 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUDA: Counterfactual Group-wise Training Data Attribution for Diffusion Models via Unlearning
Jan 30, 2026Training-data attribution for vision generative models aims to identify which training data influenced a given output. While most methods score individual examples, practitioners often need group-level answers (e.g., artistic styles or object classes). Group-wise attribution is counterfactual: how would a model's behavior on a generated sample change if a group were absent from training? A natural realization of this counterfactual is Leave-One-Group-Out (LOGO) retraining, which retrains the model with each group removed; however, it becomes computationally prohibitive as the number of groups grows. We propose GUDA (Group Unlearning-based Data Attribution) for diffusion models, which approximates each counterfactual model by applying machine unlearning to a shared full-data model instead of training from scratch. GUDA quantifies group influence using differences in a likelihood-based scoring rule (ELBO) between the full model and each unlearned counterfactual. Experiments on CIFAR-10 and artistic style attribution with Stable Diffusion show that GUDA identifies primary contributing groups more reliably than semantic similarity, gradient-based attribution, and instance-level unlearning approaches, while achieving x100 speedup on CIFAR-10 over LOGO retraining.
Improved Object-Centric Diffusion Learning with Registers and Contrastive Alignment
Jan 03, 2026Slot Attention (SA) with pretrained diffusion models has recently shown promise for object-centric learning (OCL), but suffers from slot entanglement and weak alignment between object slots and image content. We propose Contrastive Object-centric Diffusion Alignment (CODA), a simple extension that (i) employs register slots to absorb residual attention and reduce interference between object slots, and (ii) applies a contrastive alignment loss to explicitly encourage slot-image correspondence. The resulting training objective serves as a tractable surrogate for maximizing mutual information (MI) between slots and inputs, strengthening slot representation quality. On both synthetic (MOVi-C/E) and real-world datasets (VOC, COCO), CODA improves object discovery (e.g., +6.1% FG-ARI on COCO), property prediction, and compositional image generation over strong baselines. Register slots add negligible overhead, keeping CODA efficient and scalable. These results indicate potential applications of CODA as an effective framework for robust OCL in complex, real-world scenes.
SONA: Learning Conditional, Unconditional, and Mismatching-Aware Discriminator
Oct 06, 2025Deep generative models have made significant advances in generating complex content, yet conditional generation remains a fundamental challenge. Existing conditional generative adversarial networks often struggle to balance the dual objectives of assessing authenticity and conditional alignment of input samples within their conditional discriminators. To address this, we propose a novel discriminator design that integrates three key capabilities: unconditional discrimination, matching-aware supervision to enhance alignment sensitivity, and adaptive weighting to dynamically balance all objectives. Specifically, we introduce Sum of Naturalness and Alignment (SONA), which employs separate projections for naturalness (authenticity) and alignment in the final layer with an inductive bias, supported by dedicated objective functions and an adaptive weighting mechanism. Extensive experiments on class-conditional generation tasks show that \ours achieves superior sample quality and conditional alignment compared to state-of-the-art methods. Furthermore, we demonstrate its effectiveness in text-to-image generation, confirming the versatility and robustness of our approach.
Mitigating Embedding Collapse in Diffusion Models for Categorical Data
Oct 18, 2024



Latent diffusion models have enabled continuous-state diffusion models to handle a variety of datasets, including categorical data. However, most methods rely on fixed pretrained embeddings, limiting the benefits of joint training with the diffusion model. While jointly learning the embedding (via reconstruction loss) and the latent diffusion model (via score matching loss) could enhance performance, our analysis shows that end-to-end training risks embedding collapse, degrading generation quality. To address this issue, we introduce CATDM, a continuous diffusion framework within the embedding space that stabilizes training. We propose a novel objective combining the joint embedding-diffusion variational lower bound with a Consistency-Matching (CM) regularizer, alongside a shifted cosine noise schedule and random dropping strategy. The CM regularizer ensures the recovery of the true data distribution. Experiments on benchmarks show that CATDM mitigates embedding collapse, yielding superior results on FFHQ, LSUN Churches, and LSUN Bedrooms. In particular, CATDM achieves an FID of 6.81 on ImageNet $256\times256$ with 50 steps. It outperforms non-autoregressive models in machine translation and is on a par with previous methods in text generation.
SAFT: Towards Out-of-Distribution Generalization in Fine-Tuning
Jul 03, 2024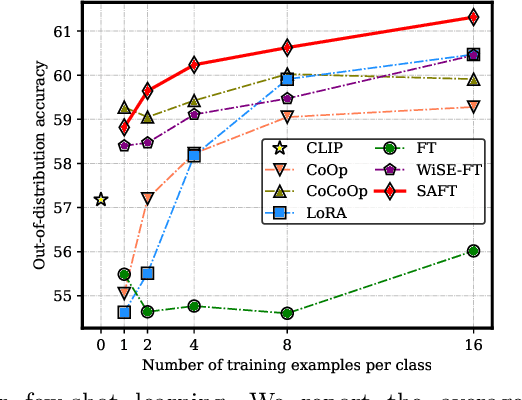
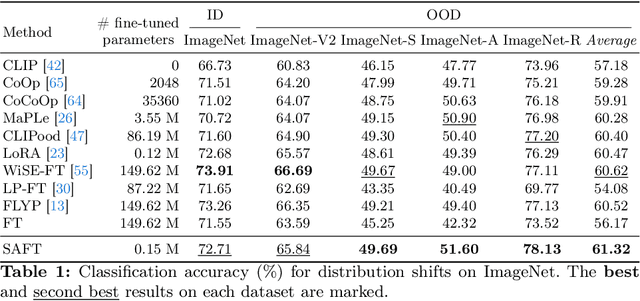
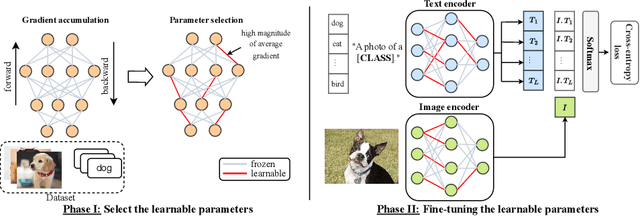
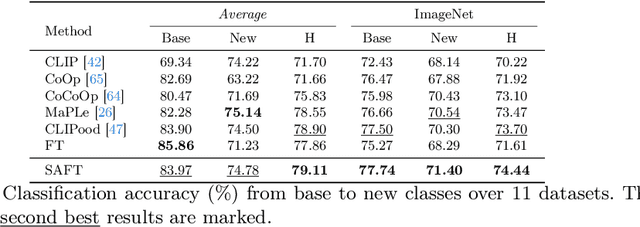
Handling distribution shifts from training data, known as out-of-distribution (OOD) generalization, poses a significant challenge in the field of machine learning. While a pre-trained vision-language model like CLIP has demonstrated remarkable zero-shot performance, further adaptation of the model to downstream tasks leads to undesirable degradation for OOD data. In this work, we introduce Sparse Adaptation for Fine-Tuning (SAFT), a method that prevents fine-tuning from forgetting the general knowledge in the pre-trained model. SAFT only updates a small subset of important parameters whose gradient magnitude is large, while keeping the other parameters frozen. SAFT is straightforward to implement and conceptually simple. Extensive experiments show that with only 0.1% of the model parameters, SAFT can significantly improve the performance of CLIP. It consistently outperforms baseline methods across several benchmarks. On the few-shot learning benchmark of ImageNet and its variants, SAFT gives a gain of 5.15% on average over the conventional fine-tuning method in OOD settings.
SPARO: Selective Attention for Robust and Compositional Transformer Encodings for Vision
Apr 24, 2024



Selective attention helps us focus on task-relevant aspects in the constant flood of our sensory input. This constraint in our perception allows us to robustly generalize under distractions and to new compositions of perceivable concepts. Transformers employ a similar notion of attention in their architecture, but representation learning models with transformer backbones like CLIP and DINO often fail to demonstrate robustness and compositionality. We highlight a missing architectural prior: unlike human perception, transformer encodings do not separately attend over individual concepts. In response, we propose SPARO, a read-out mechanism that partitions encodings into separately-attended slots, each produced by a single attention head. Using SPARO with CLIP imparts an inductive bias that the vision and text modalities are different views of a shared compositional world with the same corresponding concepts. Using SPARO, we demonstrate improvements on downstream recognition, robustness, retrieval, and compositionality benchmarks with CLIP (up to +14% for ImageNet, +4% for SugarCrepe), and on nearest neighbors and linear probe for ImageNet with DINO (+3% each). We also showcase a powerful ability to intervene and select individual SPARO concepts to further improve downstream task performance (up from +4% to +9% for SugarCrepe) and use this ability to study the robustness of SPARO's representation structure. Finally, we provide insights through ablation experiments and visualization of learned concepts.
SKILL: Similarity-aware Knowledge distILLation for Speech Self-Supervised Learning
Feb 26, 2024



Self-supervised learning (SSL) has achieved remarkable success across various speech-processing tasks. To enhance its efficiency, previous works often leverage the use of compression techniques. A notable recent attempt is DPHuBERT, which applies joint knowledge distillation (KD) and structured pruning to learn a significantly smaller SSL model. In this paper, we contribute to this research domain by introducing SKILL, a novel method that conducts distillation across groups of layers instead of distilling individual arbitrarily selected layers within the teacher network. The identification of the layers to distill is achieved through a hierarchical clustering procedure applied to layer similarity measures. Extensive experiments demonstrate that our distilled version of WavLM Base+ not only outperforms DPHuBERT but also achieves state-of-the-art results in the 30M parameters model class across several SUPERB tasks.
Towards Robust FastSpeech 2 by Modelling Residual Multimodality
Jun 02, 2023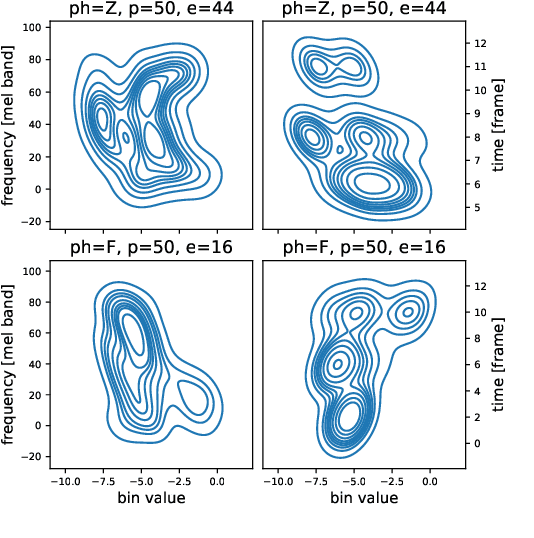
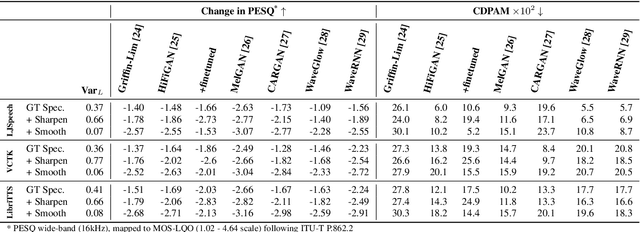
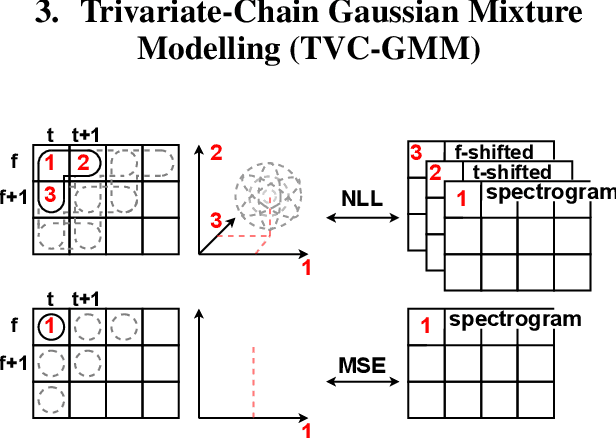
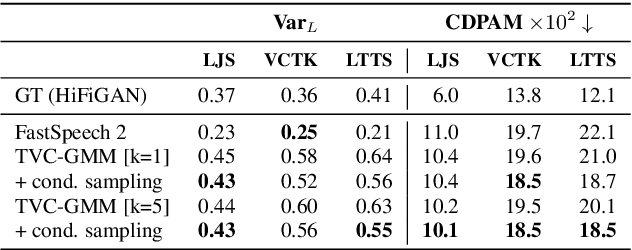
State-of-the-art non-autoregressive text-to-speech (TTS) models based on FastSpeech 2 can efficiently synthesise high-fidelity and natural speech. For expressive speech datasets however, we observe characteristic audio distortions. We demonstrate that such artefacts are introduced to the vocoder reconstruction by over-smooth mel-spectrogram predictions, which are induced by the choice of mean-squared-error (MSE) loss for training the mel-spectrogram decoder. With MSE loss FastSpeech 2 is limited to learn conditional averages of the training distribution, which might not lie close to a natural sample if the distribution still appears multimodal after all conditioning signals. To alleviate this problem, we introduce TVC-GMM, a mixture model of Trivariate-Chain Gaussian distributions, to model the residual multimodality. TVC-GMM reduces spectrogram smoothness and improves perceptual audio quality in particular for expressive datasets as shown by both objective and subjective evaluation.
Efficient Training of Deep Equilibrium Models
Apr 23, 2023Deep equilibrium models (DEQs) have proven to be very powerful for learning data representations. The idea is to replace traditional (explicit) feedforward neural networks with an implicit fixed-point equation, which allows to decouple the forward and backward passes. In particular, training DEQ layers becomes very memory-efficient via the implicit function theorem. However, backpropagation through DEQ layers still requires solving an expensive Jacobian-based equation. In this paper, we introduce a simple but effective strategy to avoid this computational burden. Our method relies on the Jacobian approximation of Broyden's method after the forward pass to compute the gradients during the backward pass. Experiments show that simply re-using this approximation can significantly speed up the training while not causing any performance degradation.
Improving Self-Supervised Learning for Audio Representations by Feature Diversity and Decorrelation
Mar 07, 2023Self-supervised learning (SSL) has recently shown remarkable results in closing the gap between supervised and unsupervised learning. The idea is to learn robust features that are invariant to distortions of the input data. Despite its success, this idea can suffer from a collapsing issue where the network produces a constant representation. To this end, we introduce SELFIE, a novel Self-supervised Learning approach for audio representation via Feature Diversity and Decorrelation. SELFIE avoids the collapsing issue by ensuring that the representation (i) maintains a high diversity among embeddings and (ii) decorrelates the dependencies between dimensions. SELFIE is pre-trained on the large-scale AudioSet dataset and its embeddings are validated on nine audio downstream tasks, including speech, music, and sound event recognition. Experimental results show that SELFIE outperforms existing SSL methods in several tasks.