal with probability distributions over an alphabet considered as a mere set of symbols and disregard further geometric structure, which might be available in the form of a metric or similarity function. We advocate the use of a notion of entropy that reflects not only the relative abundances of symbols but also the similarities between them, which was originally introduced in theoretical ecology to study the diversity of biological communities. Echoing this idea, we propose a criterion for comparing two probability distributions (possibly degenerate and with non-overlapping supports) that takes into account the geometry of the space in which the distributions are defined. Our proposal exhibits performance on par with state-of-the-art methods based on entropy-regularized optimal transport, but enjoys a closed-form expression and thus a lower computational cost. We demonstrate the versatility of our proposal via experiments on a broad range of domains: computing image barycenters, approximating densities with a collection of (super-) samples; summarizing texts; assessing mode coverage; as well as training generative models.
Grounded Recurrent Neural Networks
May 23, 2017



In this work, we present the Grounded Recurrent Neural Network (GRNN), a recurrent neural network architecture for multi-label prediction which explicitly ties labels to specific dimensions of the recurrent hidden state (we call this process "grounding"). The approach is particularly well-suited for extracting large numbers of concepts from text. We apply the new model to address an important problem in healthcare of understanding what medical concepts are discussed in clinical text. Using a publicly available dataset derived from Intensive Care Units, we learn to label a patient's diagnoses and procedures from their discharge summary. Our evaluation shows a clear advantage to using our proposed architecture over a variety of strong baselines.