 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQA-MHUG: A Gaze Dataset to Study Multimodal Neural Attention in Visual Question Answering
Sep 27, 2021

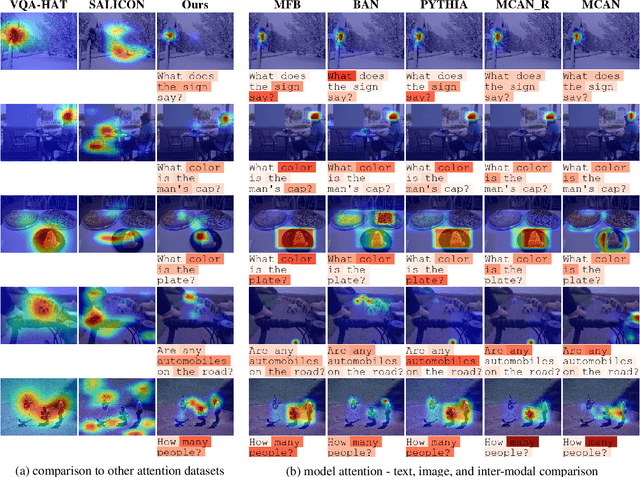
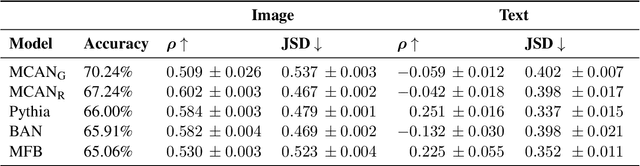
We present VQA-MHUG - a novel 49-participant dataset of multimodal human gaze on both images and questions during visual question answering (VQA) collected using a high-speed eye tracker. We use our dataset to analyze the similarity between human and neural attentive strategies learned by five state-of-the-art VQA models: Modular Co-Attention Network (MCAN) with either grid or region features, Pythia, Bilinear Attention Network (BAN), and the Multimodal Factorized Bilinear Pooling Network (MFB). While prior work has focused on studying the image modality, our analyses show - for the first time - that for all models, higher correlation with human attention on text is a significant predictor of VQA performance. This finding points at a potential for improving VQA performance and, at the same time, calls for further research on neural text attention mechanisms and their integration into architectures for vision and language tasks, including but potentially also beyond VQA.
Understanding Cross-Lingual Syntactic Transfer in Multilingual Recurrent Neural Networks
Mar 31, 2020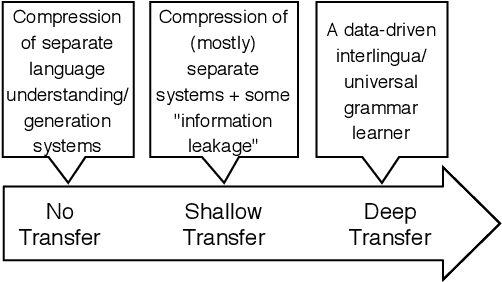
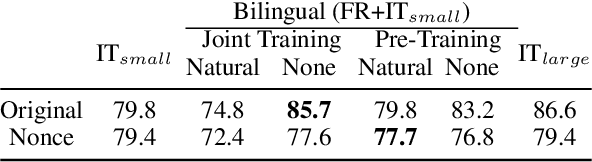
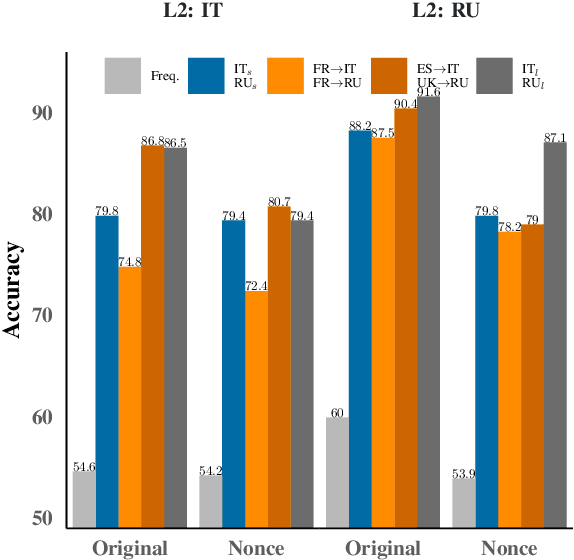
It is now established that modern neural language models can be successfully trained on multiple languages simultaneously without changes to the underlying architecture, providing an easy way to adapt a variety of NLP models to low-resource languages. But what kind of knowledge is really shared among languages within these models? Does multilingual training mostly lead to an alignment of the lexical representation spaces or does it also enable the sharing of purely grammatical knowledge? In this paper we dissect different forms of cross-lingual transfer and look for its most determining factors, using a variety of models and probing tasks. We find that exposing our language models to a related language does not always increase grammatical knowledge in the target language, and that optimal conditions for lexical-semantic transfer may not be optimal for syntactic transfer.
Measuring the compositionality of noun-noun compounds over time
Jun 12, 2019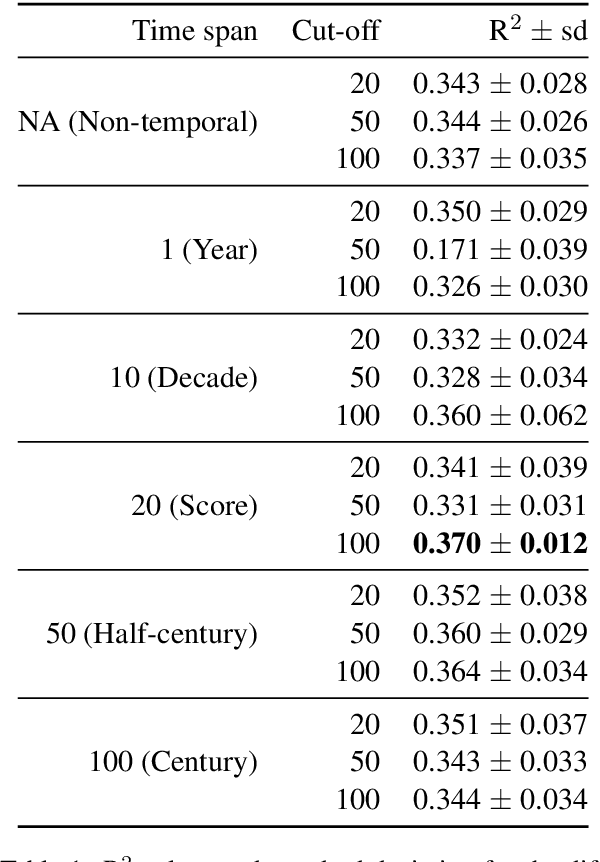
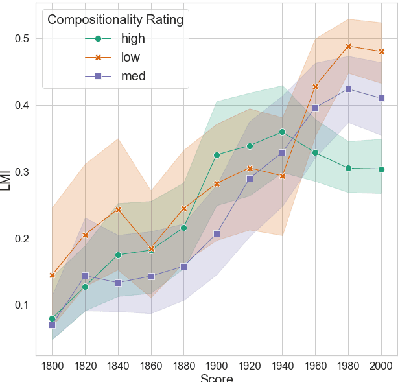
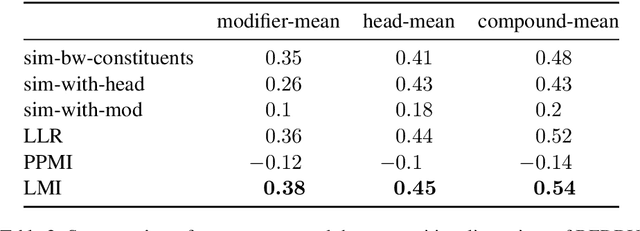
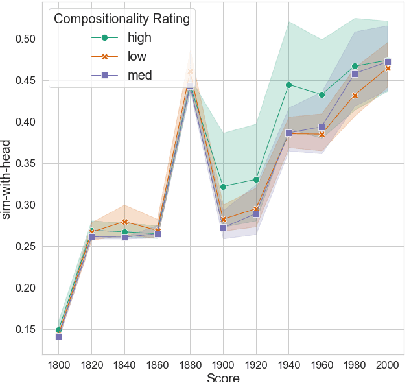
We present work in progress on the temporal progression of compositionality in noun-noun compounds. Previous work has proposed computational methods for determining the compositionality of compounds. These methods try to automatically determine how transparent the meaning of the compound as a whole is with respect to the meaning of its parts. We hypothesize that such a property might change over time. We use the time-stamped Google Books corpus for our diachronic investigations, and first examine whether the vector-based semantic spaces extracted from this corpus are able to predict compositionality ratings, despite their inherent limitations. We find that using temporal information helps predicting the ratings, although correlation with the ratings is lower than reported for other corpora. Finally, we show changes in compositionality over time for a selection of compounds.
Learning to Predict Novel Noun-Noun Compounds
Jun 09, 2019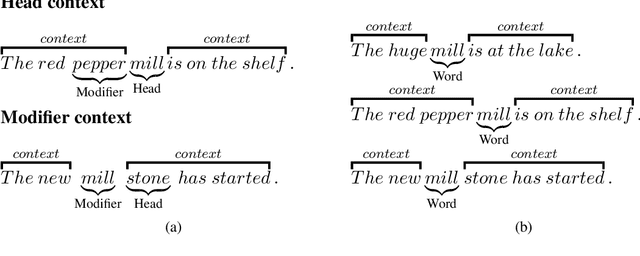

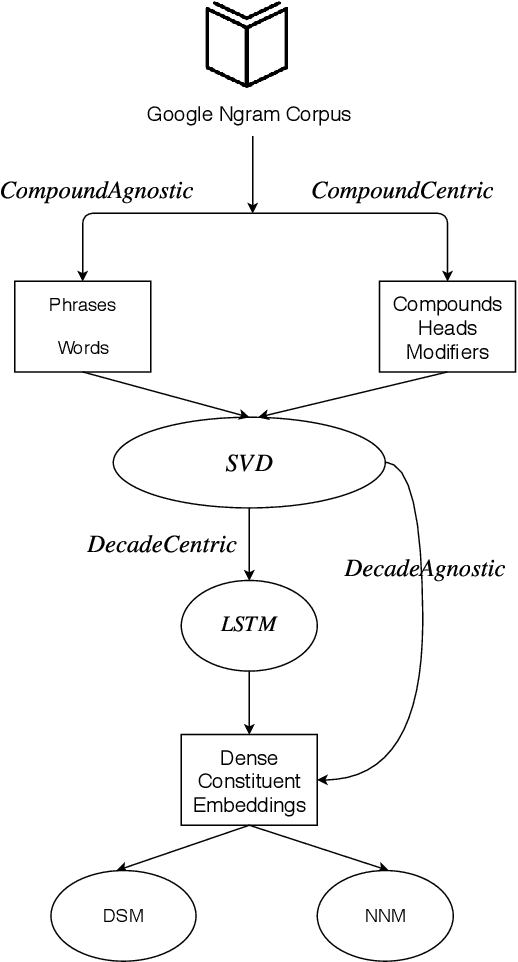

We introduce temporally and contextually-aware models for the novel task of predicting unseen but plausible concepts, as conveyed by noun-noun compounds in a time-stamped corpus. We train compositional models on observed compounds, more specifically the composed distributed representations of their constituents across a time-stamped corpus, while giving it corrupted instances (where head or modifier are replaced by a random constituent) as negative evidence. The model captures generalisations over this data and learns what combinations give rise to plausible compounds and which ones do not. After training, we query the model for the plausibility of automatically generated novel combinations and verify whether the classifications are accurate. For our best model, we find that in around 85% of the cases, the novel compounds generated are attested in previously unseen data. An additional estimated 5% are plausible despite not being attested in the recent corpus, based on judgments from independent human raters.