 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Discrete Latent Code for High Fidelity, Productive Diffusion Models
Jul 16, 2025We argue that diffusion models' success in modeling complex distributions is, for the most part, coming from their input conditioning. This paper investigates the representation used to condition diffusion models from the perspective that ideal representations should improve sample fidelity, be easy to generate, and be compositional to allow out-of-training samples generation. We introduce Discrete Latent Code (DLC), an image representation derived from Simplicial Embeddings trained with a self-supervised learning objective. DLCs are sequences of discrete tokens, as opposed to the standard continuous image embeddings. They are easy to generate and their compositionality enables sampling of novel images beyond the training distribution. Diffusion models trained with DLCs have improved generation fidelity, establishing a new state-of-the-art for unconditional image generation on ImageNet. Additionally, we show that composing DLCs allows the image generator to produce out-of-distribution samples that coherently combine the semantics of images in diverse ways. Finally, we showcase how DLCs can enable text-to-image generation by leveraging large-scale pretrained language models. We efficiently finetune a text diffusion language model to generate DLCs that produce novel samples outside of the image generator training distribution.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Apr 30, 2024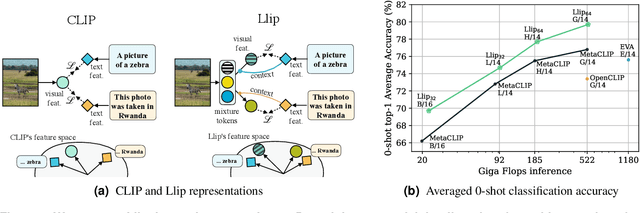
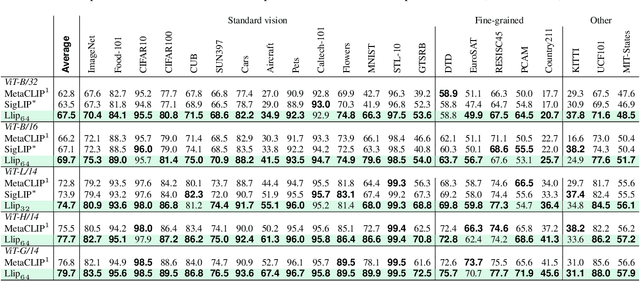
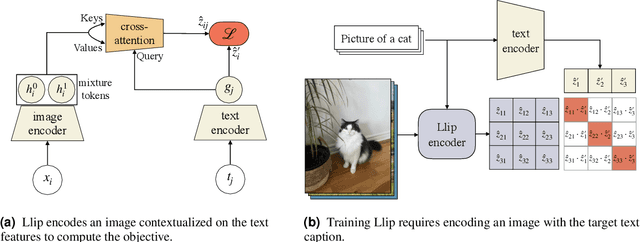
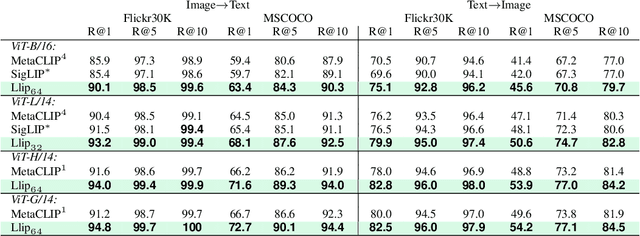
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
SPARO: Selective Attention for Robust and Compositional Transformer Encodings for Vision
Apr 24, 2024



Selective attention helps us focus on task-relevant aspects in the constant flood of our sensory input. This constraint in our perception allows us to robustly generalize under distractions and to new compositions of perceivable concepts. Transformers employ a similar notion of attention in their architecture, but representation learning models with transformer backbones like CLIP and DINO often fail to demonstrate robustness and compositionality. We highlight a missing architectural prior: unlike human perception, transformer encodings do not separately attend over individual concepts. In response, we propose SPARO, a read-out mechanism that partitions encodings into separately-attended slots, each produced by a single attention head. Using SPARO with CLIP imparts an inductive bias that the vision and text modalities are different views of a shared compositional world with the same corresponding concepts. Using SPARO, we demonstrate improvements on downstream recognition, robustness, retrieval, and compositionality benchmarks with CLIP (up to +14% for ImageNet, +4% for SugarCrepe), and on nearest neighbors and linear probe for ImageNet with DINO (+3% each). We also showcase a powerful ability to intervene and select individual SPARO concepts to further improve downstream task performance (up from +4% to +9% for SugarCrepe) and use this ability to study the robustness of SPARO's representation structure. Finally, we provide insights through ablation experiments and visualization of learned concepts.
Language Model Alignment with Elastic Reset
Dec 06, 2023Finetuning language models with reinforcement learning (RL), e.g. from human feedback (HF), is a prominent method for alignment. But optimizing against a reward model can improve on reward while degrading performance in other areas, a phenomenon known as reward hacking, alignment tax, or language drift. First, we argue that commonly-used test metrics are insufficient and instead measure how different algorithms tradeoff between reward and drift. The standard method modified the reward with a Kullback-Lieber (KL) penalty between the online and initial model. We propose Elastic Reset, a new algorithm that achieves higher reward with less drift without explicitly modifying the training objective. We periodically reset the online model to an exponentially moving average (EMA) of itself, then reset the EMA model to the initial model. Through the use of an EMA, our model recovers quickly after resets and achieves higher reward with less drift in the same number of steps. We demonstrate that fine-tuning language models with Elastic Reset leads to state-of-the-art performance on a small scale pivot-translation benchmark, outperforms all baselines in a medium-scale RLHF-like IMDB mock sentiment task and leads to a more performant and more aligned technical QA chatbot with LLaMA-7B. Code available at github.com/mnoukhov/elastic-reset.
Improving Compositional Generalization Using Iterated Learning and Simplicial Embeddings
Oct 28, 2023



Compositional generalization, the ability of an agent to generalize to unseen combinations of latent factors, is easy for humans but hard for deep neural networks. A line of research in cognitive science has hypothesized a process, ``iterated learning,'' to help explain how human language developed this ability; the theory rests on simultaneous pressures towards compressibility (when an ignorant agent learns from an informed one) and expressivity (when it uses the representation for downstream tasks). Inspired by this process, we propose to improve the compositional generalization of deep networks by using iterated learning on models with simplicial embeddings, which can approximately discretize representations. This approach is further motivated by an analysis of compositionality based on Kolmogorov complexity. We show that this combination of changes improves compositional generalization over other approaches, demonstrating these improvements both on vision tasks with well-understood latent factors and on real molecular graph prediction tasks where the latent structure is unknown.
A surprisingly simple technique to control the pretraining bias for better transfer: Expand or Narrow your representation
Apr 11, 2023



Self-Supervised Learning (SSL) models rely on a pretext task to learn representations. Because this pretext task differs from the downstream tasks used to evaluate the performance of these models, there is an inherent misalignment or pretraining bias. A commonly used trick in SSL, shown to make deep networks more robust to such bias, is the addition of a small projector (usually a 2 or 3 layer multi-layer perceptron) on top of a backbone network during training. In contrast to previous work that studied the impact of the projector architecture, we here focus on a simpler, yet overlooked lever to control the information in the backbone representation. We show that merely changing its dimensionality -- by changing only the size of the backbone's very last block -- is a remarkably effective technique to mitigate the pretraining bias. It significantly improves downstream transfer performance for both Self-Supervised and Supervised pretrained models.
Simplicial Embeddings in Self-Supervised Learning and Downstream Classification
Apr 01, 2022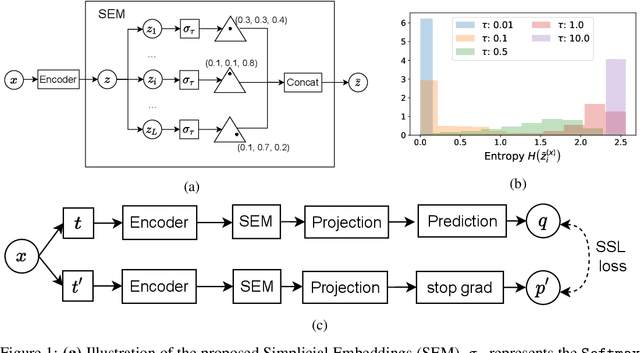

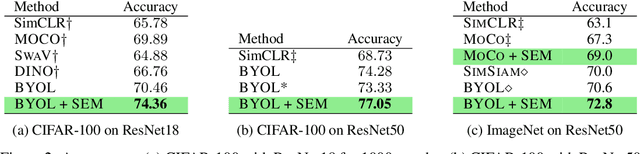
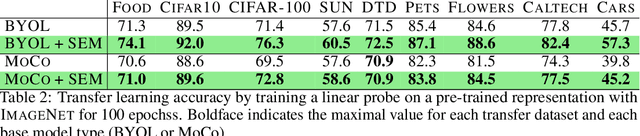
We introduce Simplicial Embeddings (SEMs) as a way to constrain the encoded representations of a self-supervised model to $L$ simplices of $V$ dimensions each using a Softmax operation. This procedure imposes a structure on the representations that reduce their expressivity for training downstream classifiers, which helps them generalize better. Specifically, we show that the temperature $\tau$ of the Softmax operation controls for the SEM representation's expressivity, allowing us to derive a tighter downstream classifier generalization bound than that for classifiers using unnormalized representations. We empirically demonstrate that SEMs considerably improve generalization on natural image datasets such as CIFAR-100 and ImageNet. Finally, we also present evidence of the emergence of semantically relevant features in SEMs, a pattern that is absent from baseline self-supervised models.