 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForget Sharpness: Perturbed Forgetting of Model Biases Within SAM Dynamics
Jun 10, 2024Despite attaining high empirical generalization, the sharpness of models trained with sharpness-aware minimization (SAM) do not always correlate with generalization error. Instead of viewing SAM as minimizing sharpness to improve generalization, our paper considers a new perspective based on SAM's training dynamics. We propose that perturbations in SAM perform perturbed forgetting, where they discard undesirable model biases to exhibit learning signals that generalize better. We relate our notion of forgetting to the information bottleneck principle, use it to explain observations like the better generalization of smaller perturbation batches, and show that perturbed forgetting can exhibit a stronger correlation with generalization than flatness. While standard SAM targets model biases exposed by the steepest ascent directions, we propose a new perturbation that targets biases exposed through the model's outputs. Our output bias forgetting perturbations outperform standard SAM, GSAM, and ASAM on ImageNet, robustness benchmarks, and transfer to CIFAR-{10,100}, while sometimes converging to sharper regions. Our results suggest that the benefits of SAM can be explained by alternative mechanistic principles that do not require flatness of the loss surface.
Domain Generalization via Semi-supervised Meta Learning
Sep 30, 2020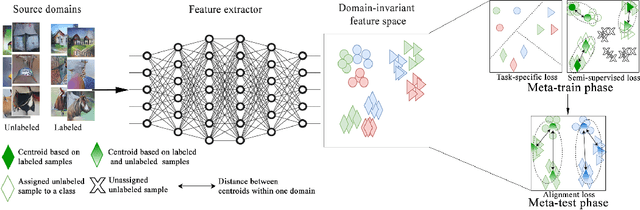
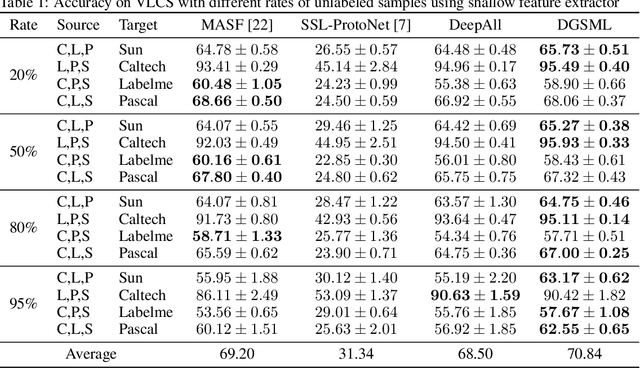
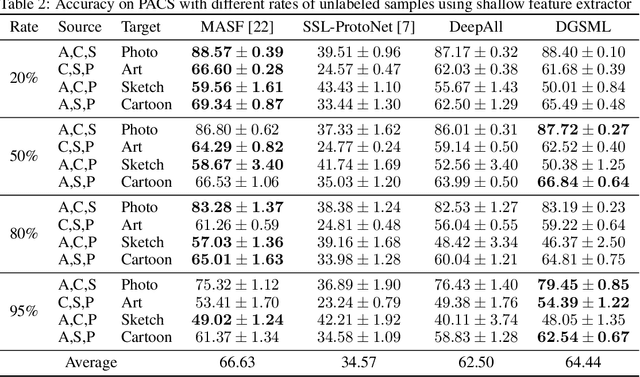
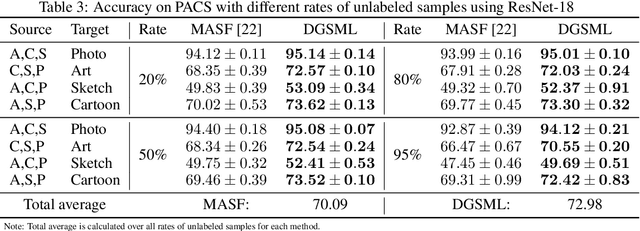
The goal of domain generalization is to learn from multiple source domains to generalize to unseen target domains under distribution discrepancy. Current state-of-the-art methods in this area are fully supervised, but for many real-world problems it is hardly possible to obtain enough labeled samples. In this paper, we propose the first method of domain generalization to leverage unlabeled samples, combining of meta learning's episodic training and semi-supervised learning, called DGSML. DGSML employs an entropy-based pseudo-labeling approach to assign labels to unlabeled samples and then utilizes a novel discrepancy loss to ensure that class centroids before and after labeling unlabeled samples are close to each other. To learn a domain-invariant representation, it also utilizes a novel alignment loss to ensure that the distance between pairs of class centroids, computed after adding the unlabeled samples, is preserved across different domains. DGSML is trained by a meta learning approach to mimic the distribution shift between the input source domains and unseen target domains. Experimental results on benchmark datasets indicate that DGSML outperforms state-of-the-art domain generalization and semi-supervised learning methods.