 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust FastSpeech 2 by Modelling Residual Multimodality
Jun 02, 2023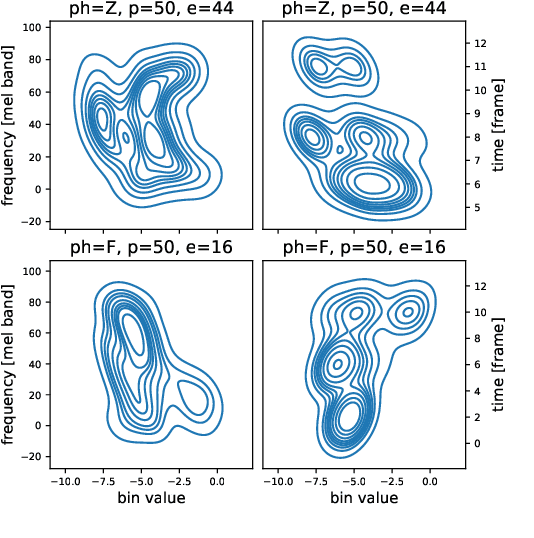
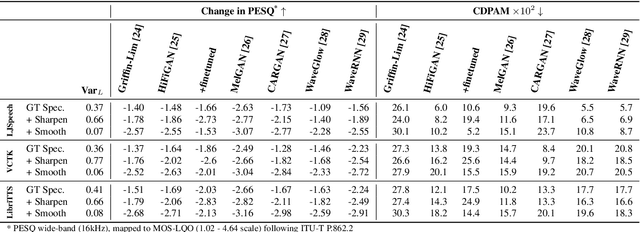
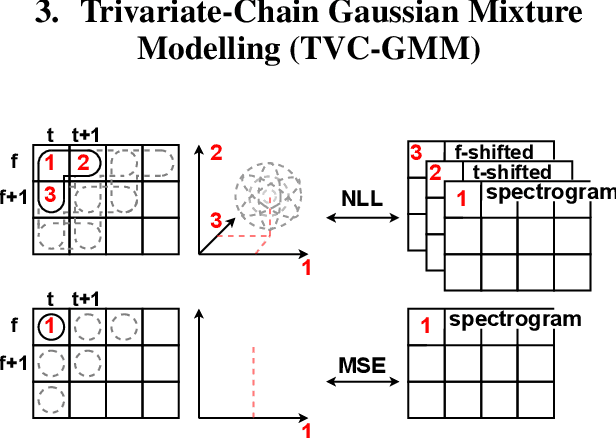
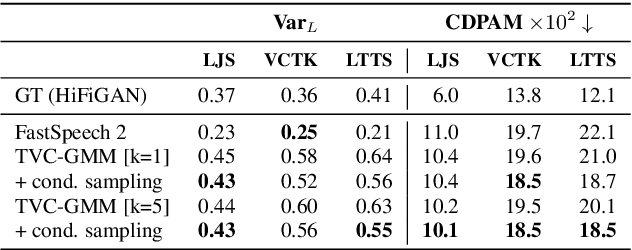
State-of-the-art non-autoregressive text-to-speech (TTS) models based on FastSpeech 2 can efficiently synthesise high-fidelity and natural speech. For expressive speech datasets however, we observe characteristic audio distortions. We demonstrate that such artefacts are introduced to the vocoder reconstruction by over-smooth mel-spectrogram predictions, which are induced by the choice of mean-squared-error (MSE) loss for training the mel-spectrogram decoder. With MSE loss FastSpeech 2 is limited to learn conditional averages of the training distribution, which might not lie close to a natural sample if the distribution still appears multimodal after all conditioning signals. To alleviate this problem, we introduce TVC-GMM, a mixture model of Trivariate-Chain Gaussian distributions, to model the residual multimodality. TVC-GMM reduces spectrogram smoothness and improves perceptual audio quality in particular for expressive datasets as shown by both objective and subjective evaluation.
Multimodal Integration of Human-Like Attention in Visual Question Answering
Sep 27, 2021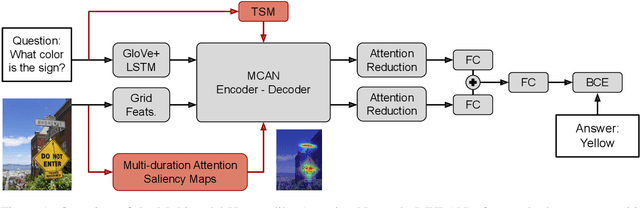
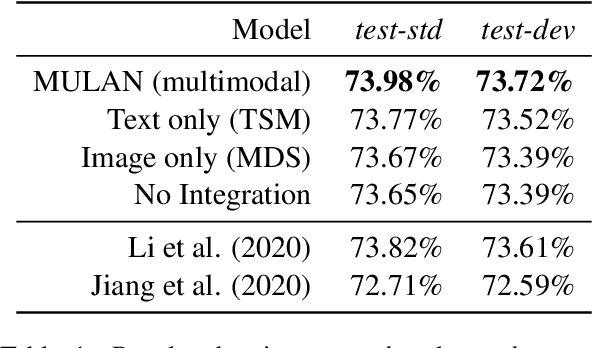
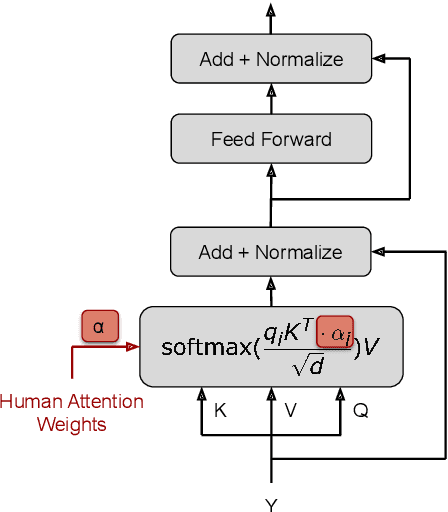
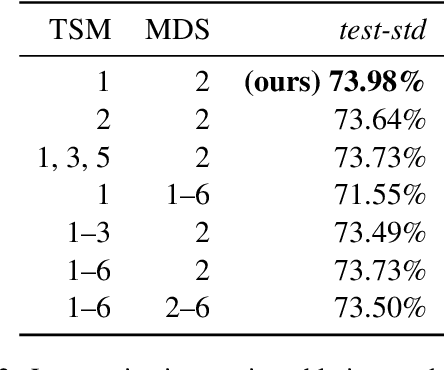
Human-like attention as a supervisory signal to guide neural attention has shown significant promise but is currently limited to uni-modal integration - even for inherently multimodal tasks such as visual question answering (VQA). We present the Multimodal Human-like Attention Network (MULAN) - the first method for multimodal integration of human-like attention on image and text during training of VQA models. MULAN integrates attention predictions from two state-of-the-art text and image saliency models into neural self-attention layers of a recent transformer-based VQA model. Through evaluations on the challenging VQAv2 dataset, we show that MULAN achieves a new state-of-the-art performance of 73.98% accuracy on test-std and 73.72% on test-dev and, at the same time, has approximately 80% fewer trainable parameters than prior work. Overall, our work underlines the potential of integrating multimodal human-like and neural attention for VQA
VQA-MHUG: A Gaze Dataset to Study Multimodal Neural Attention in Visual Question Answering
Sep 27, 2021

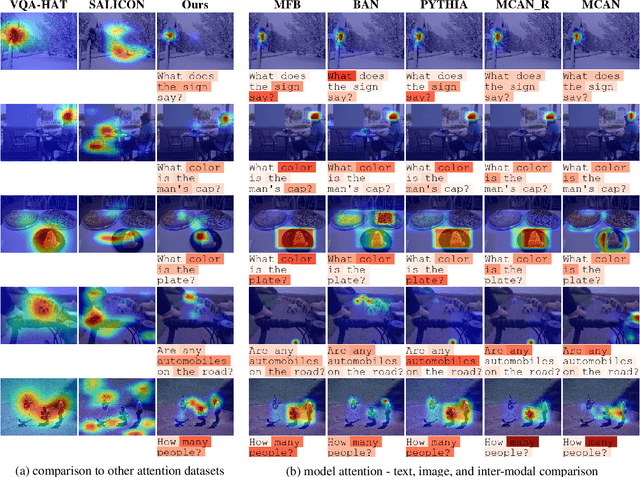
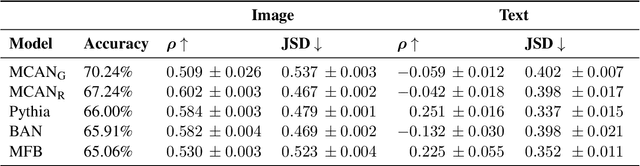
We present VQA-MHUG - a novel 49-participant dataset of multimodal human gaze on both images and questions during visual question answering (VQA) collected using a high-speed eye tracker. We use our dataset to analyze the similarity between human and neural attentive strategies learned by five state-of-the-art VQA models: Modular Co-Attention Network (MCAN) with either grid or region features, Pythia, Bilinear Attention Network (BAN), and the Multimodal Factorized Bilinear Pooling Network (MFB). While prior work has focused on studying the image modality, our analyses show - for the first time - that for all models, higher correlation with human attention on text is a significant predictor of VQA performance. This finding points at a potential for improving VQA performance and, at the same time, calls for further research on neural text attention mechanisms and their integration into architectures for vision and language tasks, including but potentially also beyond VQA.